 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking Phenological Status and Ecological Interactions in a Hawaiian Cloud Forest Understory using Low-Cost Camera Traps and Visual Foundation Models
Mar 08, 2026Plant phenology, the study of cyclical events such as leafing out, flowering, or fruiting, has wide ecological impacts but is broadly understudied, especially in the tropics. Image analysis has greatly enhanced remote phenological monitoring, yet capturing phenology at the individual level remains challenging. In this project, we deployed low-cost, animal-triggered camera traps at the Pu'u Maka'ala Natural Area Reserve in Hawaii to simultaneously document shifts in plant phenology and flora-faunal interactions. Using a combination of foundation vision models and traditional computer vision methods, we measure phenological trends from images comparable to on-the-ground observations without relying on supervised learning techniques. These temporally fine-grained phenology measurements from camera-trap images uncover trends that coarser traditional sampling fails to detect. When combined with detailed visitation data detected from images, these trends can begin to elucidate drivers of both plant phenology and animal ecology.
BioCLIP 2: Emergent Properties from Scaling Hierarchical Contrastive Learning
May 29, 2025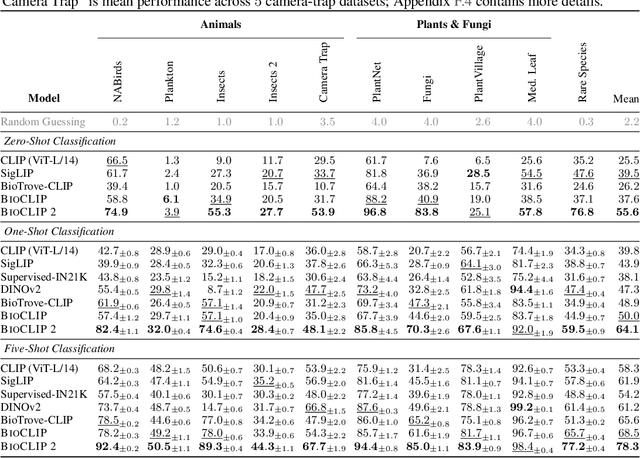
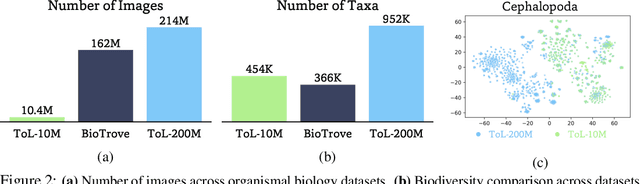
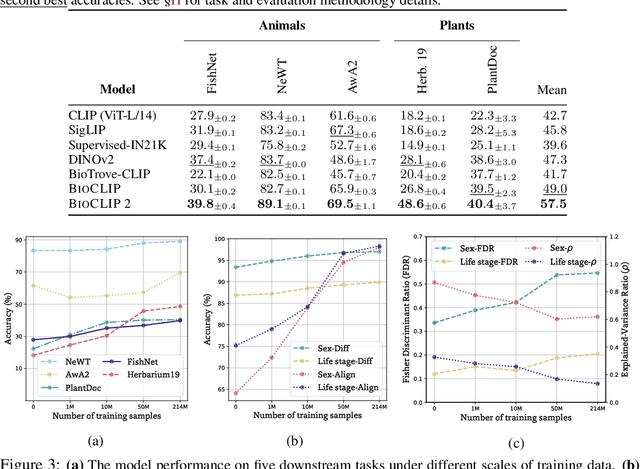
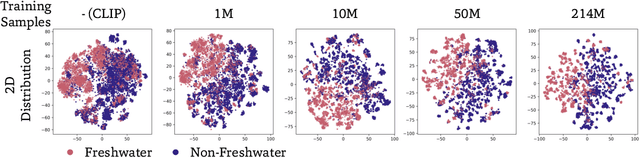
Foundation models trained at scale exhibit remarkable emergent behaviors, learning new capabilities beyond their initial training objectives. We find such emergent behaviors in biological vision models via large-scale contrastive vision-language training. To achieve this, we first curate TreeOfLife-200M, comprising 214 million images of living organisms, the largest and most diverse biological organism image dataset to date. We then train BioCLIP 2 on TreeOfLife-200M to distinguish different species. Despite the narrow training objective, BioCLIP 2 yields extraordinary accuracy when applied to various biological visual tasks such as habitat classification and trait prediction. We identify emergent properties in the learned embedding space of BioCLIP 2. At the inter-species level, the embedding distribution of different species aligns closely with functional and ecological meanings (e.g., beak sizes and habitats). At the intra-species level, instead of being diminished, the intra-species variations (e.g., life stages and sexes) are preserved and better separated in subspaces orthogonal to inter-species distinctions. We provide formal proof and analyses to explain why hierarchical supervision and contrastive objectives encourage these emergent properties. Crucially, our results reveal that these properties become increasingly significant with larger-scale training data, leading to a biologically meaningful embedding space.
