 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRejection via Learning Density Ratios
May 29, 2024
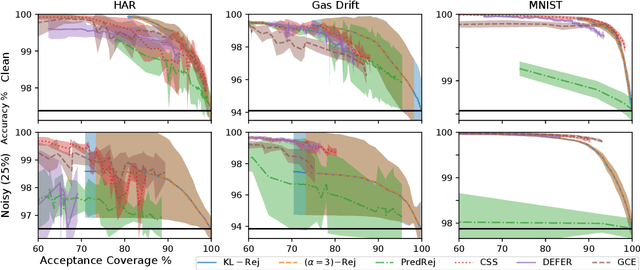

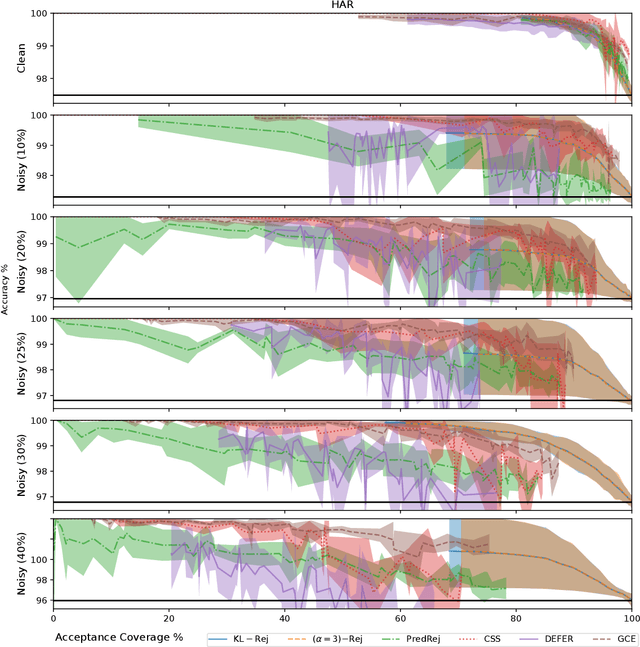
Classification with rejection emerges as a learning paradigm which allows models to abstain from making predictions. The predominant approach is to alter the supervised learning pipeline by augmenting typical loss functions, letting model rejection incur a lower loss than an incorrect prediction. Instead, we propose a different distributional perspective, where we seek to find an idealized data distribution which maximizes a pretrained model's performance. This can be formalized via the optimization of a loss's risk with a $ \phi$-divergence regularization term. Through this idealized distribution, a rejection decision can be made by utilizing the density ratio between this distribution and the data distribution. We focus on the setting where our $ \phi $-divergences are specified by the family of $ \alpha $-divergence. Our framework is tested empirically over clean and noisy datasets.
Unsupervised Cross-Lingual Transfer of Structured Predictors without Source Data
Oct 08, 2021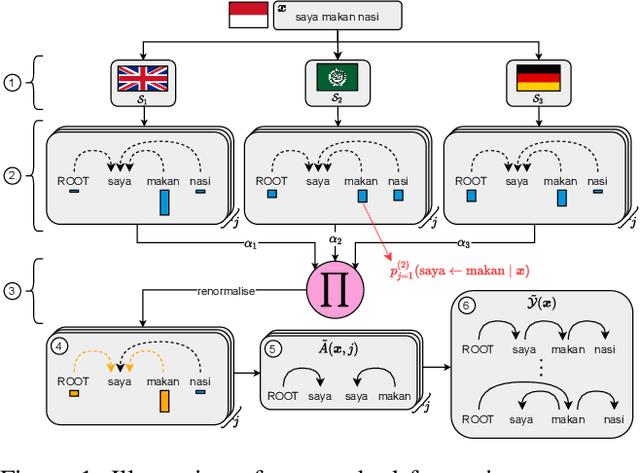
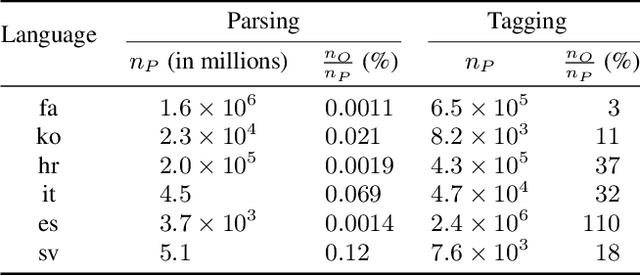
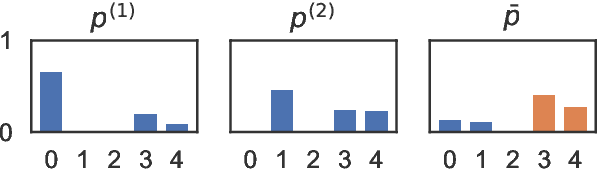
Providing technologies to communities or domains where training data is scarce or protected e.g., for privacy reasons, is becoming increasingly important. To that end, we generalise methods for unsupervised transfer from multiple input models for structured prediction. We show that the means of aggregating over the input models is critical, and that multiplying marginal probabilities of substructures to obtain high-probability structures for distant supervision is substantially better than taking the union of such structures over the input models, as done in prior work. Testing on 18 languages, we demonstrate that the method works in a cross-lingual setting, considering both dependency parsing and part-of-speech structured prediction problems. Our analyses show that the proposed method produces less noisy labels for the distant supervision.
