 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Bandits for Maximizing Stimulated Word-of-Mouth Rewards
Jun 13, 2026Stimulated word-of-mouth is a strategy that promotes information sharing through prompts or incentives. Optimizing stimulated word-of-mouth through social networks requires identifying and targeting connected users who are most susceptible to spillover, a phenomenon where the influence of recommendations extends beyond the immediate audience to impact their connected users. The probability of spillover varies across individuals, and their connections, leading to heterogeneity. Understanding and accurately estimating the spillover probabilities among users in social networks is crucial for improving the effectiveness of stimulated word-of-mouth. To address this, we present a novel contextual multi-armed bandit framework that learns individual spillover probabilities and ranks connected users to maximize rewards from stimulated word-of-mouth. Experiments on real-world network datasets demonstrate that accounting for spillover heterogeneity enhances the targeting precision of top-$k$ connected users, boosting rewards and outperforming baseline methods that do not learn individual spillover effects.
Learning Peer Influence Probabilities with Linear Contextual Bandits
Oct 21, 2025In networked environments, users frequently share recommendations about content, products, services, and courses of action with others. The extent to which such recommendations are successful and adopted is highly contextual, dependent on the characteristics of the sender, recipient, their relationship, the recommended item, and the medium, which makes peer influence probabilities highly heterogeneous. Accurate estimation of these probabilities is key to understanding information diffusion processes and to improving the effectiveness of viral marketing strategies. However, learning these probabilities from data is challenging; static data may capture correlations between peer recommendations and peer actions but fails to reveal influence relationships. Online learning algorithms can learn these probabilities from interventions but either waste resources by learning from random exploration or optimize for rewards, thus favoring exploration of the space with higher influence probabilities. In this work, we study learning peer influence probabilities under a contextual linear bandit framework. We show that a fundamental trade-off can arise between regret minimization and estimation error, characterize all achievable rate pairs, and propose an uncertainty-guided exploration algorithm that, by tuning a parameter, attains any pair within this trade-off. Our experiments on semi-synthetic network datasets show the advantages of our method over static methods and contextual bandits that ignore this trade-off.
Relational Causal Discovery with Latent Confounders
Jul 02, 2025Estimating causal effects from real-world relational data can be challenging when the underlying causal model and potential confounders are unknown. While several causal discovery algorithms exist for learning causal models with latent confounders from data, they assume that the data is independent and identically distributed (i.i.d.) and are not well-suited for learning from relational data. Similarly, existing relational causal discovery algorithms assume causal sufficiency, which is unrealistic for many real-world datasets. To address this gap, we propose RelFCI, a sound and complete causal discovery algorithm for relational data with latent confounders. Our work builds upon the Fast Causal Inference (FCI) and Relational Causal Discovery (RCD) algorithms and it defines new graphical models, necessary to support causal discovery in relational domains. We also establish soundness and completeness guarantees for relational d-separation with latent confounders. We present experimental results demonstrating the effectiveness of RelFCI in identifying the correct causal structure in relational causal models with latent confounders.
Correcting for Position Bias in Learning to Rank: A Control Function Approach
Jun 08, 2025
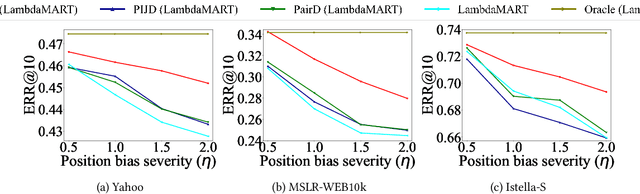
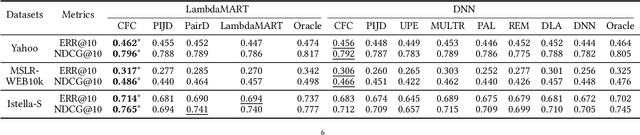
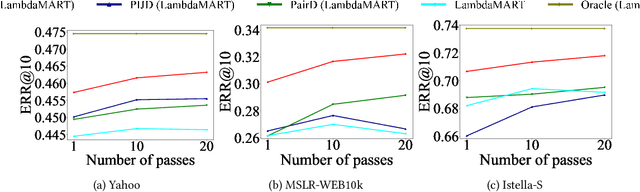
Implicit feedback data, such as user clicks, is commonly used in learning-to-rank (LTR) systems because it is easy to collect and it often reflects user preferences. However, this data is prone to various biases, and training an LTR system directly on biased data can result in suboptimal ranking performance. One of the most prominent and well-studied biases in implicit feedback data is position bias, which occurs because users are more likely to interact with higher-ranked documents regardless of their true relevance. In this paper, we propose a novel control function-based method that accounts for position bias in a two-stage process. The first stage uses exogenous variation from the residuals of the ranking process to correct for position bias in the second stage click equation. Unlike previous position bias correction methods, our method does not require knowledge of the click or propensity model and allows for nonlinearity in the underlying ranking model. Moreover, our method is general and allows for debiasing any state-of-the-art ranking algorithm by plugging it into the second stage. We also introduce a technique to debias validation clicks for hyperparameter tuning to select the optimal model in the absence of unbiased validation data. Experimental results demonstrate that our method outperforms state-of-the-art approaches in correcting for position bias.