Tracking the Flight: Exploring a Computational Framework for Analyzing Escape Responses in Plains Zebra (Equus quagga)
May 22, 2025

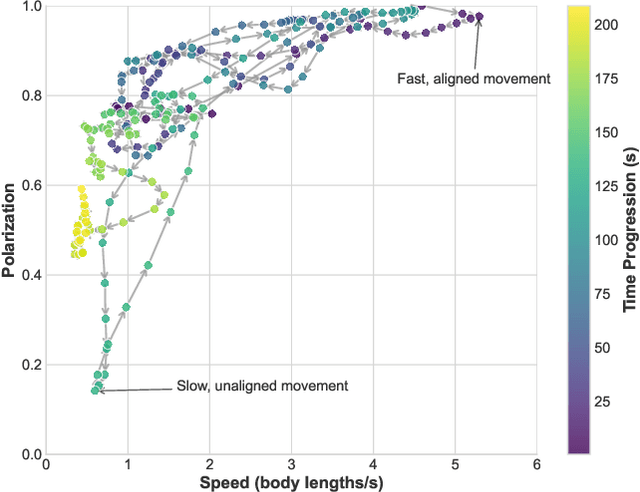
Ethological research increasingly benefits from the growing affordability and accessibility of drones, which enable the capture of high-resolution footage of animal movement at fine spatial and temporal scales. However, analyzing such footage presents the technical challenge of separating animal movement from drone motion. While non-trivial, computer vision techniques such as image registration and Structure-from-Motion (SfM) offer practical solutions. For conservationists, open-source tools that are user-friendly, require minimal setup, and deliver timely results are especially valuable for efficient data interpretation. This study evaluates three approaches: a bioimaging-based registration technique, an SfM pipeline, and a hybrid interpolation method. We apply these to a recorded escape event involving 44 plains zebras, captured in a single drone video. Using the best-performing method, we extract individual trajectories and identify key behavioral patterns: increased alignment (polarization) during escape, a brief widening of spacing just before stopping, and tighter coordination near the group's center. These insights highlight the method's effectiveness and its potential to scale to larger datasets, contributing to broader investigations of collective animal behavior.
Prompt-CAM: A Simpler Interpretable Transformer for Fine-Grained Analysis
Jan 16, 2025



We present a simple usage of pre-trained Vision Transformers (ViTs) for fine-grained analysis, aiming to identify and localize the traits that distinguish visually similar categories, such as different bird species or dog breeds. Pre-trained ViTs such as DINO have shown remarkable capabilities to extract localized, informative features. However, using saliency maps like Grad-CAM can hardly point out the traits: they often locate the whole object by a blurred, coarse heatmap, not traits. We propose a novel approach Prompt Class Attention Map (Prompt-CAM) to the rescue. Prompt-CAM learns class-specific prompts to a pre-trained ViT and uses the corresponding outputs for classification. To classify an image correctly, the true-class prompt must attend to the unique image patches not seen in other classes' images, i.e., traits. As such, the true class's multi-head attention maps reveal traits and their locations. Implementation-wise, Prompt-CAM is almost a free lunch by simply modifying the prediction head of Visual Prompt Tuning (VPT). This makes Prompt-CAM fairly easy to train and apply, sharply contrasting other interpretable methods that design specific models and training processes. It is even simpler than the recently published INterpretable TRansformer (INTR), whose encoder-decoder architecture prevents it from leveraging pre-trained ViTs. Extensive empirical studies on a dozen datasets from various domains (e.g., birds, fishes, insects, fungi, flowers, food, and cars) validate Prompt-CAM superior interpretation capability.
