 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Speech-to-Text Systems with PennSound
Apr 08, 2025A random sample of nearly 10 hours of speech from PennSound, the world's largest online collection of poetry readings and discussions, was used as a benchmark to evaluate several commercial and open-source speech-to-text systems. PennSound's wide variation in recording conditions and speech styles makes it a good representative for many other untranscribed audio collections. Reference transcripts were created by trained annotators, and system transcripts were produced from AWS, Azure, Google, IBM, NeMo, Rev.ai, Whisper, and Whisper.cpp. Based on word error rate, Rev.ai was the top performer, and Whisper was the top open source performer (as long as hallucinations were avoided). AWS had the best diarization error rates among three systems. However, WER and DER differences were slim, and various tradeoffs may motivate choosing different systems for different end users. We also examine the issue of hallucinations in Whisper. Users of Whisper should be cautioned to be aware of runtime options, and whether the speed vs accuracy trade off is acceptable.
Improved POS tagging for spontaneous, clinical speech using data augmentation
Jul 11, 2023



This paper addresses the problem of improving POS tagging of transcripts of speech from clinical populations. In contrast to prior work on parsing and POS tagging of transcribed speech, we do not make use of an in domain treebank for training. Instead, we train on an out of domain treebank of newswire using data augmentation techniques to make these structures resemble natural, spontaneous speech. We trained a parser with and without the augmented data and tested its performance using manually validated POS tags in clinical speech produced by patients with various types of neurodegenerative conditions.
Inferring Pitch from Coarse Spectral Features
Apr 10, 2022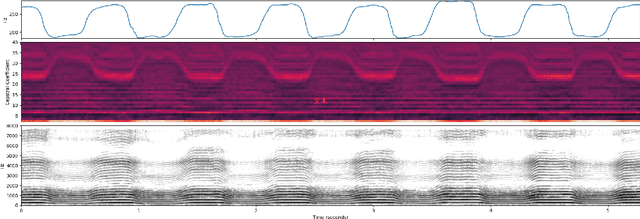
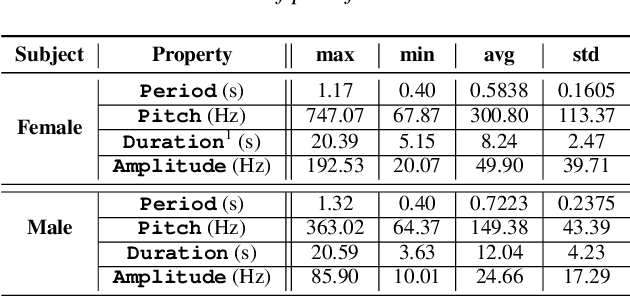
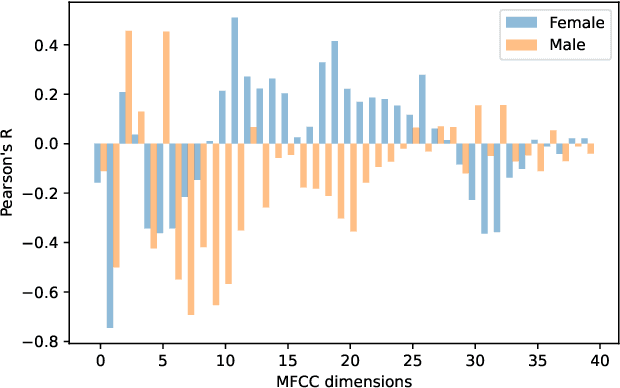
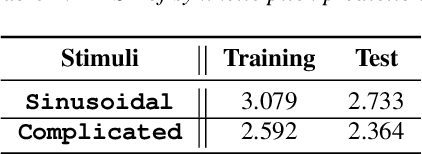
Fundamental frequency (F0) has long been treated as the physical definition of "pitch" in phonetic analysis. But there have been many demonstrations that F0 is at best an approximation to pitch, both in production and in perception: pitch is not F0, and F0 is not pitch. Changes in the pitch involve many articulatory and acoustic covariates; pitch perception often deviates from what F0 analysis predicts; and in fact, quasi-periodic signals from a single voice source are often incompletely characterized by an attempt to define a single time-varying F0. In this paper, we find strong support for the existence of covariates for pitch in aspects of relatively coarse spectra, in which an overtone series is not available. Thus linear regression can predict the pitch of simple vocalizations, produced by an articulatory synthesizer or by human, from single frames of such coarse spectra. Across speakers, and in more complex vocalizations, our experiments indicate that the covariates are not quite so simple, though apparently still available for more sophisticated modeling. On this basis, we propose that the field needs a better way of thinking about speech pitch, just as celestial mechanics requires us to go beyond Newton's point mass approximations to heavenly bodies.
