 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
The Power of Prompt Tuning for Low-Resource Semantic Parsing
Oct 16, 2021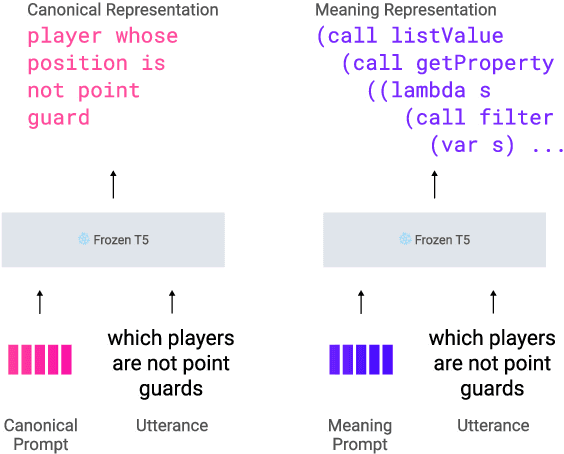
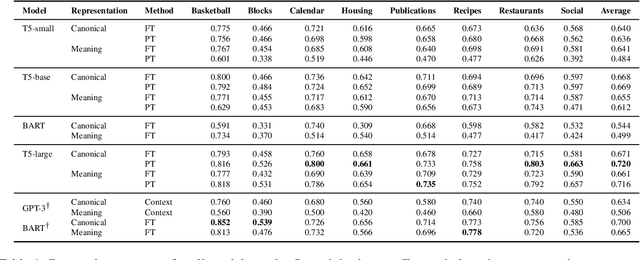

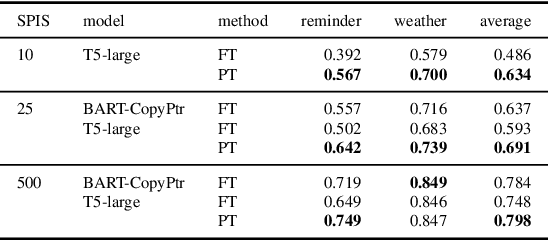
Prompt tuning has recently emerged as an effective method for adapting pre-trained language models to a number of language tasks. In this paper, we investigate prompt tuning for semantic parsing, the task of mapping natural language utterances onto formal meaning representations. For large T5 models we find (i) that prompt tuning significantly outperforms fine-tuning in the low data regime and (ii) that canonicalization -- i.e. naturalizing the meaning representations -- barely improves performance. This last result is surprising as it suggests that large T5 models can be modulated to generate sequences that are far from the pre-training distribution.
PICARD: Parsing Incrementally for Constrained Auto-Regressive Decoding from Language Models
Sep 10, 2021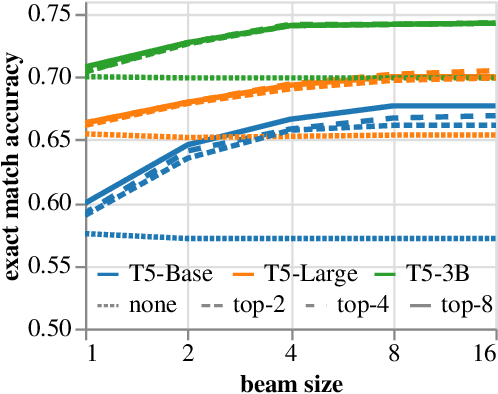
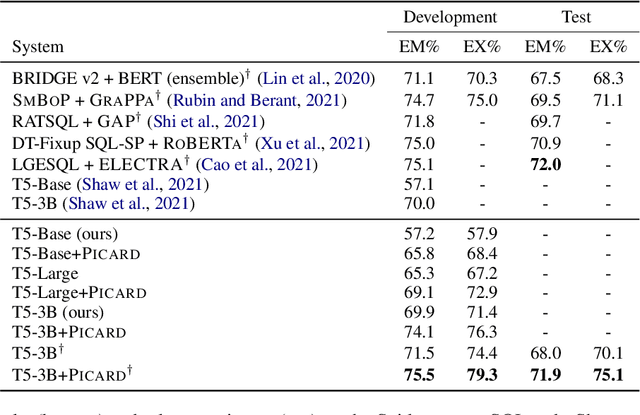
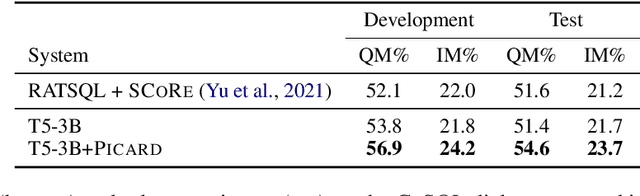
Large pre-trained language models for textual data have an unconstrained output space; at each decoding step, they can produce any of 10,000s of sub-word tokens. When fine-tuned to target constrained formal languages like SQL, these models often generate invalid code, rendering it unusable. We propose PICARD (code and trained models available at https://github.com/ElementAI/picard), a method for constraining auto-regressive decoders of language models through incremental parsing. PICARD helps to find valid output sequences by rejecting inadmissible tokens at each decoding step. On the challenging Spider and CoSQL text-to-SQL translation tasks, we show that PICARD transforms fine-tuned T5 models with passable performance into state-of-the-art solutions.
