 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Optimal Transport for Enhanced Offline Reinforcement Learning in Surgical Robotic Environments
Paper and Code
Oct 13, 2023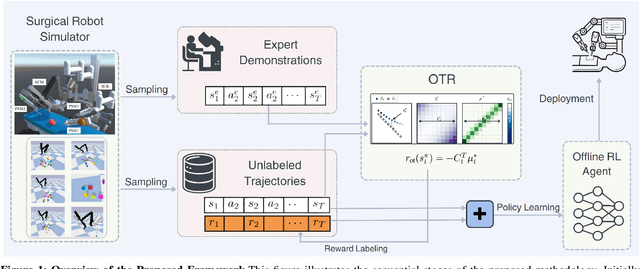
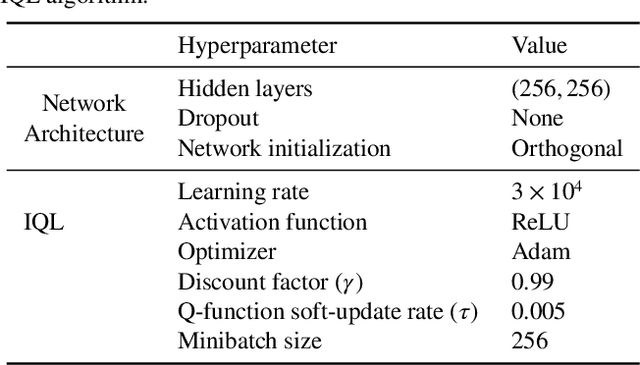


Most Reinforcement Learning (RL) methods are traditionally studied in an active learning setting, where agents directly interact with their environments, observe action outcomes, and learn through trial and error. However, allowing partially trained agents to interact with real physical systems poses significant challenges, including high costs, safety risks, and the need for constant supervision. Offline RL addresses these cost and safety concerns by leveraging existing datasets and reducing the need for resource-intensive real-time interactions. Nevertheless, a substantial challenge lies in the demand for these datasets to be meticulously annotated with rewards. In this paper, we introduce Optimal Transport Reward (OTR) labelling, an innovative algorithm designed to assign rewards to offline trajectories, using a small number of high-quality expert demonstrations. The core principle of OTR involves employing Optimal Transport (OT) to calculate an optimal alignment between an unlabeled trajectory from the dataset and an expert demonstration. This alignment yields a similarity measure that is effectively interpreted as a reward signal. An offline RL algorithm can then utilize these reward signals to learn a policy. This approach circumvents the need for handcrafted rewards, unlocking the potential to harness vast datasets for policy learning. Leveraging the SurRoL simulation platform tailored for surgical robot learning, we generate datasets and employ them to train policies using the OTR algorithm. By demonstrating the efficacy of OTR in a different domain, we emphasize its versatility and its potential to expedite RL deployment across a wide range of fields.