 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascade-based Randomization for Inferring Causal Effects under Diffusion Interference
May 20, 2024The presence of interference, where the outcome of an individual may depend on the treatment assignment and behavior of neighboring nodes, can lead to biased causal effect estimation. Current approaches to network experiment design focus on limiting interference through cluster-based randomization, in which clusters are identified using graph clustering, and cluster randomization dictates the node assignment to treatment and control. However, cluster-based randomization approaches perform poorly when interference propagates in cascades, whereby the response of individuals to treatment propagates to their multi-hop neighbors. When we have knowledge of the cascade seed nodes, we can leverage this interference structure to mitigate the resulting causal effect estimation bias. With this goal, we propose a cascade-based network experiment design that initiates treatment assignment from the cascade seed node and propagates the assignment to their multi-hop neighbors to limit interference during cascade growth and thereby reduce the overall causal effect estimation error. Our extensive experiments on real-world and synthetic datasets demonstrate that our proposed framework outperforms the existing state-of-the-art approaches in estimating causal effects in network data.
Mitigating Cold-start Forecasting using Cold Causal Demand Forecasting Model
Jun 15, 2023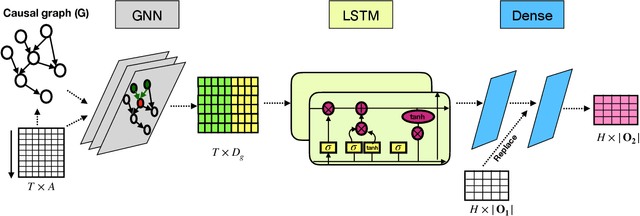
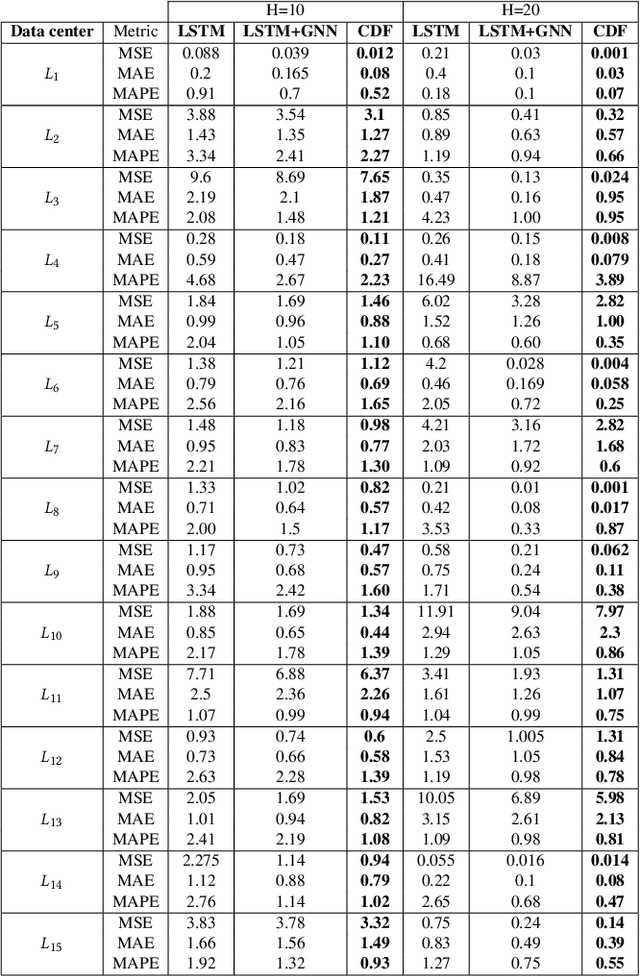
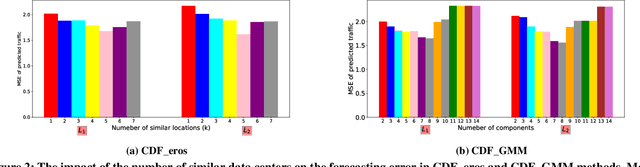

Forecasting multivariate time series data, which involves predicting future values of variables over time using historical data, has significant practical applications. Although deep learning-based models have shown promise in this field, they often fail to capture the causal relationship between dependent variables, leading to less accurate forecasts. Additionally, these models cannot handle the cold-start problem in time series data, where certain variables lack historical data, posing challenges in identifying dependencies among variables. To address these limitations, we introduce the Cold Causal Demand Forecasting (CDF-cold) framework that integrates causal inference with deep learning-based models to enhance the forecasting accuracy of multivariate time series data affected by the cold-start problem. To validate the effectiveness of the proposed approach, we collect 15 multivariate time-series datasets containing the network traffic of different Google data centers. Our experiments demonstrate that the CDF-cold framework outperforms state-of-the-art forecasting models in predicting future values of multivariate time series data.
