 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepNorm-A Deep Learning Approach to Text Normalization
Paper and Code


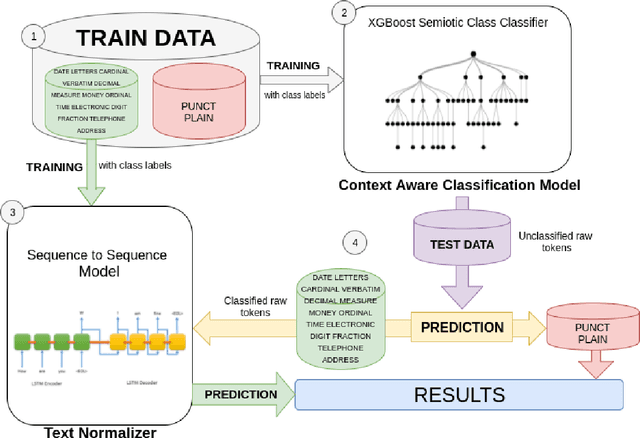
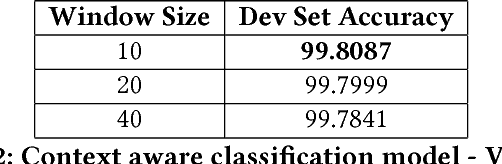
This paper presents an simple yet sophisticated approach to the challenge by Sproat and Jaitly (2016)- given a large corpus of written text aligned to its normalized spoken form, train an RNN to learn the correct normalization function. Text normalization for a token seems very straightforward without it's context. But given the context of the used token and then normalizing becomes tricky for some classes. We present a novel approach in which the prediction of our classification algorithm is used by our sequence to sequence model to predict the normalized text of the input token. Our approach takes very less time to learn and perform well unlike what has been reported by Google (5 days on their GPU cluster). We have achieved an accuracy of 97.62 which is impressive given the resources we use. Our approach is using the best of both worlds, gradient boosting - state of the art in most classification tasks and sequence to sequence learning - state of the art in machine translation. We present our experiments and report results with various parameter settings.