 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Training Efficiency and Reducing Maintenance Costs via Language Specific Model Merging
Jan 23, 2026Fine-tuning a task-specific multilingual large language model (LLM) involves training the model on a multilingual dataset with examples in all the required languages. Updating one or more supported languages with additional data or adding support for a new language involves retraining the model, which can be computationally inefficient and creates a severe maintenance bottleneck. Recent research on merging multilingual multitask models has shown promise in terms of improved quality, but its computational and maintenance efficiency remains unstudied. In this work, we provide the first focused analysis of this merging strategy from an efficiency perspective, evaluating it across three independent tasks. We demonstrate significant efficiency gains while maintaining parity in terms of quality: this merging approach reduces the initial training time by up to 50\%. We also demonstrate that updating an individual language and re-merging as part of model maintenance reduces training costs by more than 60\%, compared to re-training the full multilingual model. We show this on both public and proprietary industry datasets confirming that the approach works well for industrial use cases in addition to academic settings already studied in previous work.
Exploring the Performance of Large Language Models on Subjective Span Identification Tasks
Jan 02, 2026Identifying relevant text spans is important for several downstream tasks in NLP, as it contributes to model explainability. While most span identification approaches rely on relatively smaller pre-trained language models like BERT, a few recent approaches have leveraged the latest generation of Large Language Models (LLMs) for the task. Current work has focused on explicit span identification like Named Entity Recognition (NER), while more subjective span identification with LLMs in tasks like Aspect-based Sentiment Analysis (ABSA) has been underexplored. In this paper, we fill this important gap by presenting an evaluation of the performance of various LLMs on text span identification in three popular tasks, namely sentiment analysis, offensive language identification, and claim verification. We explore several LLM strategies like instruction tuning, in-context learning, and chain of thought. Our results indicate underlying relationships within text aid LLMs in identifying precise text spans.
