 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverfitting and Generalizing with (PAC) Bayesian Prediction in Noisy Binary Classification
Mar 23, 2026We consider a PAC-Bayes type learning rule for binary classification, balancing the training error of a randomized ''posterior'' predictor with its KL divergence to a pre-specified ''prior''. This can be seen as an extension of a modified two-part-code Minimum Description Length (MDL) learning rule, to continuous priors and randomized predictions. With a balancing parameter of $λ=1$ this learning rule recovers an (empirical) Bayes posterior and a modified variant recovers the profile posterior, linking with standard Bayesian prediction (up to the treatment of the single-parameter noise level). However, from a risk-minimization prediction perspective, this Bayesian predictor overfits and can lead to non-vanishing excess loss in the agnostic case. Instead a choice of $λ\gg 1$, which can be seen as using a sample-size-dependent-prior, ensures uniformly vanishing excess loss even in the agnostic case. We precisely characterize the effect of under-regularizing (and over-regularizing) as a function of the balance parameter $λ$, understanding the regimes in which this under-regularization is tempered or catastrophic. This work extends previous work by Zhu and Srebro [2025] that considered only discrete priors to PAC Bayes type learning rules and, through their rigorous Bayesian interpretation, to Bayesian prediction more generally.
Linearization Explains Fine-Tuning in Large Language Models
Feb 09, 2026Parameter-Efficient Fine-Tuning (PEFT) is a popular class of techniques that strive to adapt large models in a scalable and resource-efficient manner. Yet, the mechanisms underlying their training performance and generalization remain underexplored. In this paper, we provide several insights into such fine-tuning through the lens of linearization. Fine-tuned models are often implicitly encouraged to remain close to the pretrained model. By making this explicit, using an Euclidean distance inductive bias in parameter space, we show that fine-tuning dynamics become equivalent to learning with the positive-definite neural tangent kernel (NTK). We specifically analyze how close the fully linear and the linearized fine-tuning optimizations are, based on the strength of the regularization. This allows us to be pragmatic about how good a model linearization is when fine-tuning large language models (LLMs). When linearization is a good model, our findings reveal a strong correlation between the eigenvalue spectrum of the NTK and the performance of model adaptation. Motivated by this, we give spectral perturbation bounds on the NTK induced by the choice of layers selected for fine-tuning. We empirically validate our theory on Low Rank Adaptation (LoRA) on LLMs. These insights not only characterize fine-tuning but also have the potential to enhance PEFT techniques, paving the way to better informed and more nimble adaptation in LLMs.
Tight Bounds on the Binomial CDF, and the Minimum of i.i.d Binomials, in terms of KL-Divergence
Feb 25, 2025We provide finite sample upper and lower bounds on the Binomial tail probability which are a direct application of Sanov's theorem. We then use these to obtain high probability upper and lower bounds on the minimum of i.i.d. Binomial random variables. Both bounds are finite sample, asymptotically tight, and expressed in terms of the KL-divergence.
See Me and Believe Me: Causality and Intersectionality in Testimonial Injustice in Healthcare
Oct 02, 2024In medical settings, it is critical that all who are in need of care are correctly heard and understood. When this is not the case due to prejudices a listener has, the speaker is experiencing \emph{testimonial injustice}, which, building upon recent work, we quantify by the presence of several categories of unjust vocabulary in medical notes. In this paper, we use FCI, a causal discovery method, to study the degree to which certain demographic features could lead to marginalization (e.g., age, gender, and race) by way of contributing to testimonial injustice. To achieve this, we review physicians' notes for each patient, where we identify occurrences of unjust vocabulary, along with the demographic features present, and use causal discovery to build a Structural Causal Model (SCM) relating those demographic features to testimonial injustice. We analyze and discuss the resulting SCMs to show the interaction of these factors and how they influence the experience of injustice. Despite the potential presence of some confounding variables, we observe how one contributing feature can make a person more prone to experiencing another contributor of testimonial injustice. There is no single root of injustice and thus intersectionality cannot be ignored. These results call for considering more than singular or equalized attributes of who a person is when analyzing and improving their experiences of bias and injustice. This work is thus a first foray at using causal discovery to understand the nuanced experiences of patients in medical settings, and its insights could be used to guide design principles throughout healthcare, to build trust and promote better patient care.
Induced Model Matching: How Restricted Models Can Help Larger Ones
Feb 19, 2024



We consider scenarios where a very accurate predictive model using restricted features is available at the time of training of a larger, full-featured, model. This restricted model may be thought of as "side-information", derived either from an auxiliary exhaustive dataset or on the same dataset, by forcing the restriction. How can the restricted model be useful to the full model? We propose an approach for transferring the knowledge of the restricted model to the full model, by aligning the full model's context-restricted performance with that of the restricted model's. We call this methodology Induced Model Matching (IMM) and first illustrate its general applicability by using logistic regression as a toy example. We then explore IMM's use in language modeling, the application that initially inspired it, and where it offers an explicit foundation in contrast to the implicit use of restricted models in techniques such as noising. We demonstrate the methodology on both LSTM and transformer full models, using $N$-grams as restricted models. To further illustrate the potential of the principle whenever it is much cheaper to collect restricted rather than full information, we conclude with a simple RL example where POMDP policies can improve learned MDP policies via IMM.
Fair Learning with Private Demographic Data
Feb 26, 2020

