 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep in the Jungle: Towards Automating Chimpanzee Population Estimation
Jan 30, 2026The estimation of abundance and density in unmarked populations of great apes relies on statistical frameworks that require animal-to-camera distance measurements. In practice, acquiring these distances depends on labour-intensive manual interpretation of animal observations across large camera trap video corpora. This study introduces and evaluates an only sparsely explored alternative: the integration of computer vision-based monocular depth estimation (MDE) pipelines directly into ecological camera trap workflows for great ape conservation. Using a real-world dataset of 220 camera trap videos documenting a wild chimpanzee population, we combine two MDE models, Dense Prediction Transformers and Depth Anything, with multiple distance sampling strategies. These components are used to generate detection distance estimates, from which population density and abundance are inferred. Comparative analysis against manually derived ground-truth distances shows that calibrated DPT consistently outperforms Depth Anything. This advantage is observed in both distance estimation accuracy and downstream density and abundance inference. Nevertheless, both models exhibit systematic biases. We show that, given complex forest environments, they tend to overestimate detection distances and consequently underestimate density and abundance relative to conventional manual approaches. We further find that failures in animal detection across distance ranges are a primary factor limiting estimation accuracy. Overall, this work provides a case study that shows MDE-driven camera trap distance sampling is a viable and practical alternative to manual distance estimation. The proposed approach yields population estimates within 22% of those obtained using traditional methods.
The SA-FARI Dataset: Segment Anything in Footage of Animals for Recognition and Identification
Nov 19, 2025Automated video analysis is critical for wildlife conservation. A foundational task in this domain is multi-animal tracking (MAT), which underpins applications such as individual re-identification and behavior recognition. However, existing datasets are limited in scale, constrained to a few species, or lack sufficient temporal and geographical diversity - leaving no suitable benchmark for training general-purpose MAT models applicable across wild animal populations. To address this, we introduce SA-FARI, the largest open-source MAT dataset for wild animals. It comprises 11,609 camera trap videos collected over approximately 10 years (2014-2024) from 741 locations across 4 continents, spanning 99 species categories. Each video is exhaustively annotated culminating in ~46 hours of densely annotated footage containing 16,224 masklet identities and 942,702 individual bounding boxes, segmentation masks, and species labels. Alongside the task-specific annotations, we publish anonymized camera trap locations for each video. Finally, we present comprehensive benchmarks on SA-FARI using state-of-the-art vision-language models for detection and tracking, including SAM 3, evaluated with both species-specific and generic animal prompts. We also compare against vision-only methods developed specifically for wildlife analysis. SA-FARI is the first large-scale dataset to combine high species diversity, multi-region coverage, and high-quality spatio-temporal annotations, offering a new foundation for advancing generalizable multianimal tracking in the wild. The dataset is available at $\href{https://www.conservationxlabs.com/sa-fari}{\text{conservationxlabs.com/SA-FARI}}$.
Towards Application-Specific Evaluation of Vision Models: Case Studies in Ecology and Biology
May 05, 2025Computer vision methods have demonstrated considerable potential to streamline ecological and biological workflows, with a growing number of datasets and models becoming available to the research community. However, these resources focus predominantly on evaluation using machine learning metrics, with relatively little emphasis on how their application impacts downstream analysis. We argue that models should be evaluated using application-specific metrics that directly represent model performance in the context of its final use case. To support this argument, we present two disparate case studies: (1) estimating chimpanzee abundance and density with camera trap distance sampling when using a video-based behaviour classifier and (2) estimating head rotation in pigeons using a 3D posture estimator. We show that even models with strong machine learning performance (e.g., 87% mAP) can yield data that leads to discrepancies in abundance estimates compared to expert-derived data. Similarly, the highest-performing models for posture estimation do not produce the most accurate inferences of gaze direction in pigeons. Motivated by these findings, we call for researchers to integrate application-specific metrics in ecological/biological datasets, allowing for models to be benchmarked in the context of their downstream application and to facilitate better integration of models into application workflows.