Claim Verification in the Age of Large Language Models: A Survey
Aug 26, 2024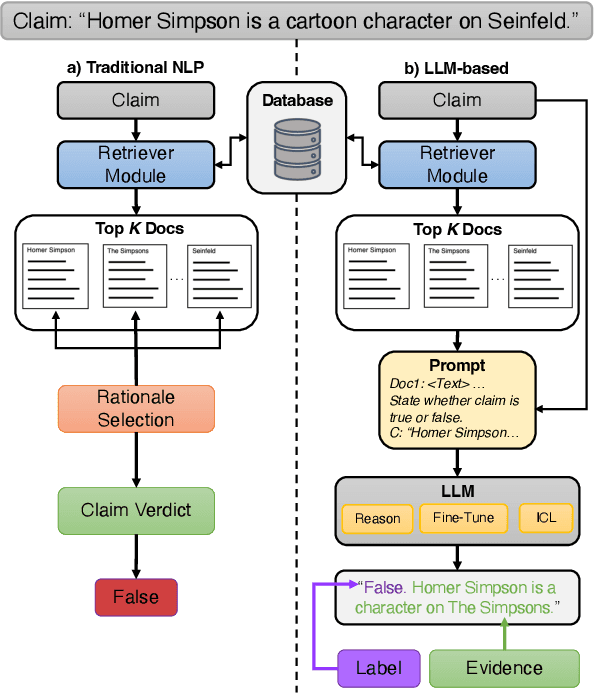
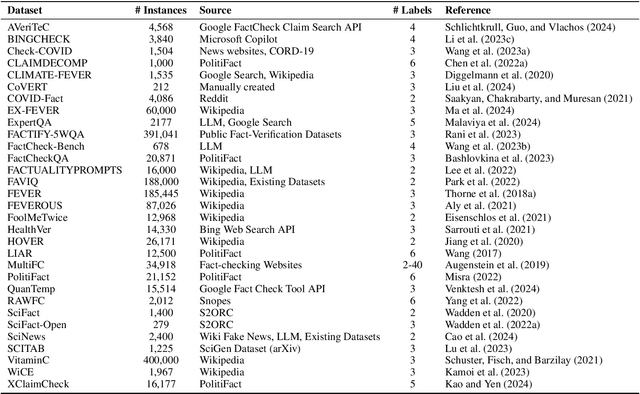
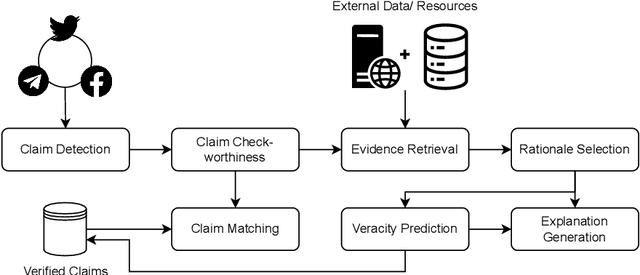
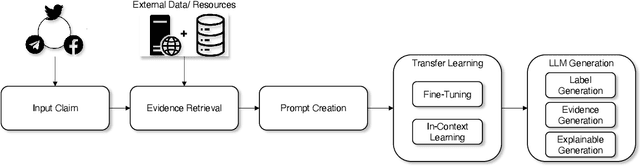
The large and ever-increasing amount of data available on the Internet coupled with the laborious task of manual claim and fact verification has sparked the interest in the development of automated claim verification systems. Several deep learning and transformer-based models have been proposed for this task over the years. With the introduction of Large Language Models (LLMs) and their superior performance in several NLP tasks, we have seen a surge of LLM-based approaches to claim verification along with the use of novel methods such as Retrieval Augmented Generation (RAG). In this survey, we present a comprehensive account of recent claim verification frameworks using LLMs. We describe the different components of the claim verification pipeline used in these frameworks in detail including common approaches to retrieval, prompting, and fine-tuning. Finally, we describe publicly available English datasets created for this task.
Towards Generalized Offensive Language Identification
Jul 26, 2024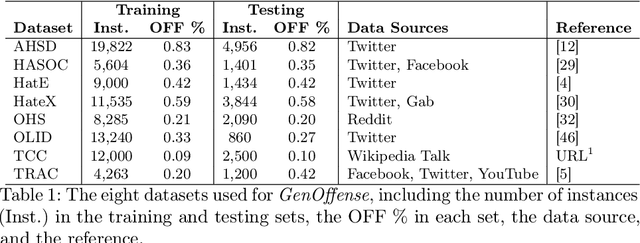
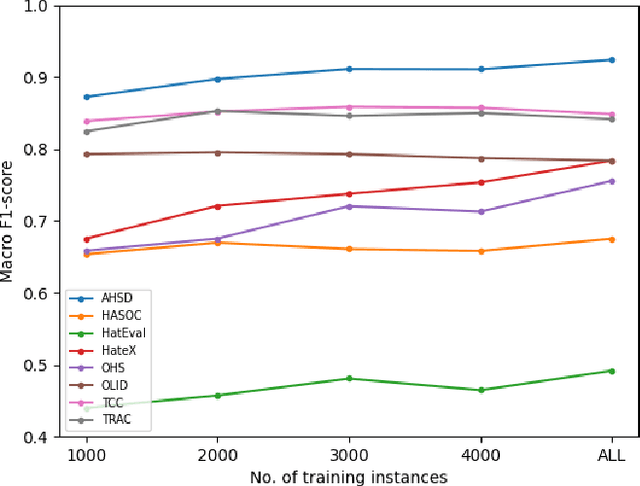
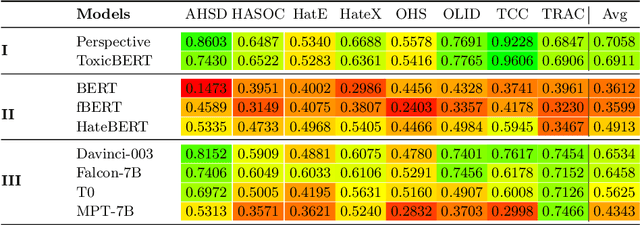

The prevalence of offensive content on the internet, encompassing hate speech and cyberbullying, is a pervasive issue worldwide. Consequently, it has garnered significant attention from the machine learning (ML) and natural language processing (NLP) communities. As a result, numerous systems have been developed to automatically identify potentially harmful content and mitigate its impact. These systems can follow two approaches; (1) Use publicly available models and application endpoints, including prompting large language models (LLMs) (2) Annotate datasets and train ML models on them. However, both approaches lack an understanding of how generalizable they are. Furthermore, the applicability of these systems is often questioned in off-domain and practical environments. This paper empirically evaluates the generalizability of offensive language detection models and datasets across a novel generalized benchmark. We answer three research questions on generalizability. Our findings will be useful in creating robust real-world offensive language detection systems.
