 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Recomposition by Learning-based ICP
Paper and Code
Dec 13, 2018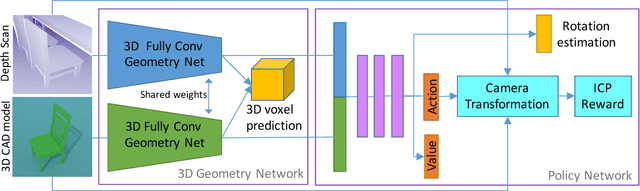


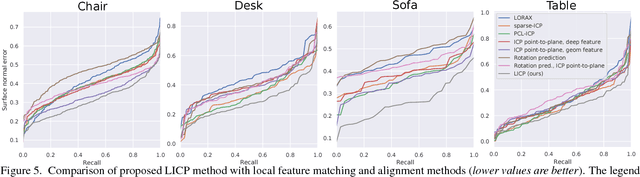
By moving a depth sensor around a room, we compute a 3D CAD model of the environment, capturing the room shape and contents such as chairs, desks, sofas, and tables. Rather than reconstructing geometry, we match, place, and align each object in the scene to thousands of CAD models of objects. In addition to the end-to-end system, the key technical contribution is a novel approach for aligning CAD models to 3D scans, based on deep reinforcement learning. This approach, which we call Learning-based ICP, outperforms prior ICP methods in the literature, by learning the best points to match and conditioning on object viewpoint. LICP learns to align using only synthetic data and does not require ground-truth annotation of object pose or keypoint pair matching in real scene scans. While LICP is trained on synthetic data and without 3D real scene annotations, it outperforms both learned local deep feature matching and geometric based alignment methods in real scenes. Proposed method is evaluated on publicly available real scenes datasets of SceneNN and ScanNet as well as synthetic scenes of SUNCG. High quality results are demonstrated on a range of real world scenes, with robustness to clutter, viewpoint, and occlusion.