 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning Approach for Detecting Psychological Distress in Brexit Tweets
Jan 25, 2021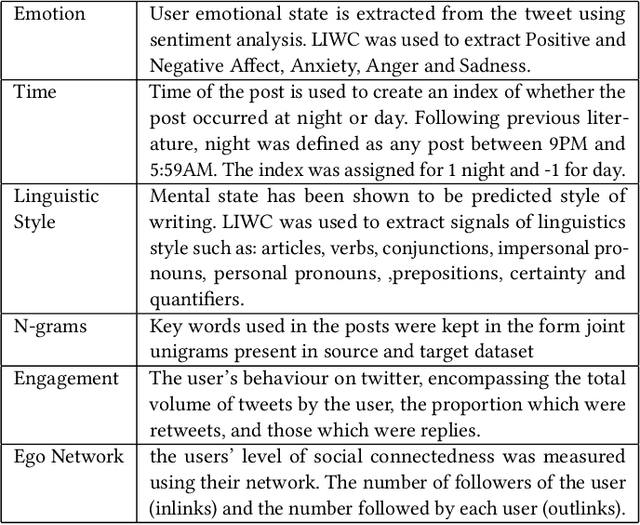
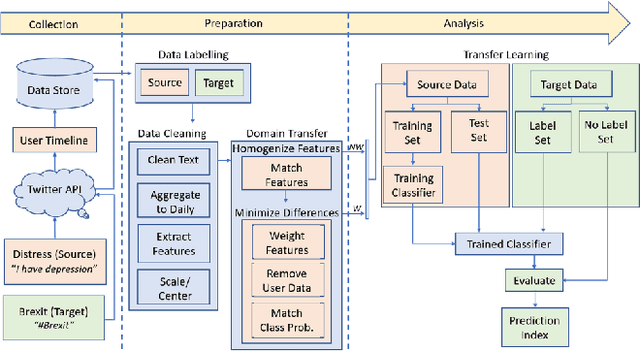
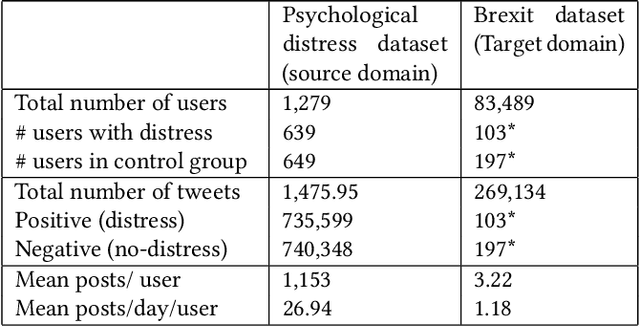
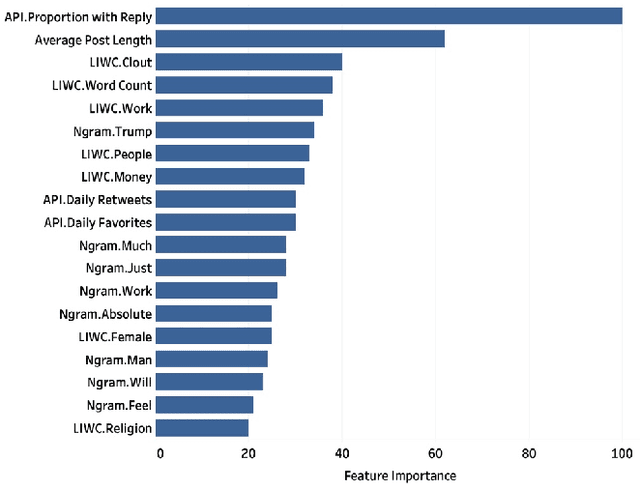
In 2016, United Kingdom (UK) citizens voted to leave the European Union (EU), which was officially implemented in 2020. During this period, UK residents experienced a great deal of uncertainty around the UK's continued relationship with the EU. Many people have used social media platforms to express their emotions about this critical event. Sentiment analysis has been recently considered as an important tool for detecting mental well-being in Twitter contents. However, detecting the psychological distress status in political-related tweets is a challenging task due to the lack of explicit sentences describing the depressive or anxiety status. To address this problem, this paper leverages a transfer learning approach for sentiment analysis to measure the non-clinical psychological distress status in Brexit tweets. The framework transfers the knowledge learnt from self-reported psychological distress tweets (source domain) to detect the distress status in Brexit tweets (target domain). The framework applies a domain adaptation technique to decrease the impact of negative transfer between source and target domains. The paper also introduces a Brexit distress index that can be used to detect levels of psychological distress of individuals in Brexit tweets. We design an experiment that includes data from both domains. The proposed model is able to detect the non-clinical psychological distress status in Brexit tweets with an accuracy of 66% and 62% on the source and target domains, respectively.
Embed2Detect: Temporally Clustered Embedded Words for Event Detection in Social Media
Jun 11, 2020


Event detection in social media refers to automatic identification of important information shared in social media platforms on a certain time. Considering the dynamic nature and high volume of data production in data streams, it is impractical to filter the events manually. Therefore, it is important to have an automated mechanism to detect events in order to utilise social media data effectively. Analysing the available literature, most of the existing event detection methods are only focused on statistical and syntactical features in data, even though the underlying semantics are also important for an effective information retrieval from text, because they describe the connections between words and their meanings. In this paper, we propose a novel method termed Embed2Detect for event detection in social media by combining the characteristics in prediction-based word embeddings and hierarchical agglomerative clustering. The adoption of prediction-based word embeddings incorporates the semantical features in the text to overcome a major limitation available with previous approaches. This method is experimented on two recent social media data sets which represent the sports and politics domains. The results obtained from the experiments reveal that our approach is capable of effective and efficient event detection with the proof of significant improvements over baselines. For sports data set, Embed2Detect achieved 30% higher F-measure than the best performed baseline method and for political data set, it was an increase by 36%.
A Survey of Data Mining Techniques for Social Media Analysis
Apr 16, 2014

Social network has gained remarkable attention in the last decade. Accessing social network sites such as Twitter, Facebook LinkedIn and Google+ through the internet and the web 2.0 technologies has become more affordable. People are becoming more interested in and relying on social network for information, news and opinion of other users on diverse subject matters. The heavy reliance on social network sites causes them to generate massive data characterised by three computational issues namely; size, noise and dynamism. These issues often make social network data very complex to analyse manually, resulting in the pertinent use of computational means of analysing them. Data mining provides a wide range of techniques for detecting useful knowledge from massive datasets like trends, patterns and rules [44]. Data mining techniques are used for information retrieval, statistical modelling and machine learning. These techniques employ data pre-processing, data analysis, and data interpretation processes in the course of data analysis. This survey discusses different data mining techniques used in mining diverse aspects of the social network over decades going from the historical techniques to the up-to-date models, including our novel technique named TRCM. All the techniques covered in this survey are listed in the Table.1 including the tools employed as well as names of their authors.
* 25 pages, 9 figures