Contagion Effect Estimation Using Proximal Embeddings
Jun 04, 2023
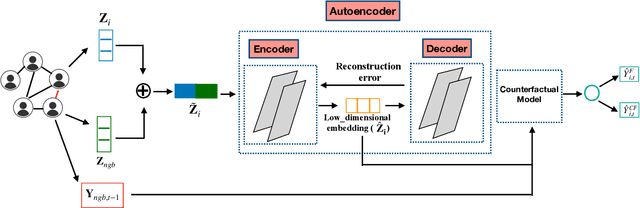
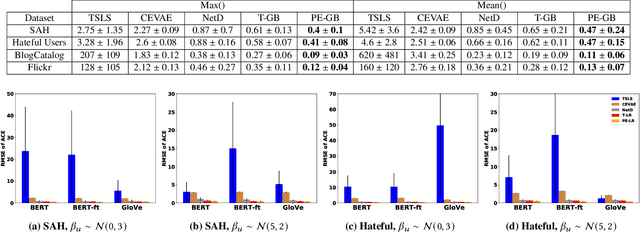

Contagion effect refers to the causal effect of peers' behavior on the outcome of an individual in social networks. While prominent methods for estimating contagion effects in observational studies often assume that there are no unmeasured confounders, contagion can be confounded due to latent homophily: nodes in a homophilous network tend to have ties to peers with similar attributes and can behave similarly without influencing one another. One way to account for latent homophily is by considering proxies for the unobserved confounders. However, in the presence of high-dimensional proxies, proxy-based methods can lead to substantially biased estimation of contagion effects, as we demonstrate in this paper. To tackle this issue, we introduce the novel Proximal Embeddings (ProEmb), a framework which integrates Variational Autoencoders (VAEs) and adversarial networks to generate balanced low-dimensional representations of high-dimensional proxies for different treatment groups and identifies contagion effects in the presence of unobserved network confounders. We empirically show that our method significantly increases the accuracy of contagion effect estimation in observational network data compared to state-of-the-art methods.
Non-Parametric Inference of Relational Dependence
Jun 30, 2022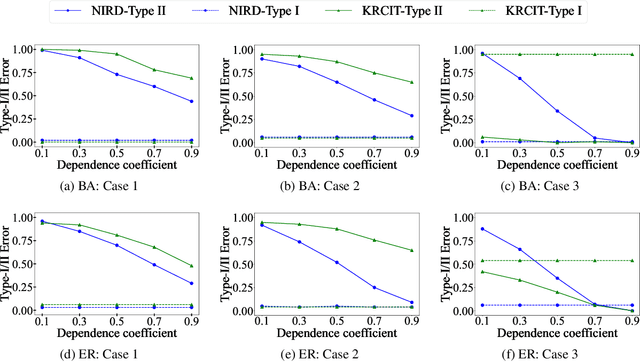
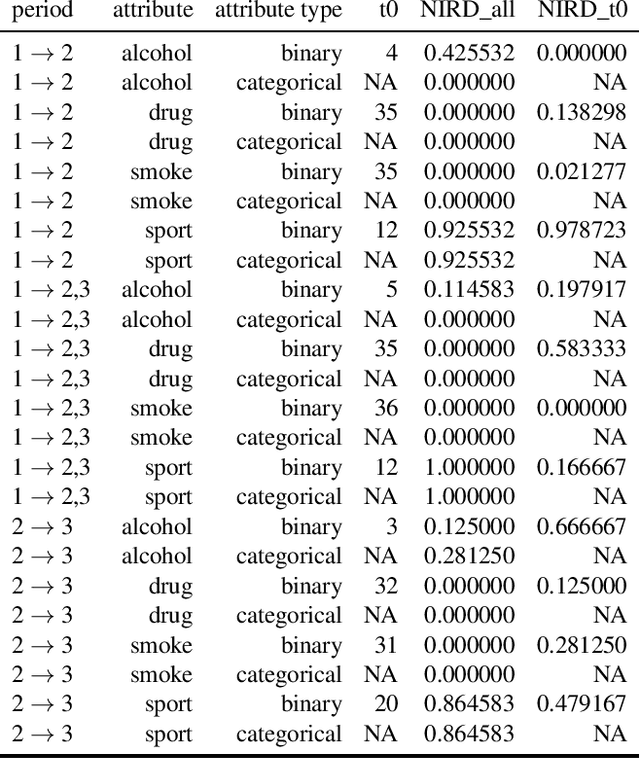
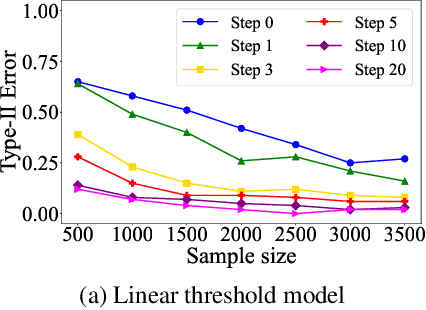
Independence testing plays a central role in statistical and causal inference from observational data. Standard independence tests assume that the data samples are independent and identically distributed (i.i.d.) but that assumption is violated in many real-world datasets and applications centered on relational systems. This work examines the problem of estimating independence in data drawn from relational systems by defining sufficient representations for the sets of observations influencing individual instances. Specifically, we define marginal and conditional independence tests for relational data by considering the kernel mean embedding as a flexible aggregation function for relational variables. We propose a consistent, non-parametric, scalable kernel test to operationalize the relational independence test for non-i.i.d. observational data under a set of structural assumptions. We empirically evaluate our proposed method on a variety of synthetic and semi-synthetic networks and demonstrate its effectiveness compared to state-of-the-art kernel-based independence tests.