Sensitive attributes such as race are rarely available to learners in real world settings as their collection is often restricted by laws and regulations. We give a scheme that allows individuals to release their sensitive information privately while still allowing any downstream entity to learn non-discriminatory predictors. We show how to adapt non-discriminatory learners to work with privatized protected attributes giving theoretical guarantees on performance. Finally, we highlight how the methodology could apply to learning fair predictors in settings where protected attributes are only available for a subset of the data.
From Fair Decision Making to Social Equality
Dec 07, 2018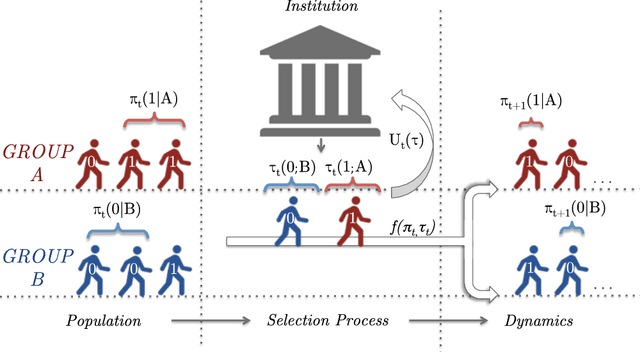


The study of fairness in intelligent decision systems has mostly ignored long-term influence on the underlying population. Yet fairness considerations (e.g. affirmative action) have often the implicit goal of achieving balance among groups within the population. The most basic notion of balance is eventual equality between the qualifications of the groups. How can we incorporate influence dynamics in decision making? How well do dynamics-oblivious fairness policies fare in terms of reaching equality? In this paper, we propose a simple yet revealing model that encompasses (1) a selection process where an institution chooses from multiple groups according to their qualifications so as to maximize an institutional utility and (2) dynamics that govern the evolution of the groups' qualifications according to the imposed policies. We focus on demographic parity as the formalism of affirmative action. We then give conditions under which an unconstrained policy reaches equality on its own. In this case, surprisingly, imposing demographic parity may break equality. When it doesn't, one would expect the additional constraint to reduce utility, however, we show that utility may in fact increase. In more realistic scenarios, unconstrained policies do not lead to equality. In such cases, we show that although imposing demographic parity may remedy it, there is a danger that groups settle at a worse set of qualifications. As a silver lining, we also identify when the constraint not only leads to equality, but also improves all groups. This gives quantifiable insight into both sides of the mismatch hypothesis. These cases and trade-offs are instrumental in determining when and how imposing demographic parity can be beneficial in selection processes, both for the institution and for society on the long run.
Learning Non-Discriminatory Predictors
Nov 01, 2017We consider learning a predictor which is non-discriminatory with respect to a "protected attribute" according to the notion of "equalized odds" proposed by Hardt et al. [2016]. We study the problem of learning such a non-discriminatory predictor from a finite training set, both statistically and computationally. We show that a post-hoc correction approach, as suggested by Hardt et al, can be highly suboptimal, present a nearly-optimal statistical procedure, argue that the associated computational problem is intractable, and suggest a second moment relaxation of the non-discrimination definition for which learning is tractable.
Tradeoffs for Space, Time, Data and Risk in Unsupervised Learning
May 02, 2016
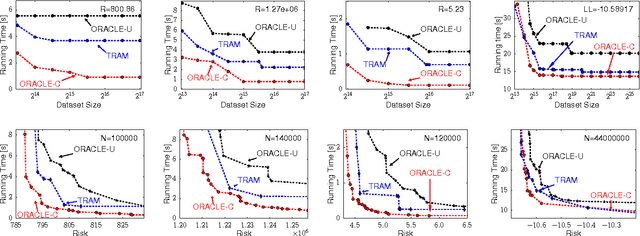
Faced with massive data, is it possible to trade off (statistical) risk, and (computational) space and time? This challenge lies at the heart of large-scale machine learning. Using k-means clustering as a prototypical unsupervised learning problem, we show how we can strategically summarize the data (control space) in order to trade off risk and time when data is generated by a probabilistic model. Our summarization is based on coreset constructions from computational geometry. We also develop an algorithm, TRAM, to navigate the space/time/data/risk tradeoff in practice. In particular, we show that for a fixed risk (or data size), as the data size increases (resp. risk increases) the running time of TRAM decreases. Our extensive experiments on real data sets demonstrate the existence and practical utility of such tradeoffs, not only for k-means but also for Gaussian Mixture Models.
On the Impossibility of Learning the Missing Mass
Mar 12, 2015This paper shows that one cannot learn the probability of rare events without imposing further structural assumptions. The event of interest is that of obtaining an outcome outside the coverage of an i.i.d. sample from a discrete distribution. The probability of this event is referred to as the "missing mass". The impossibility result can then be stated as: the missing mass is not distribution-free PAC-learnable in relative error. The proof is semi-constructive and relies on a coupling argument using a dithered geometric distribution. This result formalizes the folklore that in order to predict rare events, one necessarily needs distributions with "heavy tails".