Causal Bias Quantification for Continuous Treatment
Jun 17, 2021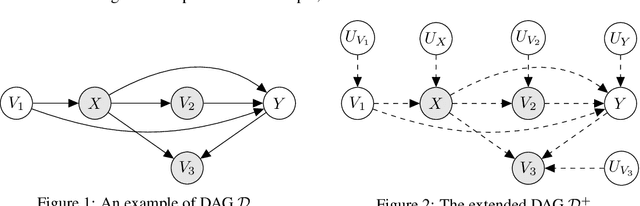
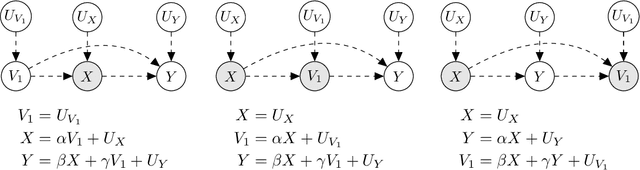
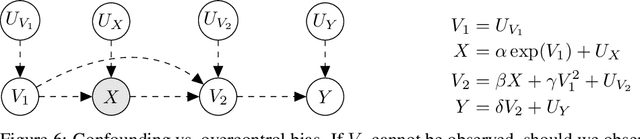
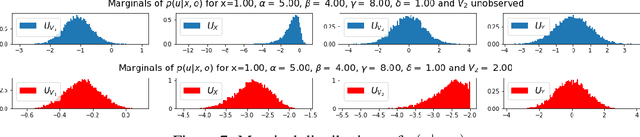
In this work we develop a novel characterization of marginal causal effect and causal bias in the continuous treatment setting. We show they can be expressed as an expectation with respect to a conditional probability distribution, which can be estimated via standard statistical and probabilistic methods. All terms in the expectations can be computed via automatic differentiation, also for highly non-linear models. We further develop a new complete criterion for identifiability of causal effects via covariate adjustment, showing the bias equals zero if the criterion is met. We study the effectiveness of our framework in three different scenarios: linear models under confounding, overcontrol and endogenous selection bias; a non-linear model where full identifiability cannot be achieved because of missing data; a simulated medical study of statins and atherosclerotic cardiovascular disease.
PPT: Parsimonious Parser Transfer for Unsupervised Cross-Lingual Adaptation
Jan 27, 2021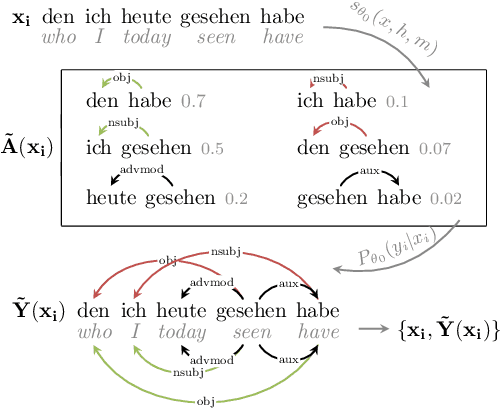
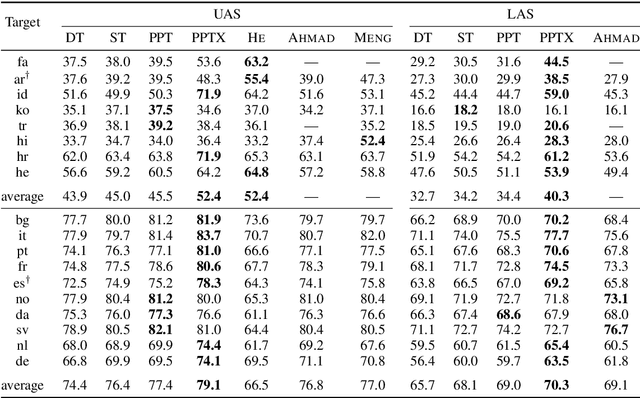
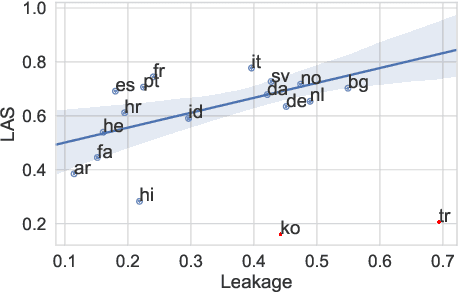
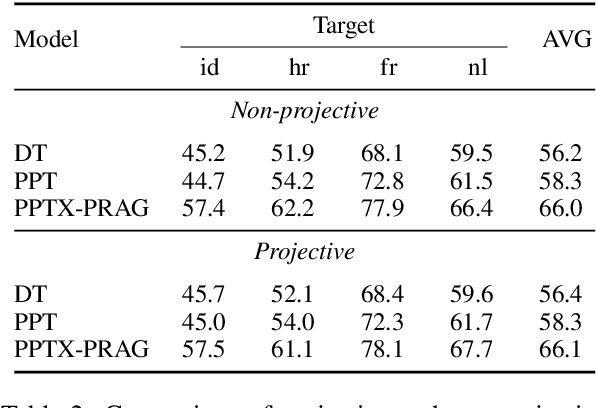
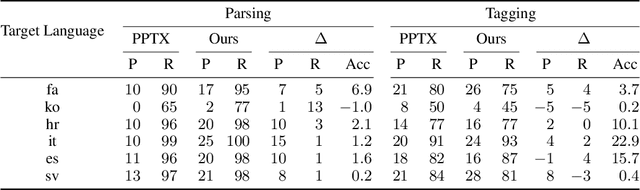
Cross-lingual transfer is a leading technique for parsing low-resource languages in the absence of explicit supervision. Simple `direct transfer' of a learned model based on a multilingual input encoding has provided a strong benchmark. This paper presents a method for unsupervised cross-lingual transfer that improves over direct transfer systems by using their output as implicit supervision as part of self-training on unlabelled text in the target language. The method assumes minimal resources and provides maximal flexibility by (a) accepting any pre-trained arc-factored dependency parser; (b) assuming no access to source language data; (c) supporting both projective and non-projective