 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA continental-scale dataset of ground beetles with high-resolution images and validated morphological trait measurements
Jan 14, 2026Despite the ecological significance of invertebrates, global trait databases remain heavily biased toward vertebrates and plants, limiting comprehensive ecological analyses of high-diversity groups like ground beetles. Ground beetles (Coleoptera: Carabidae) serve as critical bioindicators of ecosystem health, providing valuable insights into biodiversity shifts driven by environmental changes. While the National Ecological Observatory Network (NEON) maintains an extensive collection of carabid specimens from across the United States, these primarily exist as physical collections, restricting widespread research access and large-scale analysis. To address these gaps, we present a multimodal dataset digitizing over 13,200 NEON carabids from 30 sites spanning the continental US and Hawaii through high-resolution imaging, enabling broader access and computational analysis. The dataset includes digitally measured elytra length and width of each specimen, establishing a foundation for automated trait extraction using AI. Validated against manual measurements, our digital trait extraction achieves sub-millimeter precision, ensuring reliability for ecological and computational studies. By addressing invertebrate under-representation in trait databases, this work supports AI-driven tools for automated species identification and trait-based research, fostering advancements in biodiversity monitoring and conservation.
kabr-tools: Automated Framework for Multi-Species Behavioral Monitoring
Oct 02, 2025A comprehensive understanding of animal behavior ecology depends on scalable approaches to quantify and interpret complex, multidimensional behavioral patterns. Traditional field observations are often limited in scope, time-consuming, and labor-intensive, hindering the assessment of behavioral responses across landscapes. To address this, we present kabr-tools (Kenyan Animal Behavior Recognition Tools), an open-source package for automated multi-species behavioral monitoring. This framework integrates drone-based video with machine learning systems to extract behavioral, social, and spatial metrics from wildlife footage. Our pipeline leverages object detection, tracking, and behavioral classification systems to generate key metrics, including time budgets, behavioral transitions, social interactions, habitat associations, and group composition dynamics. Compared to ground-based methods, drone-based observations significantly improved behavioral granularity, reducing visibility loss by 15% and capturing more transitions with higher accuracy and continuity. We validate kabr-tools through three case studies, analyzing 969 behavioral sequences, surpassing the capacity of traditional methods for data capture and annotation. We found that, like Plains zebras, vigilance in Grevy's zebras decreases with herd size, but, unlike Plains zebras, habitat has a negligible impact. Plains and Grevy's zebras exhibit strong behavioral inertia, with rare transitions to alert behaviors and observed spatial segregation between Grevy's zebras, Plains zebras, and giraffes in mixed-species herds. By enabling automated behavioral monitoring at scale, kabr-tools offers a powerful tool for ecosystem-wide studies, advancing conservation, biodiversity research, and ecological monitoring.
HotSpotter - Patterned Species Instance Recognition
Aug 25, 2025



We present HotSpotter, a fast, accurate algorithm for identifying individual animals against a labeled database. It is not species specific and has been applied to Grevy's and plains zebras, giraffes, leopards, and lionfish. We describe two approaches, both based on extracting and matching keypoints or "hotspots". The first tests each new query image sequentially against each database image, generating a score for each database image in isolation, and ranking the results. The second, building on recent techniques for instance recognition, matches the query image against the database using a fast nearest neighbor search. It uses a competitive scoring mechanism derived from the Local Naive Bayes Nearest Neighbor algorithm recently proposed for category recognition. We demonstrate results on databases of more than 1000 images, producing more accurate matches than published methods and matching each query image in just a few seconds.
* Original matlab code: https://github.com/Erotemic/hotspotter-matlab-2013, Python port: https://github.com/Erotemic/hotspotter
Unsupervised Pelage Pattern Unwrapping for Animal Re-identification
Jun 18, 2025



Existing individual re-identification methods often struggle with the deformable nature of animal fur or skin patterns which undergo geometric distortions due to body movement and posture changes. In this paper, we propose a geometry-aware texture mapping approach that unwarps pelage patterns, the unique markings found on an animal's skin or fur, into a canonical UV space, enabling more robust feature matching. Our method uses surface normal estimation to guide the unwrapping process while preserving the geometric consistency between the 3D surface and the 2D texture space. We focus on two challenging species: Saimaa ringed seals (Pusa hispida saimensis) and leopards (Panthera pardus). Both species have distinctive yet highly deformable fur patterns. By integrating our pattern-preserving UV mapping with existing re-identification techniques, we demonstrate improved accuracy across diverse poses and viewing angles. Our framework does not require ground truth UV annotations and can be trained in a self-supervised manner. Experiments on seal and leopard datasets show up to a 5.4% improvement in re-identification accuracy.
Prompt-CAM: A Simpler Interpretable Transformer for Fine-Grained Analysis
Jan 16, 2025