Estimating Causal Effects in Networks with Cluster-Based Bandits
May 07, 2025The gold standard for estimating causal effects is randomized controlled trial (RCT) or A/B testing where a random group of individuals from a population of interest are given treatment and the outcome is compared to a random group of individuals from the same population. However, A/B testing is challenging in the presence of interference, commonly occurring in social networks, where individuals can impact each others outcome. Moreover, A/B testing can incur a high performance loss when one of the treatment arms has a poor performance and the test continues to treat individuals with it. Therefore, it is important to design a strategy that can adapt over time and efficiently learn the total treatment effect in the network. We introduce two cluster-based multi-armed bandit (MAB) algorithms to gradually estimate the total treatment effect in a network while maximizing the expected reward by making a tradeoff between exploration and exploitation. We compare the performance of our MAB algorithms with a vanilla MAB algorithm that ignores clusters and the corresponding RCT methods on semi-synthetic data with simulated interference. The vanilla MAB algorithm shows higher reward-action ratio at the cost of higher treatment effect error due to undesired spillover. The cluster-based MAB algorithms show higher reward-action ratio compared to their corresponding RCT methods without sacrificing much accuracy in treatment effect estimation.
Heterogeneous Causal Discovery of Repeated Undesirable Health Outcomes
Mar 14, 2025



Understanding factors triggering or preventing undesirable health outcomes across patient subpopulations is essential for designing targeted interventions. While randomized controlled trials and expert-led patient interviews are standard methods for identifying these factors, they can be time-consuming and infeasible. Causal discovery offers an alternative to conventional approaches by generating cause-and-effect hypotheses from observational data. However, it often relies on strong or untestable assumptions, which can limit its practical application. This work aims to make causal discovery more practical by considering multiple assumptions and identifying heterogeneous effects. We formulate the problem of discovering causes and effect modifiers of an outcome, where effect modifiers are contexts (e.g., age groups) with heterogeneous causal effects. Then, we present a novel, end-to-end framework that incorporates an ensemble of causal discovery algorithms and estimation of heterogeneous effects to discover causes and effect modifiers that trigger or inhibit the outcome. We demonstrate that the ensemble approach improves robustness by enhancing recall of causal factors while maintaining precision. Our study examines the causes of repeat emergency room visits for diabetic patients and hospital readmissions for ICU patients. Our framework generates causal hypotheses consistent with existing literature and can help practitioners identify potential interventions and patient subpopulations to focus on.
Learning Exposure Mapping Functions for Inferring Heterogeneous Peer Effects
Mar 03, 2025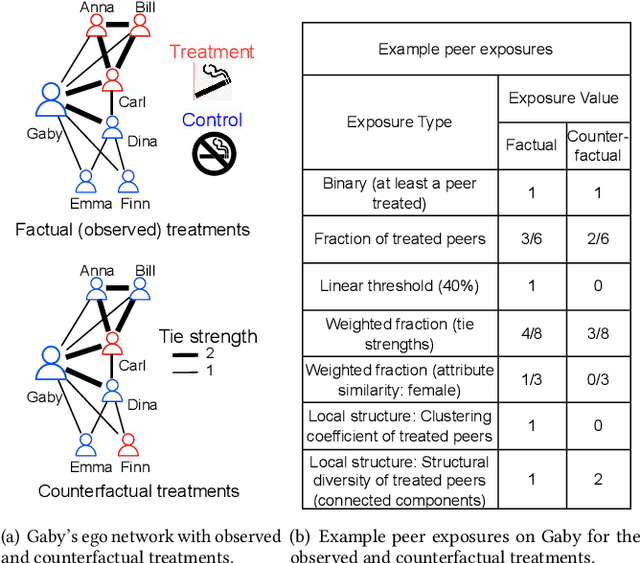
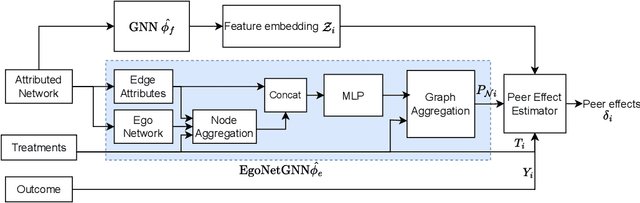
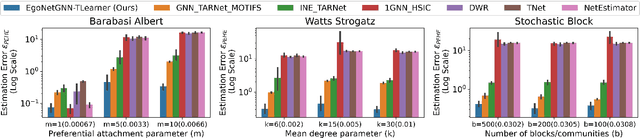
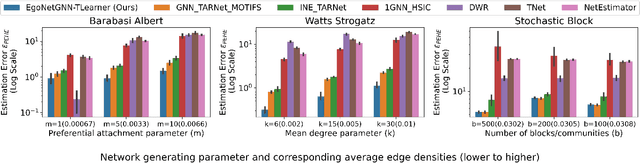
In causal inference, interference refers to the phenomenon in which the actions of peers in a network can influence an individual's outcome. Peer effect refers to the difference in counterfactual outcomes of an individual for different levels of peer exposure, the extent to which an individual is exposed to the treatments, actions, or behaviors of peers. Estimating peer effects requires deciding how to represent peer exposure. Typically, researchers define an exposure mapping function that aggregates peer treatments and outputs peer exposure. Most existing approaches for defining exposure mapping functions assume peer exposure based on the number or fraction of treated peers. Recent studies have investigated more complex functions of peer exposure which capture that different peers can exert different degrees of influence. However, none of these works have explicitly considered the problem of automatically learning the exposure mapping function. In this work, we focus on learning this function for the purpose of estimating heterogeneous peer effects, where heterogeneity refers to the variation in counterfactual outcomes for the same peer exposure but different individual's contexts. We develop EgoNetGNN, a graph neural network (GNN)-based method, to automatically learn the appropriate exposure mapping function allowing for complex peer influence mechanisms that, in addition to peer treatments, can involve the local neighborhood structure and edge attributes. We show that GNN models that use peer exposure based on the number or fraction of treated peers or learn peer exposure naively face difficulty accounting for such influence mechanisms. Our comprehensive evaluation on synthetic and semi-synthetic network data shows that our method is more robust to different unknown underlying influence mechanisms when estimating heterogeneous peer effects when compared to state-of-the-art baselines.