Improving Gender Fairness of Pre-Trained Language Models without Catastrophic Forgetting
Oct 11, 2021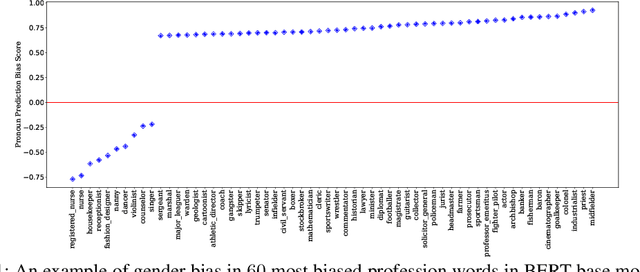

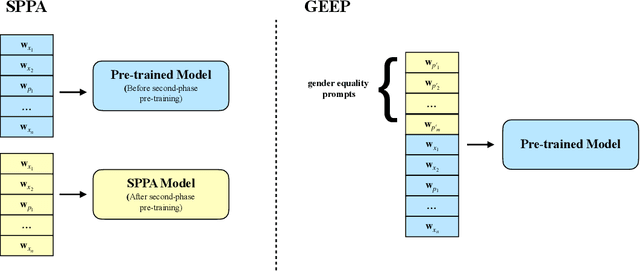
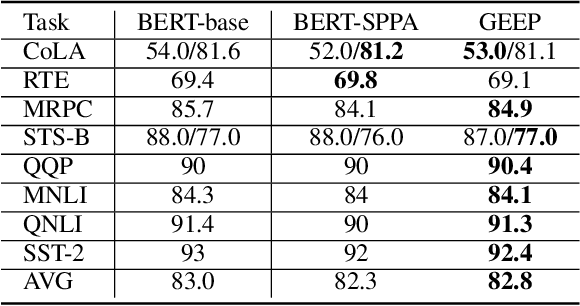
Although pre-trained language models, such as BERT, achieve state-of-art performance in many language understanding tasks, they have been demonstrated to inherit strong gender bias from its training data. Existing studies addressing the gender bias issue of pre-trained models, usually recollect and build gender-neutral data on their own and conduct a second phase pre-training on the released pre-trained model with such data. However, given the limited size of the gender-neutral data and its potential distributional mismatch with the original pre-training data, catastrophic forgetting would occur during the second-phase pre-training. Forgetting on the original training data may damage the model's downstream performance to a large margin. In this work, we first empirically show that even if the gender-neutral data for second-phase pre-training comes from the original training data, catastrophic forgetting still occurs if the size of gender-neutral data is smaller than that of original training data. Then, we propose a new method, GEnder Equality Prompt (GEEP), to improve gender fairness of pre-trained models without forgetting. GEEP learns gender-related prompts to reduce gender bias, conditioned on frozen language models. Since all pre-trained parameters are frozen, forgetting on information from the original training data can be alleviated to the most extent. Then GEEP trains new embeddings of profession names as gender equality prompts conditioned on the frozen model. Empirical results show that GEEP not only achieves state-of-the-art performances on gender debiasing in various applications such as pronoun predicting and coreference resolution, but also achieves comparable results on general downstream tasks such as GLUE with original pre-trained models without much forgetting.