We present a simple usage of pre-trained Vision Transformers (ViTs) for fine-grained analysis, aiming to identify and localize the traits that distinguish visually similar categories, such as different bird species or dog breeds. Pre-trained ViTs such as DINO have shown remarkable capabilities to extract localized, informative features. However, using saliency maps like Grad-CAM can hardly point out the traits: they often locate the whole object by a blurred, coarse heatmap, not traits. We propose a novel approach Prompt Class Attention Map (Prompt-CAM) to the rescue. Prompt-CAM learns class-specific prompts to a pre-trained ViT and uses the corresponding outputs for classification. To classify an image correctly, the true-class prompt must attend to the unique image patches not seen in other classes' images, i.e., traits. As such, the true class's multi-head attention maps reveal traits and their locations. Implementation-wise, Prompt-CAM is almost a free lunch by simply modifying the prediction head of Visual Prompt Tuning (VPT). This makes Prompt-CAM fairly easy to train and apply, sharply contrasting other interpretable methods that design specific models and training processes. It is even simpler than the recently published INterpretable TRansformer (INTR), whose encoder-decoder architecture prevents it from leveraging pre-trained ViTs. Extensive empirical studies on a dozen datasets from various domains (e.g., birds, fishes, insects, fungi, flowers, food, and cars) validate Prompt-CAM superior interpretation capability.
Static Segmentation by Tracking: A Frustratingly Label-Efficient Approach to Fine-Grained Segmentation
Jan 12, 2025



We study image segmentation in the biological domain, particularly trait and part segmentation from specimen images (e.g., butterfly wing stripes or beetle body parts). This is a crucial, fine-grained task that aids in understanding the biology of organisms. The conventional approach involves hand-labeling masks, often for hundreds of images per species, and training a segmentation model to generalize these labels to other images, which can be exceedingly laborious. We present a label-efficient method named Static Segmentation by Tracking (SST). SST is built upon the insight: while specimens of the same species have inherent variations, the traits and parts we aim to segment show up consistently. This motivates us to concatenate specimen images into a ``pseudo-video'' and reframe trait and part segmentation as a tracking problem. Concretely, SST generates masks for unlabeled images by propagating annotated or predicted masks from the ``pseudo-preceding'' images. Powered by Segment Anything Model 2 (SAM~2) initially developed for video segmentation, we show that SST can achieve high-quality trait and part segmentation with merely one labeled image per species -- a breakthrough for analyzing specimen images. We further develop a cycle-consistent loss to fine-tune the model, again using one labeled image. Additionally, we highlight the broader potential of SST, including one-shot instance segmentation on images taken in the wild and trait-based image retrieval.
Multispecies Animal Re-ID Using a Large Community-Curated Dataset
Dec 07, 2024