See Me and Believe Me: Causality and Intersectionality in Testimonial Injustice in Healthcare
Oct 02, 2024In medical settings, it is critical that all who are in need of care are correctly heard and understood. When this is not the case due to prejudices a listener has, the speaker is experiencing \emph{testimonial injustice}, which, building upon recent work, we quantify by the presence of several categories of unjust vocabulary in medical notes. In this paper, we use FCI, a causal discovery method, to study the degree to which certain demographic features could lead to marginalization (e.g., age, gender, and race) by way of contributing to testimonial injustice. To achieve this, we review physicians' notes for each patient, where we identify occurrences of unjust vocabulary, along with the demographic features present, and use causal discovery to build a Structural Causal Model (SCM) relating those demographic features to testimonial injustice. We analyze and discuss the resulting SCMs to show the interaction of these factors and how they influence the experience of injustice. Despite the potential presence of some confounding variables, we observe how one contributing feature can make a person more prone to experiencing another contributor of testimonial injustice. There is no single root of injustice and thus intersectionality cannot be ignored. These results call for considering more than singular or equalized attributes of who a person is when analyzing and improving their experiences of bias and injustice. This work is thus a first foray at using causal discovery to understand the nuanced experiences of patients in medical settings, and its insights could be used to guide design principles throughout healthcare, to build trust and promote better patient care.
Cascade-based Randomization for Inferring Causal Effects under Diffusion Interference
May 20, 2024The presence of interference, where the outcome of an individual may depend on the treatment assignment and behavior of neighboring nodes, can lead to biased causal effect estimation. Current approaches to network experiment design focus on limiting interference through cluster-based randomization, in which clusters are identified using graph clustering, and cluster randomization dictates the node assignment to treatment and control. However, cluster-based randomization approaches perform poorly when interference propagates in cascades, whereby the response of individuals to treatment propagates to their multi-hop neighbors. When we have knowledge of the cascade seed nodes, we can leverage this interference structure to mitigate the resulting causal effect estimation bias. With this goal, we propose a cascade-based network experiment design that initiates treatment assignment from the cascade seed node and propagates the assignment to their multi-hop neighbors to limit interference during cascade growth and thereby reduce the overall causal effect estimation error. Our extensive experiments on real-world and synthetic datasets demonstrate that our proposed framework outperforms the existing state-of-the-art approaches in estimating causal effects in network data.
Bridging or Breaking: Impact of Intergroup Interactions on Religious Polarization
Feb 20, 2024While exposure to diverse viewpoints may reduce polarization, it can also have a backfire effect and exacerbate polarization when the discussion is adversarial. Here, we examine the question whether intergroup interactions around important events affect polarization between majority and minority groups in social networks. We compile data on the religious identity of nearly 700,000 Indian Twitter users engaging in COVID-19-related discourse during 2020. We introduce a new measure for an individual's group conformity based on contextualized embeddings of tweet text, which helps us assess polarization between religious groups. We then use a meta-learning framework to examine heterogeneous treatment effects of intergroup interactions on an individual's group conformity in the light of communal, political, and socio-economic events. We find that for political and social events, intergroup interactions reduce polarization. This decline is weaker for individuals at the extreme who already exhibit high conformity to their group. In contrast, during communal events, intergroup interactions can increase group conformity. Finally, we decompose the differential effects across religious groups in terms of emotions and topics of discussion. The results show that the dynamics of religious polarization are sensitive to the context and have important implications for understanding the role of intergroup interactions.