 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemexQA: Visual Memex Question Answering
Paper and Code
Aug 04, 2017


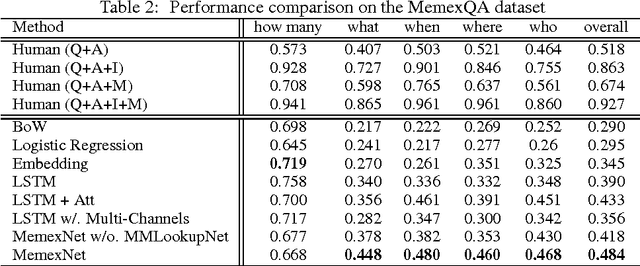
This paper proposes a new task, MemexQA: given a collection of photos or videos from a user, the goal is to automatically answer questions that help users recover their memory about events captured in the collection. Towards solving the task, we 1) present the MemexQA dataset, a large, realistic multimodal dataset consisting of real personal photos and crowd-sourced questions/answers, 2) propose MemexNet, a unified, end-to-end trainable network architecture for image, text and video question answering. Experimental results on the MemexQA dataset demonstrate that MemexNet outperforms strong baselines and yields the state-of-the-art on this novel and challenging task. The promising results on TextQA and VideoQA suggest MemexNet's efficacy and scalability across various QA tasks.