 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study on Ensemble-Based Transfer Learning Bayesian Optimisation with Mixed Variable Types
Jan 22, 2026Bayesian optimisation is a sample efficient method for finding a global optimum of expensive black-box objective functions. Historic datasets from related problems can be exploited to help improve performance of Bayesian optimisation by adapting transfer learning methods to various components of the Bayesian optimisation pipeline. In this study we perform an empirical analysis of various ensemble-based transfer learning Bayesian optimisation methods and pipeline components. We expand on previous work in the literature by contributing some specific pipeline components, and three new real-time transfer learning Bayesian optimisation benchmarks. In particular we propose to use a weighting strategy for ensemble surrogate model predictions based on regularised regression with weights constrained to be positive, and a related component for handling the case when transfer learning is not improving Bayesian optimisation performance. We find that in general, two components that help improve transfer learning Bayesian optimisation performance are warm start initialisation and constraining weights used with ensemble surrogate model to be positive.
MOCA-HESP: Meta High-dimensional Bayesian Optimization for Combinatorial and Mixed Spaces via Hyper-ellipsoid Partitioning
Aug 09, 2025High-dimensional Bayesian Optimization (BO) has attracted significant attention in recent research. However, existing methods have mainly focused on optimizing in continuous domains, while combinatorial (ordinal and categorical) and mixed domains still remain challenging. In this paper, we first propose MOCA-HESP, a novel high-dimensional BO method for combinatorial and mixed variables. The key idea is to leverage the hyper-ellipsoid space partitioning (HESP) technique with different categorical encoders to work with high-dimensional, combinatorial and mixed spaces, while adaptively selecting the optimal encoders for HESP using a multi-armed bandit technique. Our method, MOCA-HESP, is designed as a \textit{meta-algorithm} such that it can incorporate other combinatorial and mixed BO optimizers to further enhance the optimizers' performance. Finally, we develop three practical BO methods by integrating MOCA-HESP with state-of-the-art BO optimizers for combinatorial and mixed variables: standard BO, CASMOPOLITAN, and Bounce. Our experimental results on various synthetic and real-world benchmarks show that our methods outperform existing baselines. Our code implementation can be found at https://github.com/LamNgo1/moca-hesp
REMEMBER: Retrieval-based Explainable Multimodal Evidence-guided Modeling for Brain Evaluation and Reasoning in Zero- and Few-shot Neurodegenerative Diagnosis
Apr 12, 2025Timely and accurate diagnosis of neurodegenerative disorders, such as Alzheimer's disease, is central to disease management. Existing deep learning models require large-scale annotated datasets and often function as "black boxes". Additionally, datasets in clinical practice are frequently small or unlabeled, restricting the full potential of deep learning methods. Here, we introduce REMEMBER -- Retrieval-based Explainable Multimodal Evidence-guided Modeling for Brain Evaluation and Reasoning -- a new machine learning framework that facilitates zero- and few-shot Alzheimer's diagnosis using brain MRI scans through a reference-based reasoning process. Specifically, REMEMBER first trains a contrastively aligned vision-text model using expert-annotated reference data and extends pseudo-text modalities that encode abnormality types, diagnosis labels, and composite clinical descriptions. Then, at inference time, REMEMBER retrieves similar, human-validated cases from a curated dataset and integrates their contextual information through a dedicated evidence encoding module and attention-based inference head. Such an evidence-guided design enables REMEMBER to imitate real-world clinical decision-making process by grounding predictions in retrieved imaging and textual context. Specifically, REMEMBER outputs diagnostic predictions alongside an interpretable report, including reference images and explanations aligned with clinical workflows. Experimental results demonstrate that REMEMBER achieves robust zero- and few-shot performance and offers a powerful and explainable framework to neuroimaging-based diagnosis in the real world, especially under limited data.