Classifying Human-Generated and AI-Generated Election Claims in Social Media
Apr 26, 2024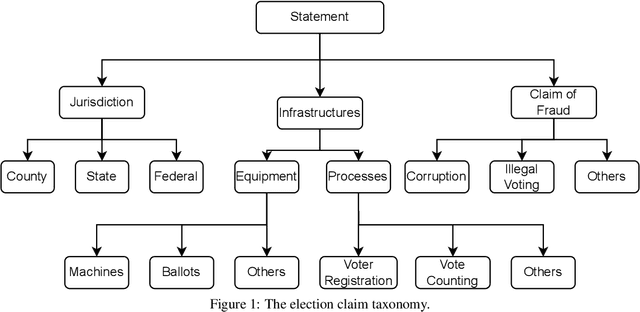
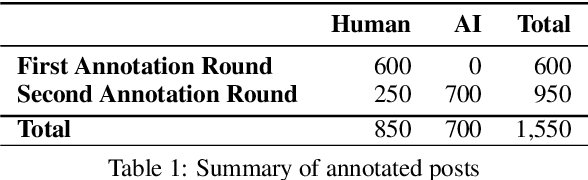

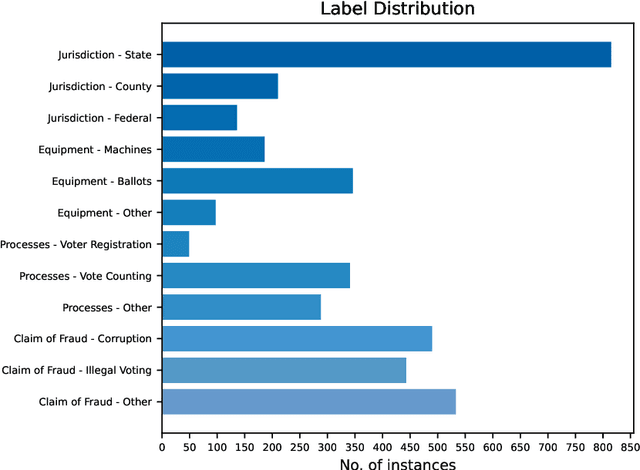
Politics is one of the most prevalent topics discussed on social media platforms, particularly during major election cycles, where users engage in conversations about candidates and electoral processes. Malicious actors may use this opportunity to disseminate misinformation to undermine trust in the electoral process. The emergence of Large Language Models (LLMs) exacerbates this issue by enabling malicious actors to generate misinformation at an unprecedented scale. Artificial intelligence (AI)-generated content is often indistinguishable from authentic user content, raising concerns about the integrity of information on social networks. In this paper, we present a novel taxonomy for characterizing election-related claims. This taxonomy provides an instrument for analyzing election-related claims, with granular categories related to jurisdiction, equipment, processes, and the nature of claims. We introduce ElectAI, a novel benchmark dataset that consists of 9,900 tweets, each labeled as human- or AI-generated. For AI-generated tweets, the specific LLM variant that produced them is specified. We annotated a subset of 1,550 tweets using the proposed taxonomy to capture the characteristics of election-related claims. We explored the capabilities of LLMs in extracting the taxonomy attributes and trained various machine learning models using ElectAI to distinguish between human- and AI-generated posts and identify the specific LLM variant.