 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaiBaam: A Multi-Dialectal Bavarian Universal Dependency Treebank
Paper and Code
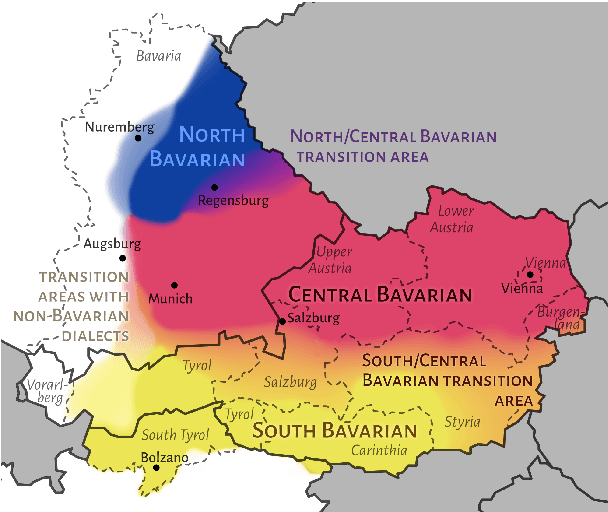
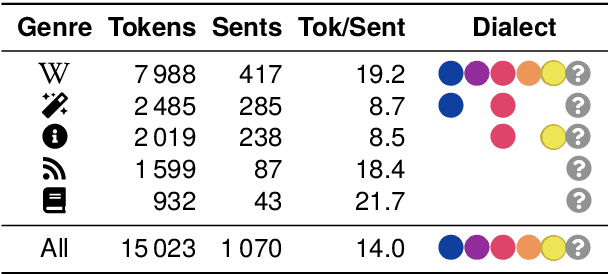
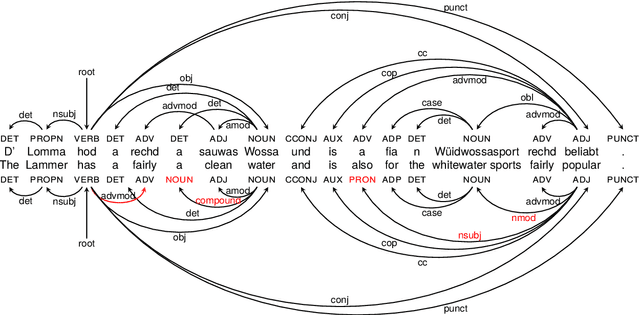
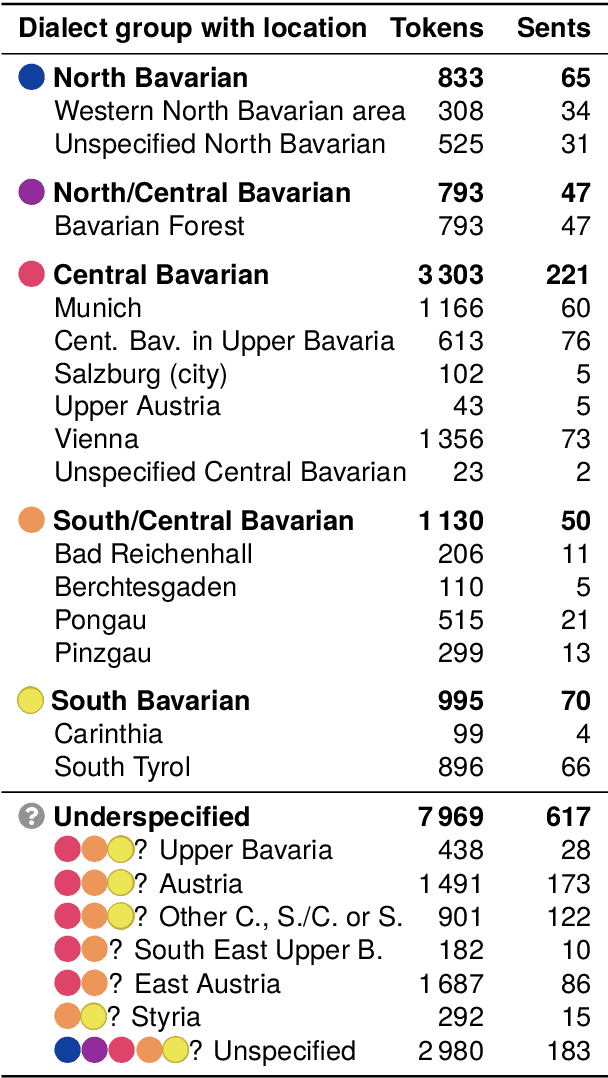
Despite the success of the Universal Dependencies (UD) project exemplified by its impressive language breadth, there is still a lack in `within-language breadth': most treebanks focus on standard languages. Even for German, the language with the most annotations in UD, so far no treebank exists for one of its language varieties spoken by over 10M people: Bavarian. To contribute to closing this gap, we present the first multi-dialect Bavarian treebank (MaiBaam) manually annotated with part-of-speech and syntactic dependency information in UD, covering multiple text genres (wiki, fiction, grammar examples, social, non-fiction). We highlight the morphosyntactic differences between the closely-related Bavarian and German and showcase the rich variability of speakers' orthographies. Our corpus includes 15k tokens, covering dialects from all Bavarian-speaking areas spanning three countries. We provide baseline parsing and POS tagging results, which are lower than results obtained on German and vary substantially between different graph-based parsers. To support further research on Bavarian syntax, we make our dataset, language-specific guidelines and code publicly available.