 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Generalized Offensive Language Identification
Jul 26, 2024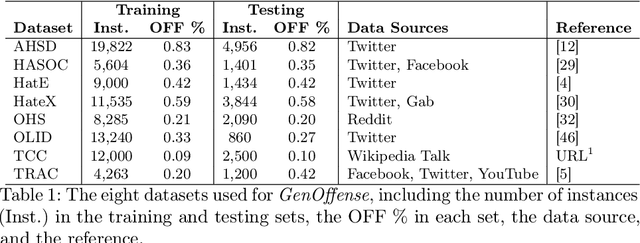
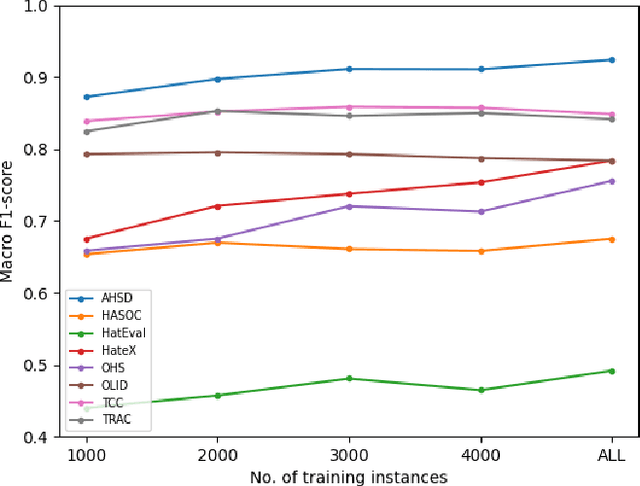
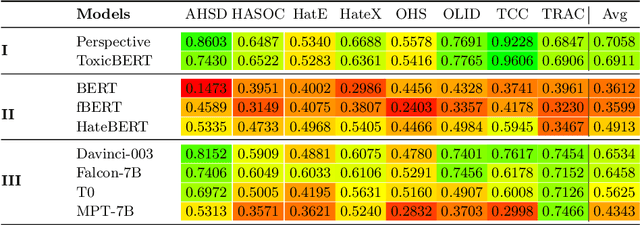

The prevalence of offensive content on the internet, encompassing hate speech and cyberbullying, is a pervasive issue worldwide. Consequently, it has garnered significant attention from the machine learning (ML) and natural language processing (NLP) communities. As a result, numerous systems have been developed to automatically identify potentially harmful content and mitigate its impact. These systems can follow two approaches; (1) Use publicly available models and application endpoints, including prompting large language models (LLMs) (2) Annotate datasets and train ML models on them. However, both approaches lack an understanding of how generalizable they are. Furthermore, the applicability of these systems is often questioned in off-domain and practical environments. This paper empirically evaluates the generalizability of offensive language detection models and datasets across a novel generalized benchmark. We answer three research questions on generalizability. Our findings will be useful in creating robust real-world offensive language detection systems.