 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Gender Fairness of Pre-Trained Language Models without Catastrophic Forgetting
Paper and Code
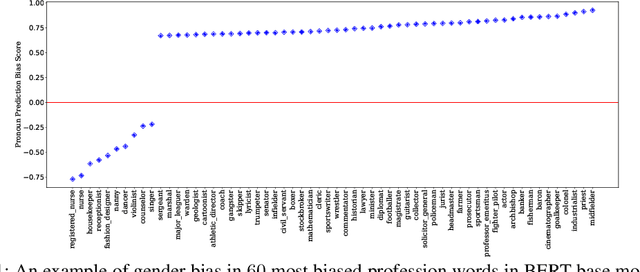

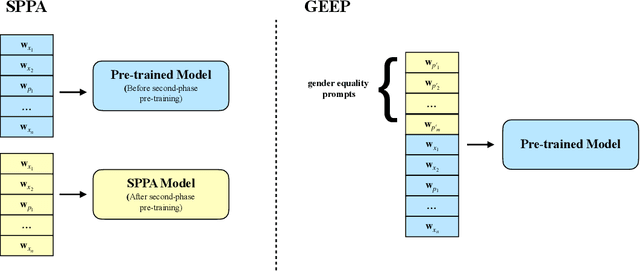
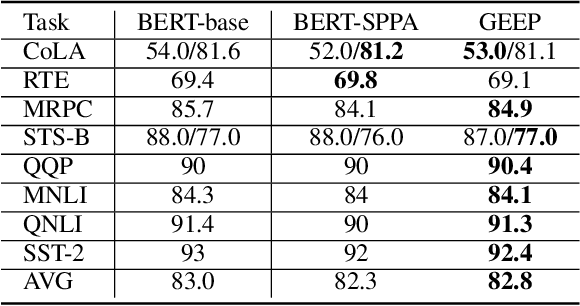
Although pre-trained language models, such as BERT, achieve state-of-art performance in many language understanding tasks, they have been demonstrated to inherit strong gender bias from its training data. Existing studies addressing the gender bias issue of pre-trained models, usually recollect and build gender-neutral data on their own and conduct a second phase pre-training on the released pre-trained model with such data. However, given the limited size of the gender-neutral data and its potential distributional mismatch with the original pre-training data, catastrophic forgetting would occur during the second-phase pre-training. Forgetting on the original training data may damage the model's downstream performance to a large margin. In this work, we first empirically show that even if the gender-neutral data for second-phase pre-training comes from the original training data, catastrophic forgetting still occurs if the size of gender-neutral data is smaller than that of original training data. Then, we propose a new method, GEnder Equality Prompt (GEEP), to improve gender fairness of pre-trained models without forgetting. GEEP learns gender-related prompts to reduce gender bias, conditioned on frozen language models. Since all pre-trained parameters are frozen, forgetting on information from the original training data can be alleviated to the most extent. Then GEEP trains new embeddings of profession names as gender equality prompts conditioned on the frozen model. Empirical results show that GEEP not only achieves state-of-the-art performances on gender debiasing in various applications such as pronoun predicting and coreference resolution, but also achieves comparable results on general downstream tasks such as GLUE with original pre-trained models without much forgetting.