 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe student becomes the master: Matching GPT3 on Scientific Factual Error Correction
Paper and Code
May 24, 2023
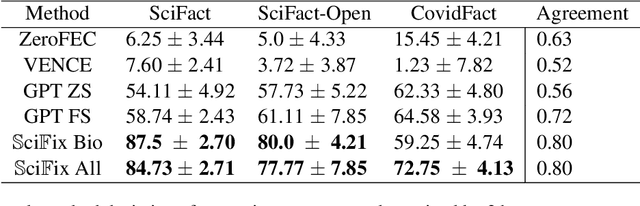

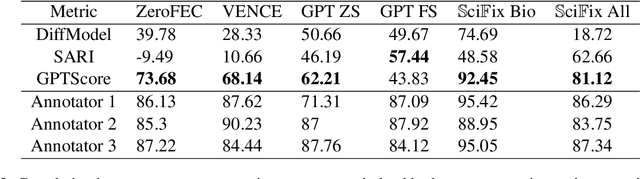
Due to the prohibitively high cost of creating error correction datasets, most Factual Claim Correction methods rely on a powerful verification model to guide the correction process. This leads to a significant drop in performance in domains like Scientific Claim Correction, where good verification models do not always exist. In this work, we introduce a claim correction system that makes no domain assumptions and does not require a verifier but is able to outperform existing methods by an order of magnitude -- achieving 94% correction accuracy on the SciFact dataset, and 62.5% on the SciFact-Open dataset, compared to the next best methods 0.5% and 1.50% respectively. Our method leverages the power of prompting with LLMs during training to create a richly annotated dataset that can be used for fully supervised training and regularization. We additionally use a claim-aware decoding procedure to improve the quality of corrected claims. Our method is competitive with the very LLM that was used to generate the annotated dataset -- with GPT3.5 achieving 89.5% and 60% correction accuracy on SciFact and SciFact-Open, despite using 1250 times as many parameters as our model.