A Part-of-Speech Tagger for Yiddish: First Steps in Tagging the Yiddish Book Center Corpus
Apr 03, 2022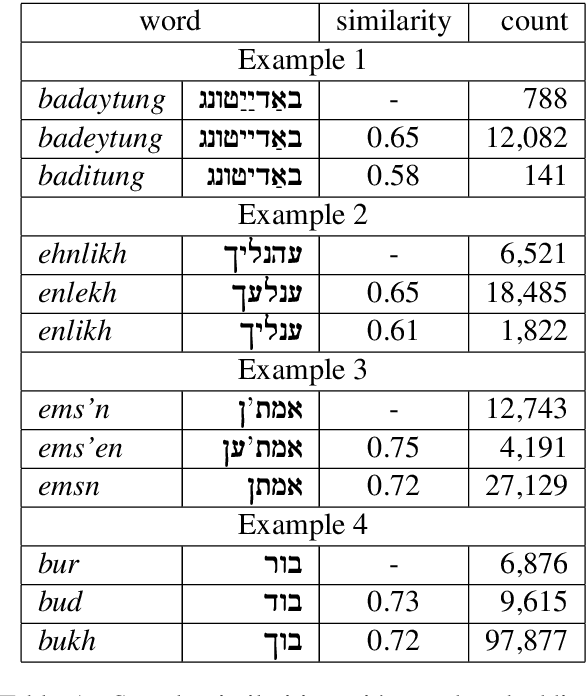
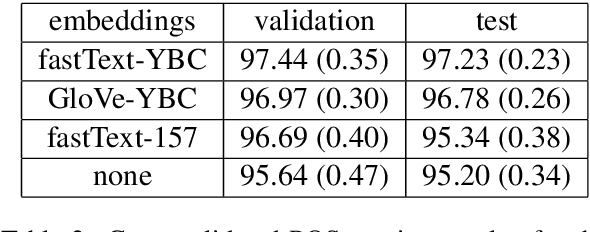
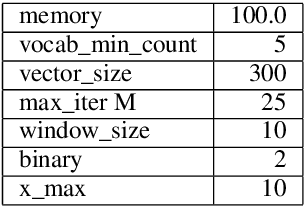
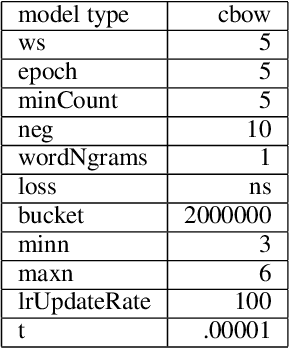
We describe the construction and evaluation of a part-of-speech tagger for Yiddish (the first one, to the best of our knowledge). This is the first step in a larger project of automatically assigning part-of-speech tags and syntactic structure to Yiddish text for purposes of linguistic research. We combine two resources for the current work - an 80K word subset of the Penn Parsed Corpus of Historical Yiddish (PPCHY) (Santorini, 2021) and 650 million words of OCR'd Yiddish text from the Yiddish Book Center (YBC). We compute word embeddings on the YBC corpus, and these embeddings are used with a tagger model trained and evaluated on the PPCHY. Yiddish orthography in the YBC corpus has many spelling inconsistencies, and we present some evidence that even simple non-contextualized embeddings are able to capture the relationships among spelling variants without the need to first "standardize" the corpus. We evaluate the tagger performance on a 10-fold cross-validation split, with and without the embeddings, showing that the embeddings improve tagger performance. However, a great deal of work remains to be done, and we conclude by discussing some next steps, including the need for additional annotated training and test data.
