 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetwork Model Selection for Task-Focused Attributed Network Inference
Sep 16, 2017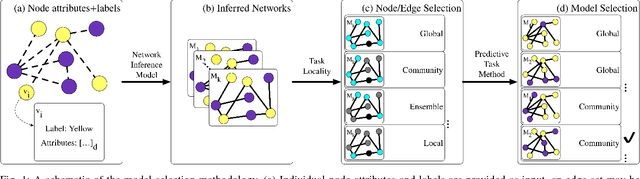
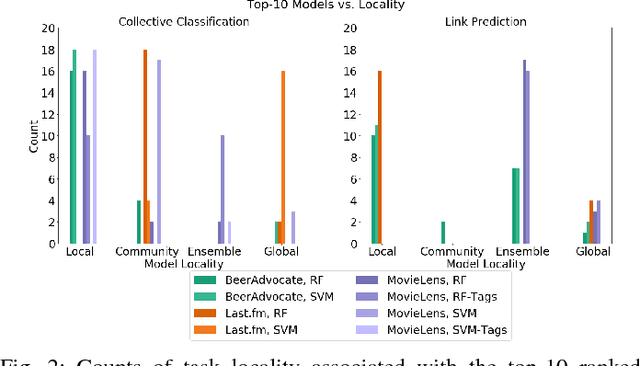
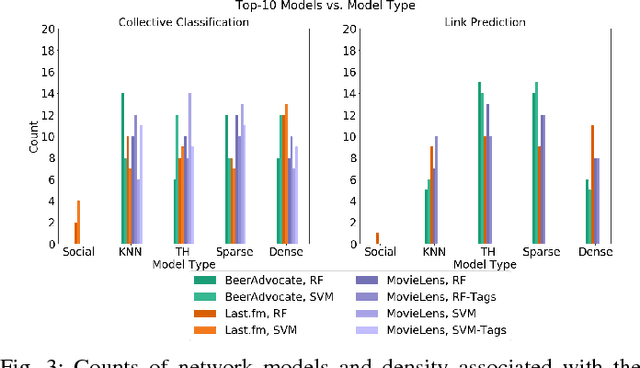
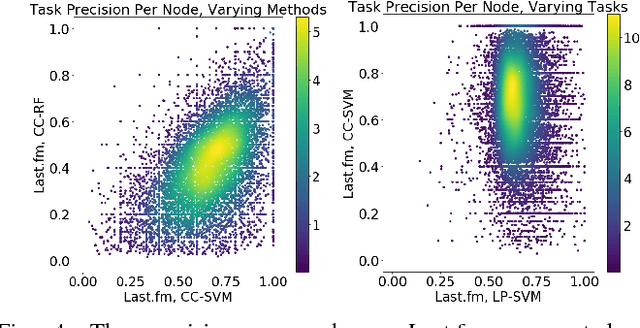
Networks are models representing relationships between entities. Often these relationships are explicitly given, or we must learn a representation which generalizes and predicts observed behavior in underlying individual data (e.g. attributes or labels). Whether given or inferred, choosing the best representation affects subsequent tasks and questions on the network. This work focuses on model selection to evaluate network representations from data, focusing on fundamental predictive tasks on networks. We present a modular methodology using general, interpretable network models, task neighborhood functions found across domains, and several criteria for robust model selection. We demonstrate our methodology on three online user activity datasets and show that network model selection for the appropriate network task vs. an alternate task increases performance by an order of magnitude in our experiments.