The PanAf-FGBG Dataset: Understanding the Impact of Backgrounds in Wildlife Behaviour Recognition
Feb 28, 2025



Computer vision analysis of camera trap video footage is essential for wildlife conservation, as captured behaviours offer some of the earliest indicators of changes in population health. Recently, several high-impact animal behaviour datasets and methods have been introduced to encourage their use; however, the role of behaviour-correlated background information and its significant effect on out-of-distribution generalisation remain unexplored. In response, we present the PanAf-FGBG dataset, featuring 20 hours of wild chimpanzee behaviours, recorded at over 350 individual camera locations. Uniquely, it pairs every video with a chimpanzee (referred to as a foreground video) with a corresponding background video (with no chimpanzee) from the same camera location. We present two views of the dataset: one with overlapping camera locations and one with disjoint locations. This setup enables, for the first time, direct evaluation of in-distribution and out-of-distribution conditions, and for the impact of backgrounds on behaviour recognition models to be quantified. All clips come with rich behavioural annotations and metadata including unique camera IDs and detailed textual scene descriptions. Additionally, we establish several baselines and present a highly effective latent-space normalisation technique that boosts out-of-distribution performance by +5.42% mAP for convolutional and +3.75% mAP for transformer-based models. Finally, we provide an in-depth analysis on the role of backgrounds in out-of-distribution behaviour recognition, including the so far unexplored impact of background durations (i.e., the count of background frames within foreground videos).
Integrating Biological Data into Autonomous Remote Sensing Systems for In Situ Imageomics: A Case Study for Kenyan Animal Behavior Sensing with Unmanned Aerial Vehicles (UAVs)
Jul 23, 2024In situ imageomics leverages machine learning techniques to infer biological traits from images collected in the field, or in situ, to study individuals organisms, groups of wildlife, and whole ecosystems. Such datasets provide real-time social and environmental context to inferred biological traits, which can enable new, data-driven conservation and ecosystem management. The development of machine learning techniques to extract biological traits from images are impeded by the volume and quality data required to train these models. Autonomous, unmanned aerial vehicles (UAVs), are well suited to collect in situ imageomics data as they can traverse remote terrain quickly to collect large volumes of data with greater consistency and reliability compared to manually piloted UAV missions. However, little guidance exists on optimizing autonomous UAV missions for the purposes of remote sensing for conservation and biodiversity monitoring. The UAV video dataset curated by KABR: In-Situ Dataset for Kenyan Animal Behavior Recognition from Drone Videos required three weeks to collect, a time-consuming and expensive endeavor. Our analysis of KABR revealed that a third of the videos gathered were unusable for the purposes of inferring wildlife behavior. We analyzed the flight telemetry data from portions of UAV videos that were usable for inferring wildlife behavior, and demonstrate how these insights can be integrated into an autonomous remote sensing system to track wildlife in real time. Our autonomous remote sensing system optimizes the UAV's actions to increase the yield of usable data, and matches the flight path of an expert pilot with an 87% accuracy rate, representing an 18.2% improvement in accuracy over previously proposed methods.
ChimpVLM: Ethogram-Enhanced Chimpanzee Behaviour Recognition
Apr 13, 2024We show that chimpanzee behaviour understanding from camera traps can be enhanced by providing visual architectures with access to an embedding of text descriptions that detail species behaviours. In particular, we present a vision-language model which employs multi-modal decoding of visual features extracted directly from camera trap videos to process query tokens representing behaviours and output class predictions. Query tokens are initialised using a standardised ethogram of chimpanzee behaviour, rather than using random or name-based initialisations. In addition, the effect of initialising query tokens using a masked language model fine-tuned on a text corpus of known behavioural patterns is explored. We evaluate our system on the PanAf500 and PanAf20K datasets and demonstrate the performance benefits of our multi-modal decoding approach and query initialisation strategy on multi-class and multi-label recognition tasks, respectively. Results and ablations corroborate performance improvements. We achieve state-of-the-art performance over vision and vision-language models in top-1 accuracy (+6.34%) on PanAf500 and overall (+1.1%) and tail-class (+2.26%) mean average precision on PanAf20K. We share complete source code and network weights for full reproducibility of results and easy utilisation.