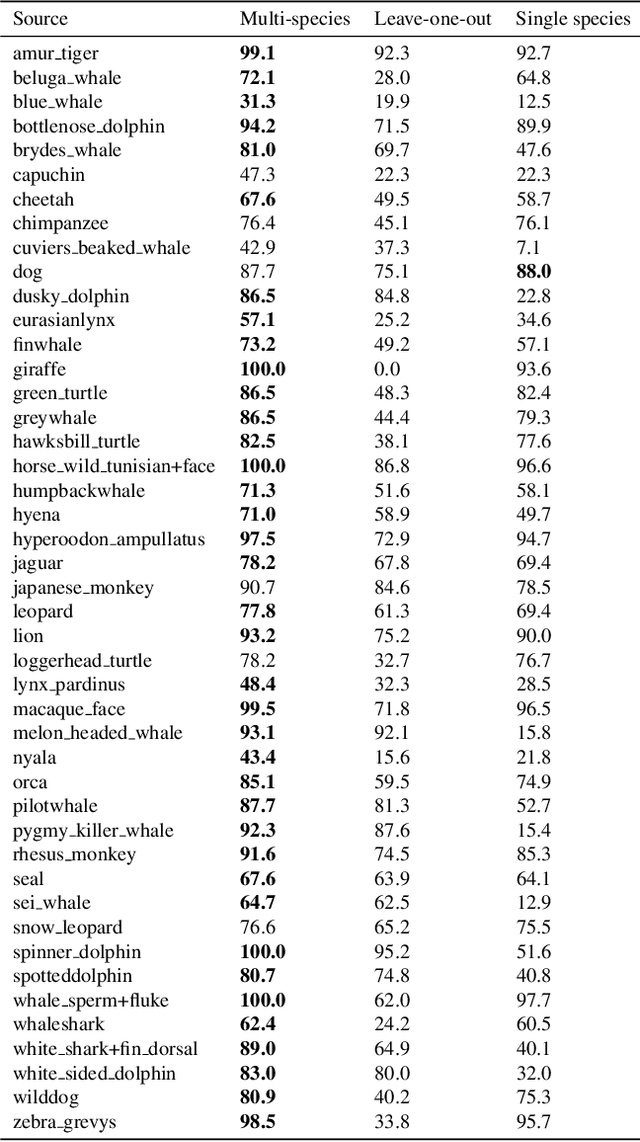
Recent work has established the ecological importance of developing algorithms for identifying animals individually from images. Typically, a separate algorithm is trained for each species, a natural step but one that creates significant barriers to wide-spread use: (1) each effort is expensive, requiring data collection, data curation, and model training, deployment, and maintenance, (2) there is little training data for many species, and (3) commonalities in appearance across species are not exploited. We propose an alternative approach focused on training multi-species individual identification (re-id) models. We construct a dataset that includes 49 species, 37K individual animals, and 225K images, using this data to train a single embedding network for all species. Our model employs an EfficientNetV2 backbone and a sub-center ArcFace loss function with dynamic margins. We evaluate the performance of this multispecies model in several ways. Most notably, we demonstrate that it consistently outperforms models trained separately on each species, achieving an average gain of 12.5% in top-1 accuracy. Furthermore, the model demonstrates strong zero-shot performance and fine-tuning capabilities for new species with limited training data, enabling effective curation of new species through both incremental addition of data to the training set and fine-tuning without the original data. Additionally, our model surpasses the recent MegaDescriptor on unseen species, averaging an 19.2% top-1 improvement per species and showing gains across all 33 species tested. The fully-featured code repository is publicly available on GitHub, and the feature extractor model can be accessed on HuggingFace for seamless integration with wildlife re-identification pipelines. The model is already in production use for 60+ species in a large-scale wildlife monitoring system.
Adapting the re-ID challenge for static sensors
Nov 30, 2024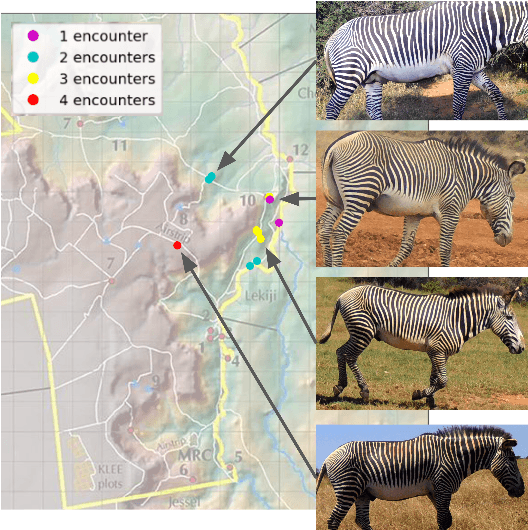
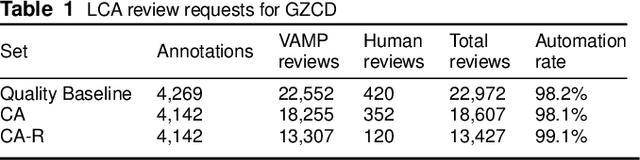
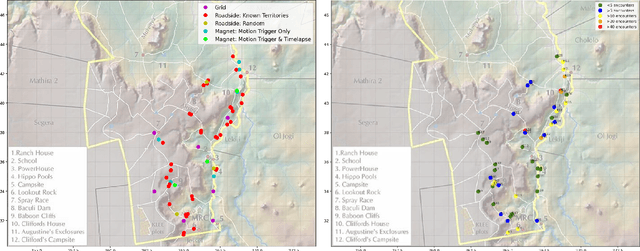
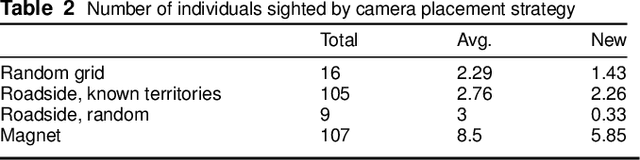
In both 2016 and 2018, a census of the highly-endangered Grevy's zebra population was enabled by the Great Grevy's Rally (GGR), a citizen science event that produces population estimates via expert and algorithmic curation of volunteer-captured images. A complementary, scalable, and long-term Grevy's population monitoring approach involves deploying camera trap networks. However, in both scenarios, a substantial majority of zebra images are not usable for individual identification due to poor in-the-wild imaging conditions; camera trap images in particular present high rates of occlusion and high spatio-temporal similarity within image bursts. Our proposed filtering pipeline incorporates animal detection, species identification, viewpoint estimation, quality evaluation, and temporal subsampling to obtain individual crops suitable for re-ID, which are subsequently curated by the LCA decision management algorithm. Our method processed images taken during GGR-16 and GGR-18 in Meru County, Kenya, into 4,142 highly-comparable annotations, requiring only 120 contrastive human decisions to produce a population estimate within 4.6% of the ground-truth count. Our method also efficiently processed 8.9M unlabeled camera trap images from 70 cameras at the Mpala Research Centre in Laikipia County, Kenya over two years into 685 encounters of 173 individuals, requiring only 331 contrastive human decisions.
Integrating Biological Data into Autonomous Remote Sensing Systems for In Situ Imageomics: A Case Study for Kenyan Animal Behavior Sensing with Unmanned Aerial Vehicles (UAVs)
Jul 23, 2024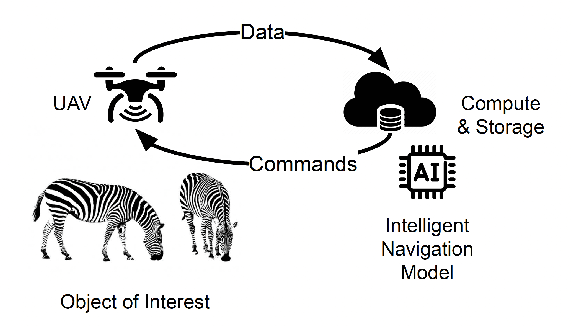