Penn-Helsinki Parsed Corpus of Early Modern English: First Parsing Results and Analysis
Dec 15, 2021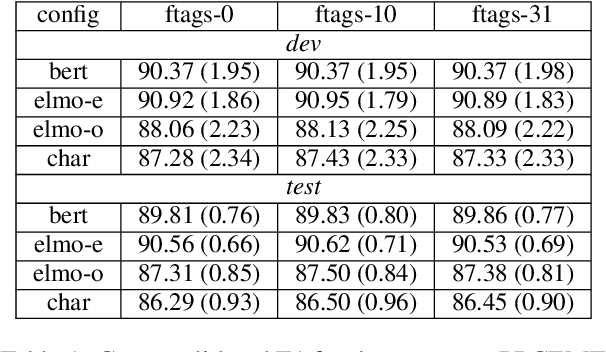
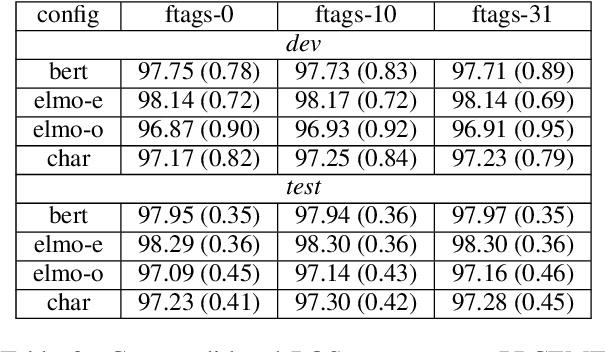
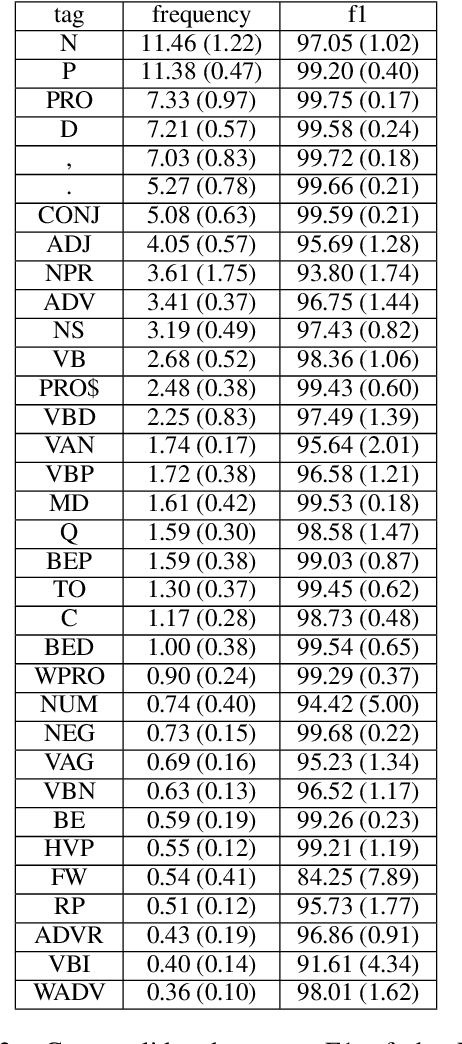
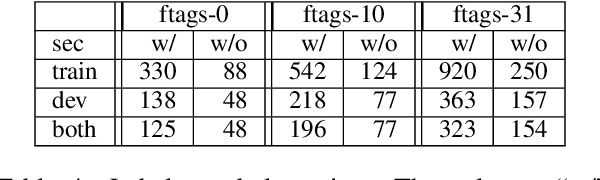
We present the first parsing results on the Penn-Helsinki Parsed Corpus of Early Modern English (PPCEME), a 1.9 million word treebank that is an important resource for research in syntactic change. We describe key features of PPCEME that make it challenging for parsing, including a larger and more varied set of function tags than in the Penn Treebank. We present results for this corpus using a modified version of the Berkeley Neural Parser and the approach to function tag recovery of Gabbard et al (2006). Despite its simplicity, this approach works surprisingly well, suggesting it is possible to recover the original structure with sufficient accuracy to support linguistic applications (e.g., searching for syntactic structures of interest). However, for a subset of function tags (e.g., the tag indicating direct speech), additional work is needed, and we discuss some further limits of this approach. The resulting parser will be used to parse Early English Books Online, a 1.1 billion word corpus whose utility for the study of syntactic change will be greatly increased with the addition of accurate parse trees.
