 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Optimal Transport for Enhanced Offline Reinforcement Learning in Surgical Robotic Environments
Oct 13, 2023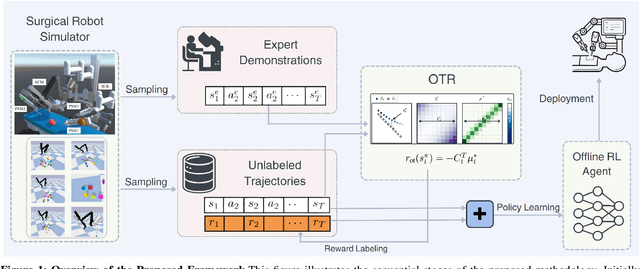
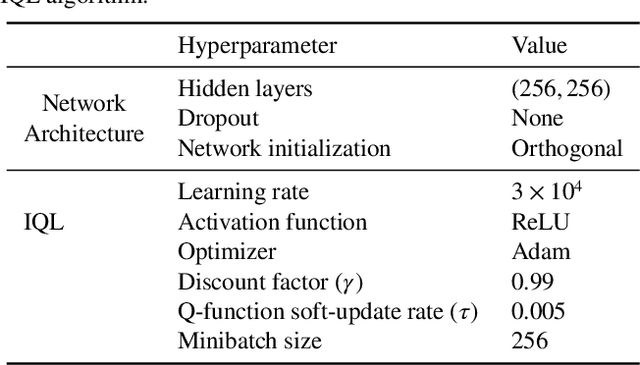


Most Reinforcement Learning (RL) methods are traditionally studied in an active learning setting, where agents directly interact with their environments, observe action outcomes, and learn through trial and error. However, allowing partially trained agents to interact with real physical systems poses significant challenges, including high costs, safety risks, and the need for constant supervision. Offline RL addresses these cost and safety concerns by leveraging existing datasets and reducing the need for resource-intensive real-time interactions. Nevertheless, a substantial challenge lies in the demand for these datasets to be meticulously annotated with rewards. In this paper, we introduce Optimal Transport Reward (OTR) labelling, an innovative algorithm designed to assign rewards to offline trajectories, using a small number of high-quality expert demonstrations. The core principle of OTR involves employing Optimal Transport (OT) to calculate an optimal alignment between an unlabeled trajectory from the dataset and an expert demonstration. This alignment yields a similarity measure that is effectively interpreted as a reward signal. An offline RL algorithm can then utilize these reward signals to learn a policy. This approach circumvents the need for handcrafted rewards, unlocking the potential to harness vast datasets for policy learning. Leveraging the SurRoL simulation platform tailored for surgical robot learning, we generate datasets and employ them to train policies using the OTR algorithm. By demonstrating the efficacy of OTR in a different domain, we emphasize its versatility and its potential to expedite RL deployment across a wide range of fields.
A Survey of Imitation Learning: Algorithms, Recent Developments, and Challenges
Sep 05, 2023In recent years, the development of robotics and artificial intelligence (AI) systems has been nothing short of remarkable. As these systems continue to evolve, they are being utilized in increasingly complex and unstructured environments, such as autonomous driving, aerial robotics, and natural language processing. As a consequence, programming their behaviors manually or defining their behavior through reward functions (as done in reinforcement learning (RL)) has become exceedingly difficult. This is because such environments require a high degree of flexibility and adaptability, making it challenging to specify an optimal set of rules or reward signals that can account for all possible situations. In such environments, learning from an expert's behavior through imitation is often more appealing. This is where imitation learning (IL) comes into play - a process where desired behavior is learned by imitating an expert's behavior, which is provided through demonstrations. This paper aims to provide an introduction to IL and an overview of its underlying assumptions and approaches. It also offers a detailed description of recent advances and emerging areas of research in the field. Additionally, the paper discusses how researchers have addressed common challenges associated with IL and provides potential directions for future research. Overall, the goal of the paper is to provide a comprehensive guide to the growing field of IL in robotics and AI.
DeepNorm-A Deep Learning Approach to Text Normalization
Dec 17, 2017

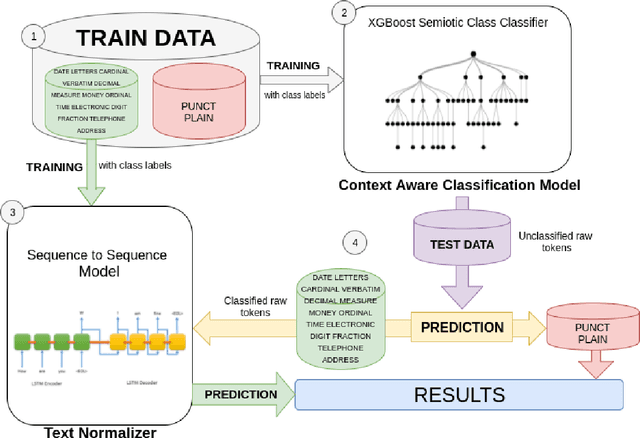
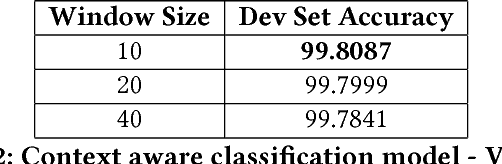
This paper presents an simple yet sophisticated approach to the challenge by Sproat and Jaitly (2016)- given a large corpus of written text aligned to its normalized spoken form, train an RNN to learn the correct normalization function. Text normalization for a token seems very straightforward without it's context. But given the context of the used token and then normalizing becomes tricky for some classes. We present a novel approach in which the prediction of our classification algorithm is used by our sequence to sequence model to predict the normalized text of the input token. Our approach takes very less time to learn and perform well unlike what has been reported by Google (5 days on their GPU cluster). We have achieved an accuracy of 97.62 which is impressive given the resources we use. Our approach is using the best of both worlds, gradient boosting - state of the art in most classification tasks and sequence to sequence learning - state of the art in machine translation. We present our experiments and report results with various parameter settings.