parsing; and (d) supporting multi-source transfer. With English as the source language, we show significant improvements over state-of-the-art transfer models on both distant and nearby languages, despite our conceptually simpler approach. We provide analyses of the choice of source languages for multi-source transfer, and the advantage of non-projective parsing. Our code is available online.
Grounding learning of modifier dynamics: An application to color naming
Sep 17, 2019


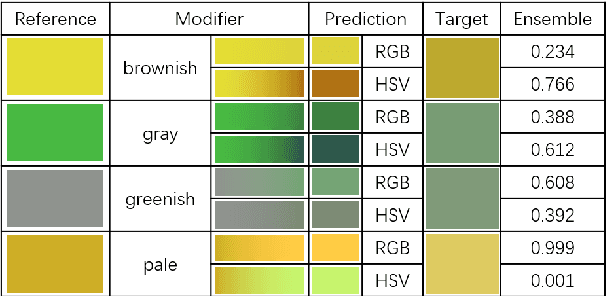
Grounding is crucial for natural language understanding. An important subtask is to understand modified color expressions, such as 'dirty blue'. We present a model of color modifiers that, compared with previous additive models in RGB space, learns more complex transformations. In addition, we present a model that operates in the HSV color space. We show that certain adjectives are better modeled in that space. To account for all modifiers, we train a hard ensemble model that selects a color space depending on the modifier color pair. Experimental results show significant and consistent improvements compared to the state-of-the-art baseline model.
A Stochastic Decoder for Neural Machine Translation
May 28, 2018
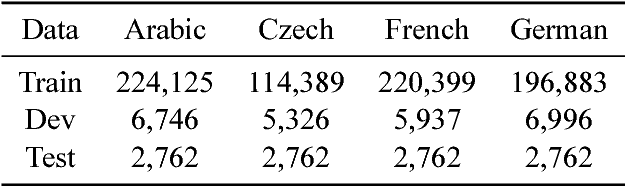
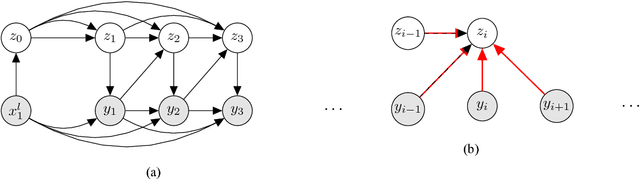

The process of translation is ambiguous, in that there are typically many valid trans- lations for a given sentence. This gives rise to significant variation in parallel cor- pora, however, most current models of machine translation do not account for this variation, instead treating the prob- lem as a deterministic process. To this end, we present a deep generative model of machine translation which incorporates a chain of latent variables, in order to ac- count for local lexical and syntactic varia- tion in parallel corpora. We provide an in- depth analysis of the pitfalls encountered in variational inference for training deep generative models. Experiments on sev- eral different language pairs demonstrate that the model consistently improves over strong baselines.