Static Segmentation by Tracking: A Frustratingly Label-Efficient Approach to Fine-Grained Segmentation
Jan 12, 2025



We study image segmentation in the biological domain, particularly trait and part segmentation from specimen images (e.g., butterfly wing stripes or beetle body parts). This is a crucial, fine-grained task that aids in understanding the biology of organisms. The conventional approach involves hand-labeling masks, often for hundreds of images per species, and training a segmentation model to generalize these labels to other images, which can be exceedingly laborious. We present a label-efficient method named Static Segmentation by Tracking (SST). SST is built upon the insight: while specimens of the same species have inherent variations, the traits and parts we aim to segment show up consistently. This motivates us to concatenate specimen images into a ``pseudo-video'' and reframe trait and part segmentation as a tracking problem. Concretely, SST generates masks for unlabeled images by propagating annotated or predicted masks from the ``pseudo-preceding'' images. Powered by Segment Anything Model 2 (SAM~2) initially developed for video segmentation, we show that SST can achieve high-quality trait and part segmentation with merely one labeled image per species -- a breakthrough for analyzing specimen images. We further develop a cycle-consistent loss to fine-tune the model, again using one labeled image. Additionally, we highlight the broader potential of SST, including one-shot instance segmentation on images taken in the wild and trait-based image retrieval.
Adapting the re-ID challenge for static sensors
Nov 30, 2024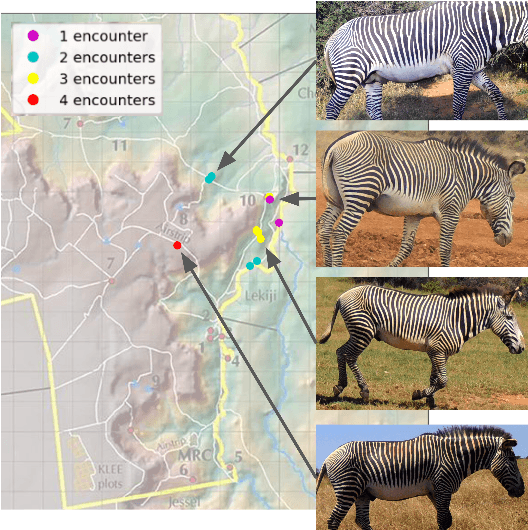
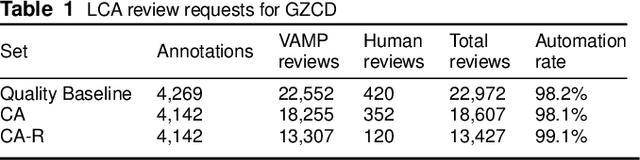
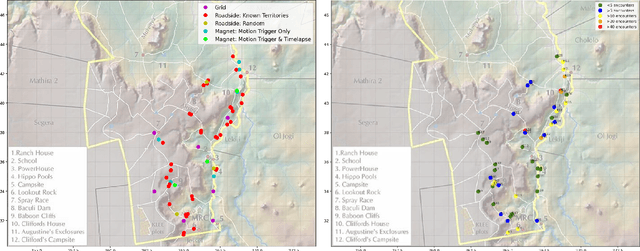
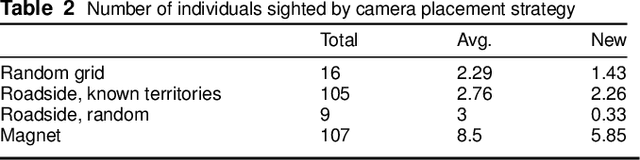
In both 2016 and 2018, a census of the highly-endangered Grevy's zebra population was enabled by the Great Grevy's Rally (GGR), a citizen science event that produces population estimates via expert and algorithmic curation of volunteer-captured images. A complementary, scalable, and long-term Grevy's population monitoring approach involves deploying camera trap networks. However, in both scenarios, a substantial majority of zebra images are not usable for individual