PanAf20K: A Large Video Dataset for Wild Ape Detection and Behaviour Recognition
Jan 31, 2024
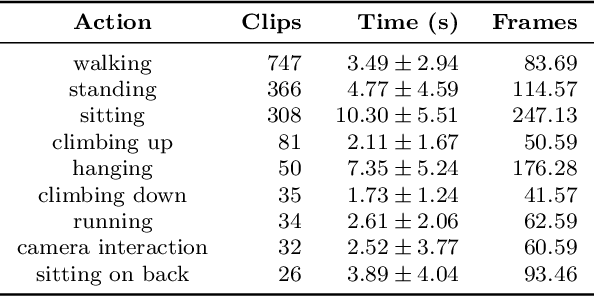

We present the PanAf20K dataset, the largest and most diverse open-access annotated video dataset of great apes in their natural environment. It comprises more than 7 million frames across ~20,000 camera trap videos of chimpanzees and gorillas collected at 14 field sites in tropical Africa as part of the Pan African Programme: The Cultured Chimpanzee. The footage is accompanied by a rich set of annotations and benchmarks making it suitable for training and testing a variety of challenging and ecologically important computer vision tasks including ape detection and behaviour recognition. Furthering AI analysis of camera trap information is critical given the International Union for Conservation of Nature now lists all species in the great ape family as either Endangered or Critically Endangered. We hope the dataset can form a solid basis for engagement of the AI community to improve performance, efficiency, and result interpretation in order to support assessments of great ape presence, abundance, distribution, and behaviour and thereby aid conservation efforts.
Triple-stream Deep Metric Learning of Great Ape Behavioural Actions
Jan 06, 2023
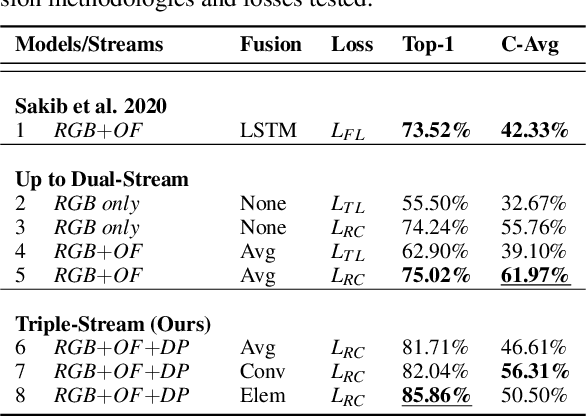


We propose the first metric learning system for the recognition of great ape behavioural actions. Our proposed triple stream embedding architecture works on camera trap videos taken directly in the wild and demonstrates that the utilisation of an explicit DensePose-C chimpanzee body part segmentation stream effectively complements traditional RGB appearance and optical flow streams. We evaluate system variants with different feature fusion techniques and long-tail recognition approaches. Results and ablations show performance improvements of ~12% in top-1 accuracy over previous results achieved on the PanAf-500 dataset containing 180,000 manually annotated frames across nine behavioural actions. Furthermore, we provide a qualitative analysis of our findings and augment the metric learning system with long-tail recognition techniques showing that average per class accuracy -- critical in the domain -- can be improved by ~23% compared to the literature on that dataset. Finally, since our embedding spaces are constructed as metric, we provide first data-driven visualisations of the great ape behavioural action spaces revealing emerging geometry and topology. We hope that the work sparks further interest in this vital application area of computer vision for the benefit of endangered great apes.
A Dataset and Application for Facial Recognition of Individual Gorillas in Zoo Environments
Dec 08, 2020
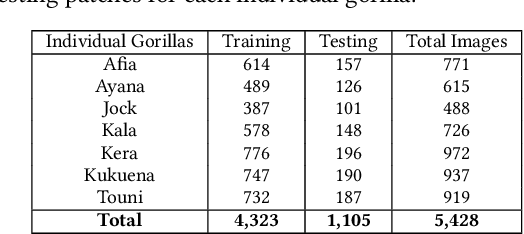


We put forward a video dataset with 5k+ facial bounding box annotations across a troop of 7 western lowland gorillas at Bristol Zoo Gardens. Training on this dataset, we implement and evaluate a standard deep learning pipeline on the task of facially recognising individual gorillas in a zoo environment. We show that a basic YOLOv3-powered application is able to perform identifications at 92% mAP when utilising single frames only. Tracking-by-detection-association and identity voting across short tracklets yields an improved robust performance of 97% mAP. To facilitate easy utilisation for enriching the research capabilities of zoo environments, we publish the code, video dataset, weights, and ground-truth annotations at data.bris.ac.uk.