In situ imageomics leverages machine learning techniques to infer biological traits from images collected in the field, or in situ, to study individuals organisms, groups of wildlife, and whole ecosystems. Such datasets provide real-time social and environmental context to inferred biological traits, which can enable new, data-driven conservation and ecosystem management. The development of machine learning techniques to extract biological traits from images are impeded by the volume and quality data required to train these models. Autonomous, unmanned aerial vehicles (UAVs), are well suited to collect in situ imageomics data as they can traverse remote terrain quickly to collect large volumes of data with greater consistency and reliability compared to manually piloted UAV missions. However, little guidance exists on optimizing autonomous UAV missions for the purposes of remote sensing for conservation and biodiversity monitoring. The UAV video dataset curated by KABR: In-Situ Dataset for Kenyan Animal Behavior Recognition from Drone Videos required three weeks to collect, a time-consuming and expensive endeavor. Our analysis of KABR revealed that a third of the videos gathered were unusable for the purposes of inferring wildlife behavior. We analyzed the flight telemetry data from portions of UAV videos that were usable for inferring wildlife behavior, and demonstrate how these insights can be integrated into an autonomous remote sensing system to track wildlife in real time. Our autonomous remote sensing system optimizes the UAV's actions to increase the yield of usable data, and matches the flight path of an expert pilot with an 87% accuracy rate, representing an 18.2% improvement in accuracy over previously proposed methods.
Understanding the Impact of Training Set Size on Animal Re-identification
May 24, 2024


Recent advancements in the automatic re-identification of animal individuals from images have opened up new possibilities for studying wildlife through camera traps and citizen science projects. Existing methods leverage distinct and permanent visual body markings, such as fur patterns or scars, and typically employ one of two strategies: local features or end-to-end learning. In this study, we delve into the impact of training set size by conducting comprehensive experiments across six different methods and five animal species. While it is well known that end-to-end learning-based methods surpass local feature-based methods given a sufficient amount of good-quality training data, the challenge of gathering such datasets for wildlife animals means that local feature-based methods remain a more practical approach for many species. We demonstrate the benefits of both local feature and end-to-end learning-based approaches and show that species-specific characteristics, particularly intra-individual variance, have a notable effect on training data requirements.