 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneous Causal Discovery of Repeated Undesirable Health Outcomes
Mar 14, 2025



Understanding factors triggering or preventing undesirable health outcomes across patient subpopulations is essential for designing targeted interventions. While randomized controlled trials and expert-led patient interviews are standard methods for identifying these factors, they can be time-consuming and infeasible. Causal discovery offers an alternative to conventional approaches by generating cause-and-effect hypotheses from observational data. However, it often relies on strong or untestable assumptions, which can limit its practical application. This work aims to make causal discovery more practical by considering multiple assumptions and identifying heterogeneous effects. We formulate the problem of discovering causes and effect modifiers of an outcome, where effect modifiers are contexts (e.g., age groups) with heterogeneous causal effects. Then, we present a novel, end-to-end framework that incorporates an ensemble of causal discovery algorithms and estimation of heterogeneous effects to discover causes and effect modifiers that trigger or inhibit the outcome. We demonstrate that the ensemble approach improves robustness by enhancing recall of causal factors while maintaining precision. Our study examines the causes of repeat emergency room visits for diabetic patients and hospital readmissions for ICU patients. Our framework generates causal hypotheses consistent with existing literature and can help practitioners identify potential interventions and patient subpopulations to focus on.
Self-supervision for health insurance claims data: a Covid-19 use case
Jul 19, 2021


In this work, we modify and apply self-supervision techniques to the domain of medical health insurance claims. We model patients' healthcare claims history analogous to free-text narratives, and introduce pre-trained `prior knowledge', later utilized for patient outcome predictions on a challenging task: predicting Covid-19 hospitalization, given a patient's pre-Covid-19 insurance claims history. Results suggest that pre-training on insurance claims not only produces better prediction performance, but, more importantly, improves the model's `clinical trustworthiness' and model stability/reliability.
Animal Wildlife Population Estimation Using Social Media Images Collections
Aug 07, 2019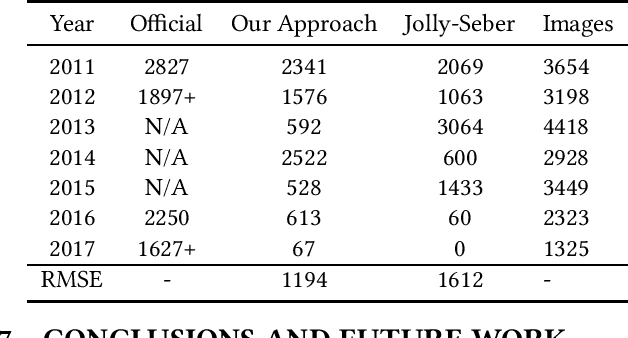
We are losing biodiversity at an unprecedented scale and in many cases, we do not even know the basic data for the species. Traditional methods for wildlife monitoring are inadequate. Development of new computer vision tools enables the use of images as the source of information about wildlife. Social media is the rich source of wildlife images, which come with a huge bias, thus thwarting traditional population size estimate approaches. Here, we present a new framework to take into account the social media bias when using this data source to provide wildlife population size estimates. We show that, surprisingly, this is a learnable and potentially solvable problem.
A Framework For Identifying Group Behavior Of Wild Animals
Jul 01, 2019
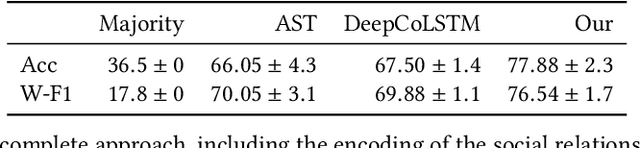
Activity recognition and, more generally, behavior inference tasks are gaining a lot of interest. Much of it is work in the context of human behavior. New available tracking technologies for wild animals are generating datasets that indirectly may provide information about animal behavior. In this work, we propose a method for classifying these data into behavioral annotation, particularly collective behavior of a social group. Our method is based on sequence analysis with a direct encoding of the interactions of a group of wild animals. We evaluate our approach on a real world dataset, showing significant accuracy improvements over baseline methods.