Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Power of Prompt Tuning for Low-Resource Semantic Parsing
Paper and Code
Oct 16, 2021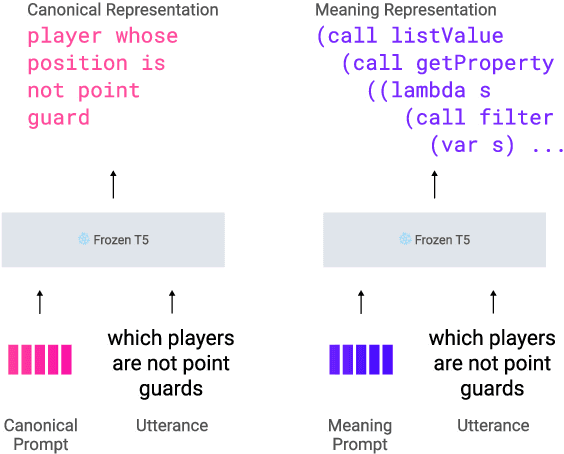
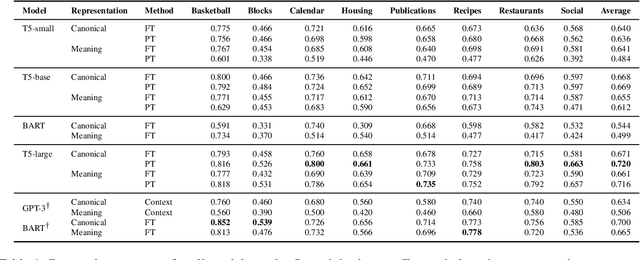

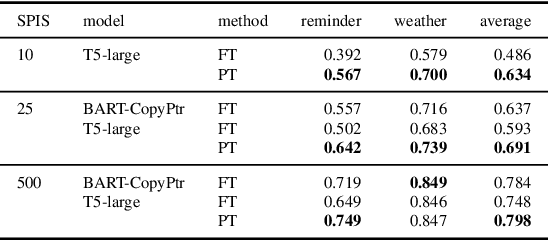
Prompt tuning has recently emerged as an effective method for adapting pre-trained language models to a number of language tasks. In this paper, we investigate prompt tuning for semantic parsing, the task of mapping natural language utterances onto formal meaning representations. For large T5 models we find (i) that prompt tuning significantly outperforms fine-tuning in the low data regime and (ii) that canonicalization -- i.e. naturalizing the meaning representations -- barely improves performance. This last result is surprising as it suggests that large T5 models can be modulated to generate sequences that are far from the pre-training distribution.
View paper on