Evaluating Social Networks Using Task-Focused Network Inference
Jul 08, 2017
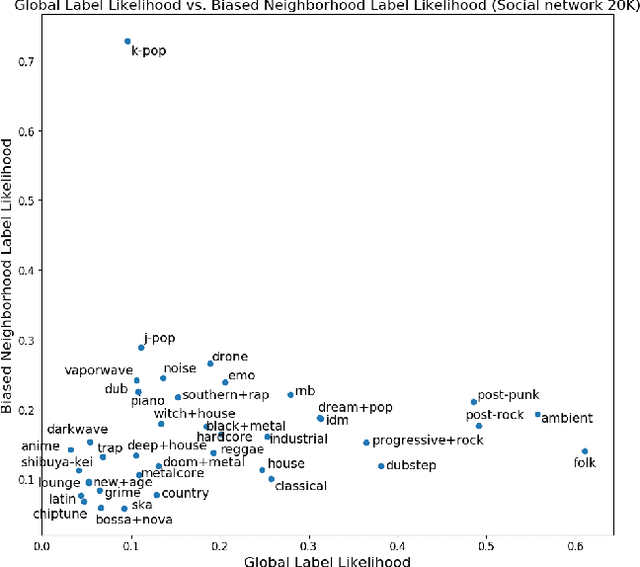
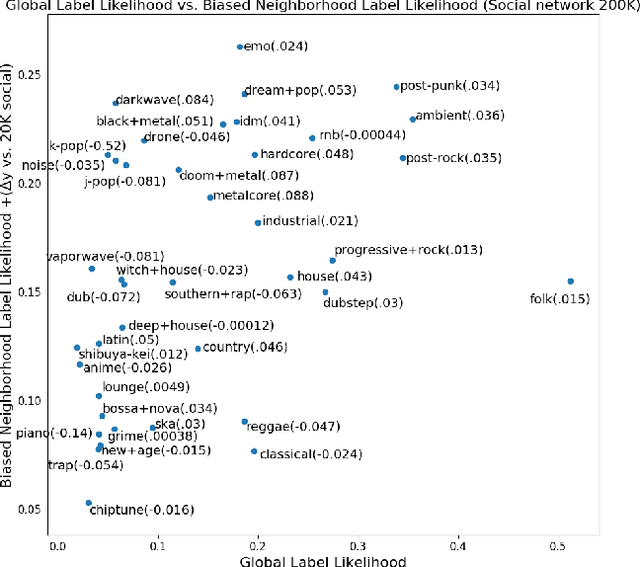
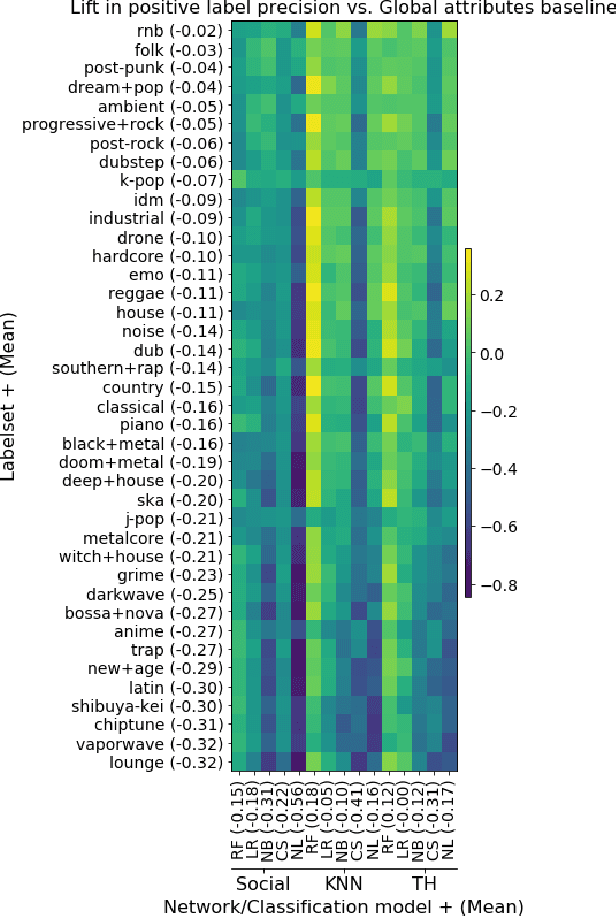
Networks are representations of complex underlying social processes. However, the same given network may be more suitable to model one behavior of individuals than another. In many cases, aggregate population models may be more effective than modeling on the network. We present a general framework for evaluating the suitability of given networks for a set of predictive tasks of interest, compared against alternative, networks inferred from data. We present several interpretable network models and measures for our comparison. We apply this general framework to the case study on collective classification of music preferences in a newly available dataset of the Last.fm social network.