identification due to poor in-the-wild imaging conditions; camera trap images in particular present high rates of occlusion and high spatio-temporal similarity within image bursts. Our proposed filtering pipeline incorporates animal detection, species identification, viewpoint estimation, quality evaluation, and temporal subsampling to obtain individual crops suitable for re-ID, which are subsequently curated by the LCA decision management algorithm. Our method processed images taken during GGR-16 and GGR-18 in Meru County, Kenya, into 4,142 highly-comparable annotations, requiring only 120 contrastive human decisions to produce a population estimate within 4.6% of the ground-truth count. Our method also efficiently processed 8.9M unlabeled camera trap images from 70 cameras at the Mpala Research Centre in Laikipia County, Kenya over two years into 685 encounters of 173 individuals, requiring only 331 contrastive human decisions.
A Simple Interpretable Transformer for Fine-Grained Image Classification and Analysis
Nov 07, 2023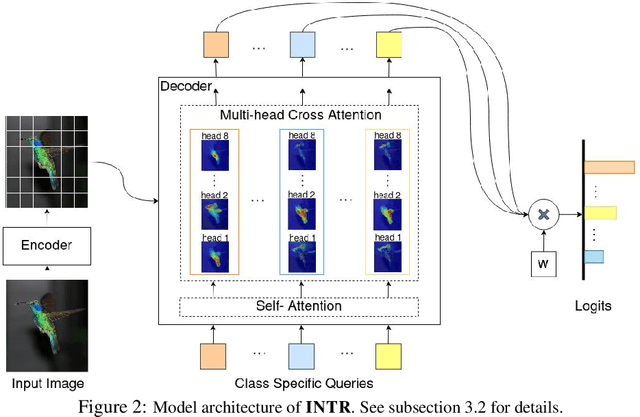

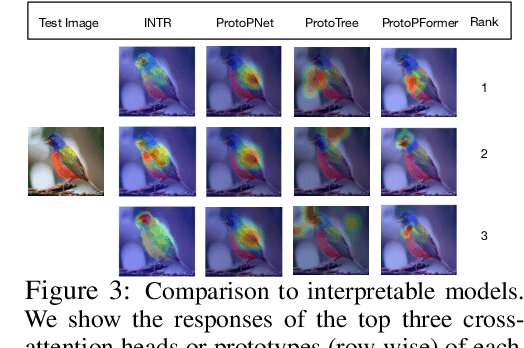

We present a novel usage of Transformers to make image classification interpretable. Unlike mainstream classifiers that wait until the last fully-connected layer to incorporate class information to make predictions, we investigate a proactive approach, asking each class to search for itself in an image. We realize this idea via a Transformer encoder-decoder inspired by DEtection TRansformer (DETR). We learn ``class-specific'' queries (one for each class) as input to the decoder, enabling each class to localize its patterns in an image via cross-attention. We name our approach INterpretable TRansformer (INTR), which is fairly easy to implement and exhibits several compelling properties. We show that INTR intrinsically encourages each class to attend distinctively; the cross-attention weights thus provide a faithful interpretation of the prediction. Interestingly, via ``multi-head'' cross-attention, INTR could identify different ``attributes'' of a class, making it particularly suitable for fine-grained classification and analysis, which we demonstrate on eight datasets. Our code and pre-trained model are publicly accessible at https://github.com/Imageomics/INTR.