DECoVaC: Design of Experiments with Controlled Variability Components
Sep 21, 2019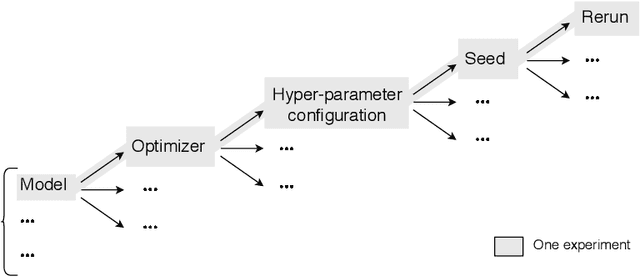
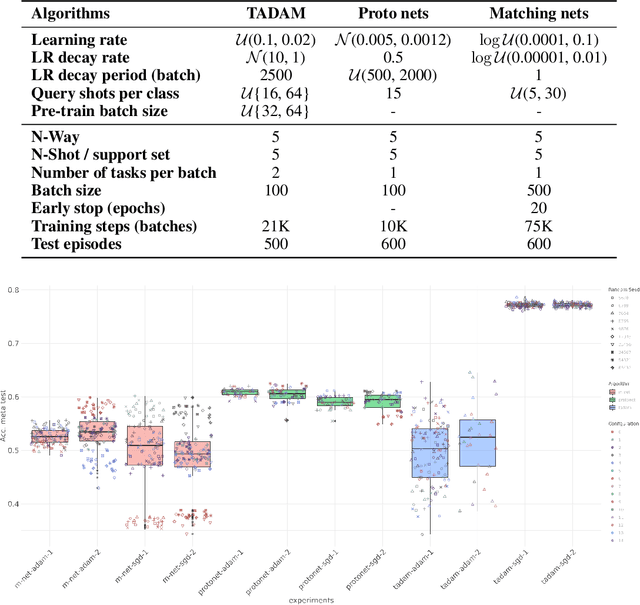

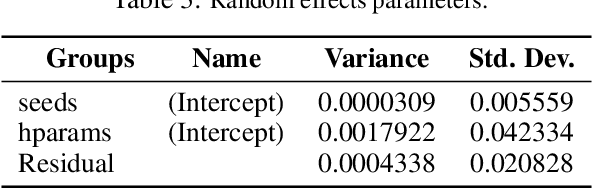
Reproducible research in Machine Learning has seen a salutary abundance of progress lately: workflows, transparency, and statistical analysis of validation and test performance. We build on these efforts and take them further. We offer a principled experimental design methodology, based on linear mixed models, to study and separate the effects of multiple factors of variation in machine learning experiments. This approach allows to account for the effects of architecture, optimizer, hyper-parameters, intentional randomization, as well as unintended lack of determinism across reruns. We illustrate that methodology by analyzing Matching Networks, Prototypical Networks and TADAM on the miniImagenet dataset.