VisTA: Vision-Text Alignment Model with Contrastive Learning using Multimodal Data for Evidence-Driven, Reliable, and Explainable Alzheimer's Disease Diagnosis
Feb 03, 2025Objective: Assessing Alzheimer's disease (AD) using high-dimensional radiology images is clinically important but challenging. Although Artificial Intelligence (AI) has advanced AD diagnosis, it remains unclear how to design AI models embracing predictability and explainability. Here, we propose VisTA, a multimodal language-vision model assisted by contrastive learning, to optimize disease prediction and evidence-based, interpretable explanations for clinical decision-making. Methods: We developed VisTA (Vision-Text Alignment Model) for AD diagnosis. Architecturally, we built VisTA from BiomedCLIP and fine-tuned it using contrastive learning to align images with verified abnormalities and their descriptions. To train VisTA, we used a constructed reference dataset containing images, abnormality types, and descriptions verified by medical experts. VisTA produces four outputs: predicted abnormality type, similarity to reference cases, evidence-driven explanation, and final AD diagnoses. To illustrate VisTA's efficacy, we reported accuracy metrics for abnormality retrieval and dementia prediction. To demonstrate VisTA's explainability, we compared its explanations with human experts' explanations. Results: Compared to 15 million images used for baseline pretraining, VisTA only used 170 samples for fine-tuning and obtained significant improvement in abnormality retrieval and dementia prediction. For abnormality retrieval, VisTA reached 74% accuracy and an AUC of 0.87 (26% and 0.74, respectively, from baseline models). For dementia prediction, VisTA achieved 88% accuracy and an AUC of 0.82 (30% and 0.57, respectively, from baseline models). The generated explanations agreed strongly with human experts' and provided insights into the diagnostic process. Taken together, VisTA optimize prediction, clinical reasoning, and explanation.
BOIDS: High-dimensional Bayesian Optimization via Incumbent-guided Direction Lines and Subspace Embeddings
Dec 17, 2024



When it comes to expensive black-box optimization problems, Bayesian Optimization (BO) is a well-known and powerful solution. Many real-world applications involve a large number of dimensions, hence scaling BO to high dimension is of much interest. However, state-of-the-art high-dimensional BO methods still suffer from the curse of dimensionality, highlighting the need for further improvements. In this work, we introduce BOIDS, a novel high-dimensional BO algorithm that guides optimization by a sequence of one-dimensional direction lines using a novel tailored line-based optimization procedure. To improve the efficiency, we also propose an adaptive selection technique to identify most optimal lines for each round of line-based optimization. Additionally, we incorporate a subspace embedding technique for better scaling to high-dimensional spaces. We further provide theoretical analysis of our proposed method to analyze its convergence property. Our extensive experimental results show that BOIDS outperforms state-of-the-art baselines on various synthetic and real-world benchmark problems.
High-dimensional Bayesian Optimization via Covariance Matrix Adaptation Strategy
Feb 05, 2024Bayesian Optimization (BO) is an effective method for finding the global optimum of expensive black-box functions. However, it is well known that applying BO to high-dimensional optimization problems is challenging. To address this issue, a promising solution is to use a local search strategy that partitions the search domain into local regions with high likelihood of containing the global optimum, and then use BO to optimize the objective function within these regions. In this paper, we propose a novel technique for defining the local regions using the Covariance Matrix Adaptation (CMA) strategy. Specifically, we use CMA to learn a search distribution that can estimate the probabilities of data points being the global optimum of the objective function. Based on this search distribution, we then define the local regions consisting of data points with high probabilities of being the global optimum. Our approach serves as a meta-algorithm as it can incorporate existing black-box BO optimizers, such as BO, TuRBO, and BAxUS, to find the global optimum of the objective function within our derived local regions. We evaluate our proposed method on various benchmark synthetic and real-world problems. The results demonstrate that our method outperforms existing state-of-the-art techniques.
* 31 pages, 17 figures
Provably Efficient Bayesian Optimization with Unbiased Gaussian Process Hyperparameter Estimation
Jun 12, 2023


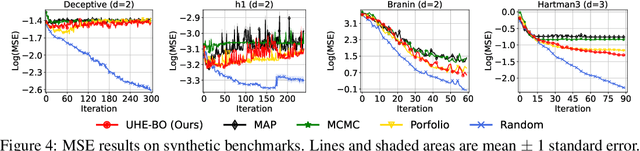
Gaussian process (GP) based Bayesian optimization (BO) is a powerful method for optimizing black-box functions efficiently. The practical performance and theoretical guarantees associated with this approach depend on having the correct GP hyperparameter values, which are usually unknown in advance and need to be estimated from the observed data. However, in practice, these estimations could be incorrect due to biased data sampling strategies commonly used in BO. This can lead to degraded performance and break the sub-linear global convergence guarantee of BO. To address this issue, we propose a new BO method that can sub-linearly converge to the global optimum of the objective function even when the true GP hyperparameters are unknown in advance and need to be estimated from the observed data. Our method uses a multi-armed bandit technique (EXP3) to add random data points to the BO process, and employs a novel training loss function for the GP hyperparameter estimation process that ensures unbiased estimation from the observed data. We further provide theoretical analysis of our proposed method. Finally, we demonstrate empirically that our method outperforms existing approaches on various synthetic and real-world problems.