Automatic recognition of suprasegmentals in speech
Aug 04, 2021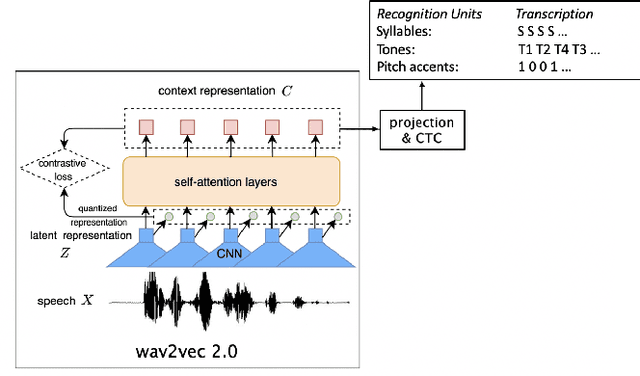
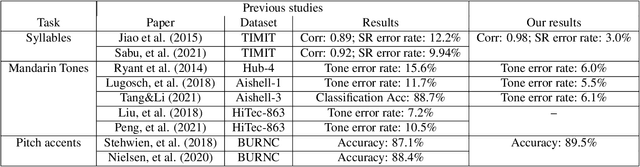
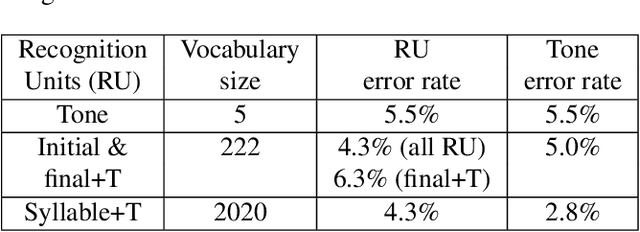
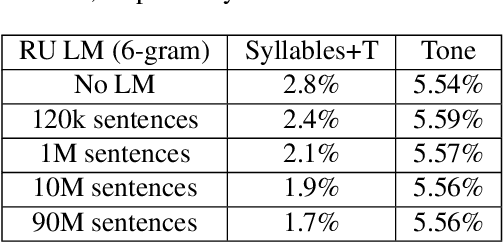
This study reports our efforts to improve automatic recognition of suprasegmentals by fine-tuning wav2vec 2.0 with CTC, a method that has been successful in automatic speech recognition. We demonstrate that the method can improve the state-of-the-art on automatic recognition of syllables, tones, and pitch accents. Utilizing segmental information, by employing tonal finals or tonal syllables as recognition units, can significantly improve Mandarin tone recognition. Language models are helpful when tonal syllables are used as recognition units, but not helpful when tones are recognition units. Finally, Mandarin tone recognition can benefit from English phoneme recognition by combining the two tasks in fine-tuning wav2vec 2.0.
CHiME-6 Challenge:Tackling Multispeaker Speech Recognition for Unsegmented Recordings
May 02, 2020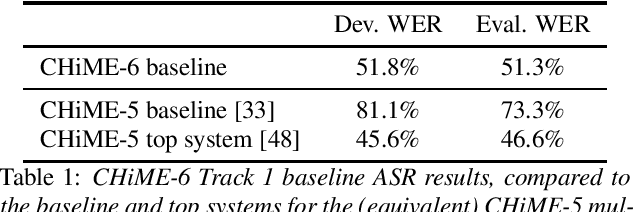

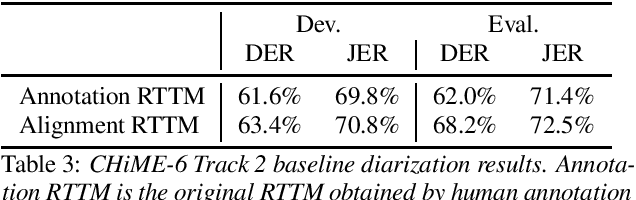

Following the success of the 1st, 2nd, 3rd, 4th and 5th CHiME challenges we organize the 6th CHiME Speech Separation and Recognition Challenge (CHiME-6). The new challenge revisits the previous CHiME-5 challenge and further considers the problem of distant multi-microphone conversational speech diarization and recognition in everyday home environments. Speech material is the same as the previous CHiME-5 recordings except for accurate array synchronization. The material was elicited using a dinner party scenario with efforts taken to capture data that is representative of natural conversational speech. This paper provides a baseline description of the CHiME-6 challenge for both segmented multispeaker speech recognition (Track 1) and unsegmented multispeaker speech recognition (Track 2). Of note, Track 2 is the first challenge activity in the community to tackle an unsegmented multispeaker speech recognition scenario with a complete set of reproducible open source baselines providing speech enhancement, speaker diarization, and speech recognition modules.
