 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePenn-Helsinki Parsed Corpus of Early Modern English: First Parsing Results and Analysis
Paper and Code
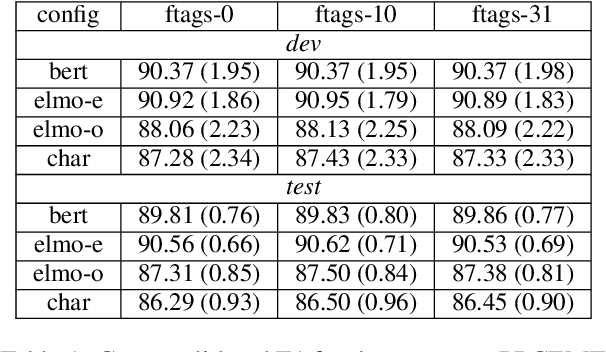
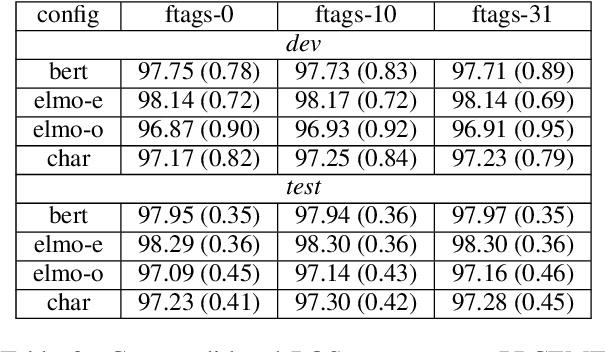
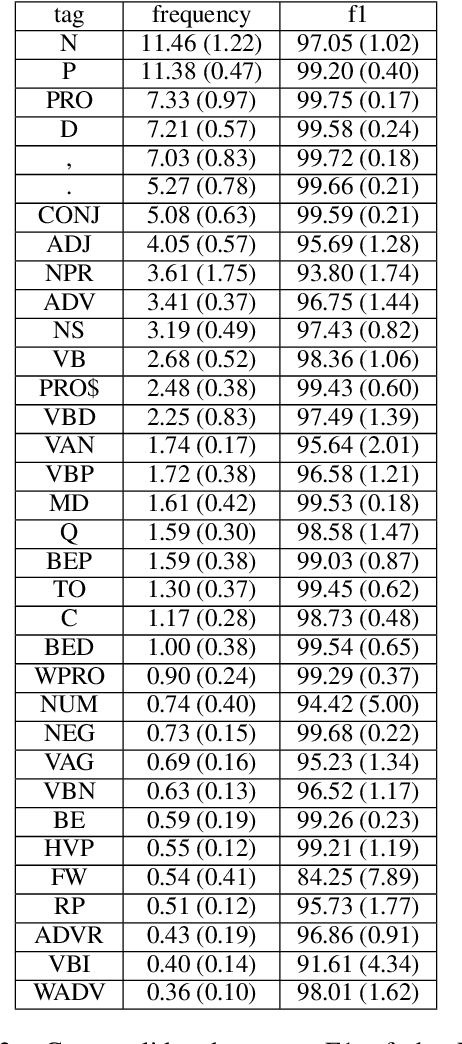
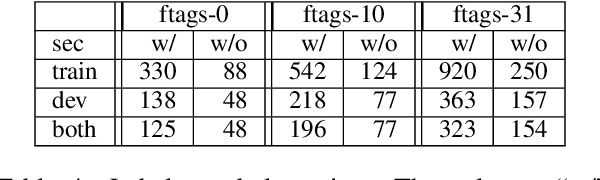
We present the first parsing results on the Penn-Helsinki Parsed Corpus of Early Modern English (PPCEME), a 1.9 million word treebank that is an important resource for research in syntactic change. We describe key features of PPCEME that make it challenging for parsing, including a larger and more varied set of function tags than in the Penn Treebank. We present results for this corpus using a modified version of the Berkeley Neural Parser and the approach to function tag recovery of Gabbard et al (2006). Despite its simplicity, this approach works surprisingly well, suggesting it is possible to recover the original structure with sufficient accuracy to support linguistic applications (e.g., searching for syntactic structures of interest). However, for a subset of function tags (e.g., the tag indicating direct speech), additional work is needed, and we discuss some further limits of this approach. The resulting parser will be used to parse Early English Books Online, a 1.1 billion word corpus whose utility for the study of syntactic change will be greatly increased with the addition of accurate parse trees.