Uncertainty-Aware Performance Prediction for Highly Configurable Software Systems via Bayesian Neural Networks
Dec 27, 2022



Configurable software systems are employed in many important application domains. Understanding the performance of the systems under all configurations is critical to prevent potential performance issues caused by misconfiguration. However, as the number of configurations can be prohibitively large, it is not possible to measure the system performance under all configurations. Thus, a common approach is to build a prediction model from a limited measurement data to predict the performance of all configurations as scalar values. However, it has been pointed out that there are different sources of uncertainty coming from the data collection or the modeling process, which can make the scalar predictions not certainly accurate. To address this problem, we propose a Bayesian deep learning based method, namely BDLPerf, that can incorporate uncertainty into the prediction model. BDLPerf can provide both scalar predictions for configurations' performance and the corresponding confidence intervals of these scalar predictions. We also develop a novel uncertainty calibration technique to ensure the reliability of the confidence intervals generated by a Bayesian prediction model. Finally, we suggest an efficient hyperparameter tuning technique so as to train the prediction model within a reasonable amount of time whilst achieving high accuracy. Our experimental results on 10 real-world systems show that BDLPerf achieves higher accuracy than existing approaches, in both scalar performance prediction and confidence interval estimation.
An Efficient Framework for Monitoring Subgroup Performance of Machine Learning Systems
Dec 16, 2022Monitoring machine learning systems post deployment is critical to ensure the reliability of the systems. Particularly importance is the problem of monitoring the performance of machine learning systems across all the data subgroups (subpopulations). In practice, this process could be prohibitively expensive as the number of data subgroups grows exponentially with the number of input features, and the process of labelling data to evaluate each subgroup's performance is costly. In this paper, we propose an efficient framework for monitoring subgroup performance of machine learning systems. Specifically, we aim to find the data subgroup with the worst performance using a limited number of labeled data. We mathematically formulate this problem as an optimization problem with an expensive black-box objective function, and then suggest to use Bayesian optimization to solve this problem. Our experimental results on various real-world datasets and machine learning systems show that our proposed framework can retrieve the worst-performing data subgroup effectively and efficiently.
ALT-MAS: A Data-Efficient Framework for Active Testing of Machine Learning Algorithms
Apr 11, 2021
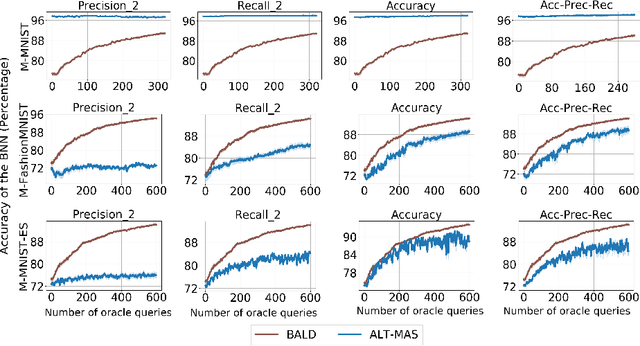
Machine learning models are being used extensively in many important areas, but there is no guarantee a model will always perform well or as its developers intended. Understanding the correctness of a model is crucial to prevent potential failures that may have significant detrimental impact in critical application areas. In this paper, we propose a novel framework to efficiently test a machine learning model using only a small amount of labeled test data. The idea is to estimate the metrics of interest for a model-under-test using Bayesian neural network (BNN). We develop a novel data augmentation method helping to train the BNN to achieve high accuracy. We also devise a theoretic information based sampling strategy to sample data points so as to achieve accurate estimations for the metrics of interest. Finally, we conduct an extensive set of experiments to test various machine learning models for different types of metrics. Our experiments show that the metrics estimations by our method are significantly better than existing baselines.