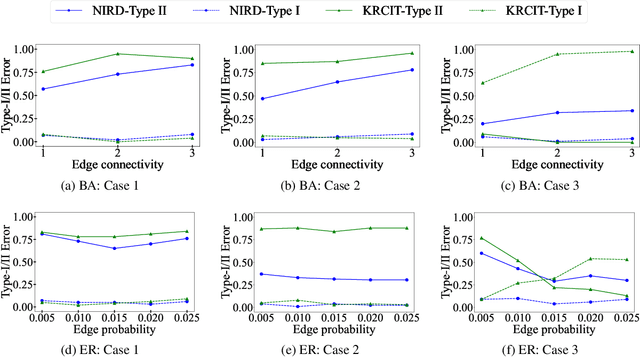
Minimizing Interference and Selection Bias in Network Experiment Design
Apr 15, 2020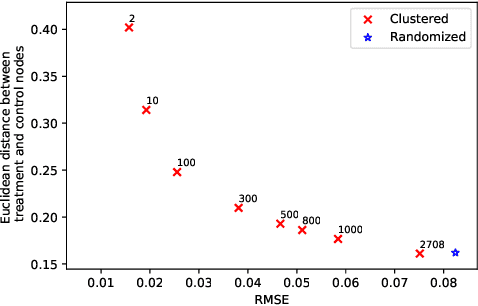
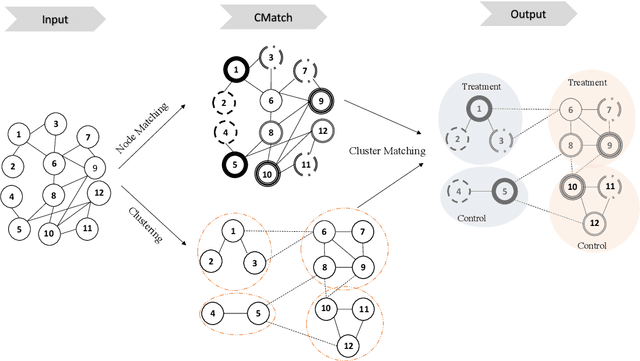
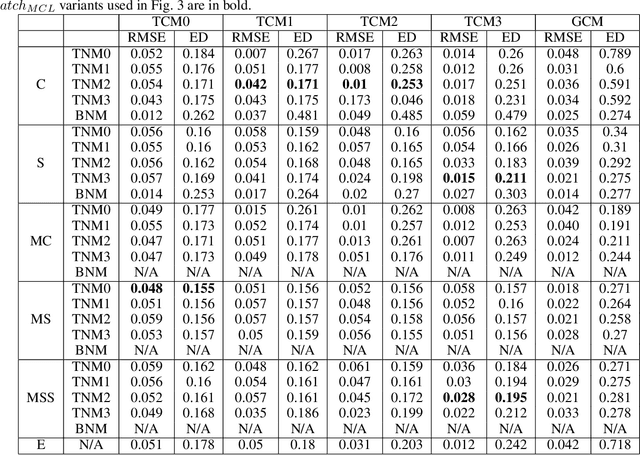
Current approaches to A/B testing in networks focus on limiting interference, the concern that treatment effects can "spill over" from treatment nodes to control nodes and lead to biased causal effect estimation. Prominent methods for network experiment design rely on two-stage randomization, in which sparsely-connected clusters are identified and cluster randomization dictates the node assignment to treatment and control. Here, we show that cluster randomization does not ensure sufficient node randomization and it can lead to selection bias in which treatment and control nodes represent different populations of users. To address this problem, we propose a principled framework for network experiment design which jointly minimizes interference and selection bias. We introduce the concepts of edge spillover probability and cluster matching and demonstrate their importance for designing network A/B testing. Our experiments on a number of real-world datasets show that our proposed framework leads to significantly lower error in causal effect estimation than existing solutions.