Parsing Early Modern English for Linguistic Search
Feb 24, 2020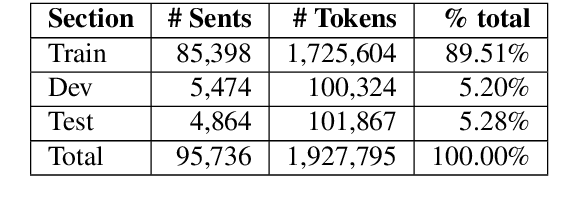

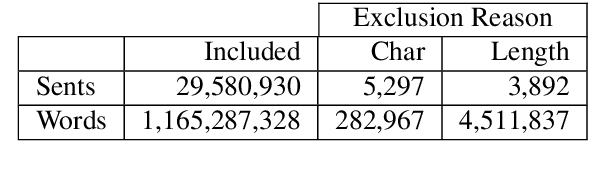
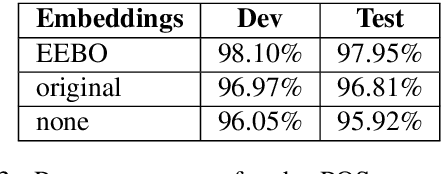
We investigate the question of whether advances in NLP over the last few years make it possible to vastly increase the size of data usable for research in historical syntax. This brings together many of the usual tools in NLP - word embeddings, tagging, and parsing - in the service of linguistic queries over automatically annotated corpora. We train a part-of-speech (POS) tagger and parser on a corpus of historical English, using ELMo embeddings trained over a billion words of similar text. The evaluation is based on the standard metrics, as well as on the accuracy of the query searches using the parsed data.
The Second DIHARD Diarization Challenge: Dataset, task, and baselines
Jun 18, 2019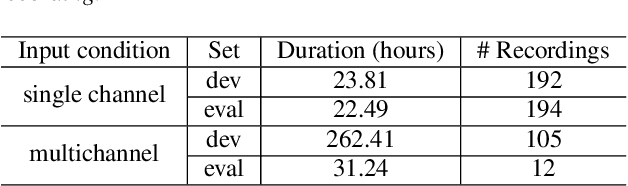
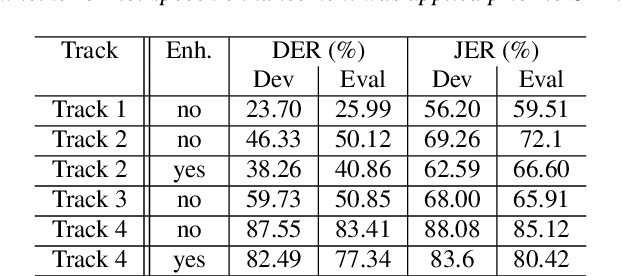
This paper introduces the second DIHARD challenge, the second in a series of speaker diarization challenges intended to improve the robustness of diarization systems to variation in recording equipment, noise conditions, and conversational domain. The challenge comprises four tracks evaluating diarization performance under two input conditions (single channel vs. multi-channel) and two segmentation conditions (diarization from a reference speech segmentation vs. diarization from scratch). In order to prevent participants from overtuning to a particular combination of recording conditions and conversational domain, recordings are drawn from a variety of sources ranging from read audiobooks to meeting speech, to child language acquisition recordings, to dinner parties, to web video. We describe the task and metrics, challenge design, datasets, and baseline systems for speech enhancement, speech activity detection, and diarization.