 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved POS tagging for spontaneous, clinical speech using data augmentation
Jul 11, 2023



This paper addresses the problem of improving POS tagging of transcripts of speech from clinical populations. In contrast to prior work on parsing and POS tagging of transcribed speech, we do not make use of an in domain treebank for training. Instead, we train on an out of domain treebank of newswire using data augmentation techniques to make these structures resemble natural, spontaneous speech. We trained a parser with and without the augmented data and tested its performance using manually validated POS tags in clinical speech produced by patients with various types of neurodegenerative conditions.
A Part-of-Speech Tagger for Yiddish: First Steps in Tagging the Yiddish Book Center Corpus
Apr 03, 2022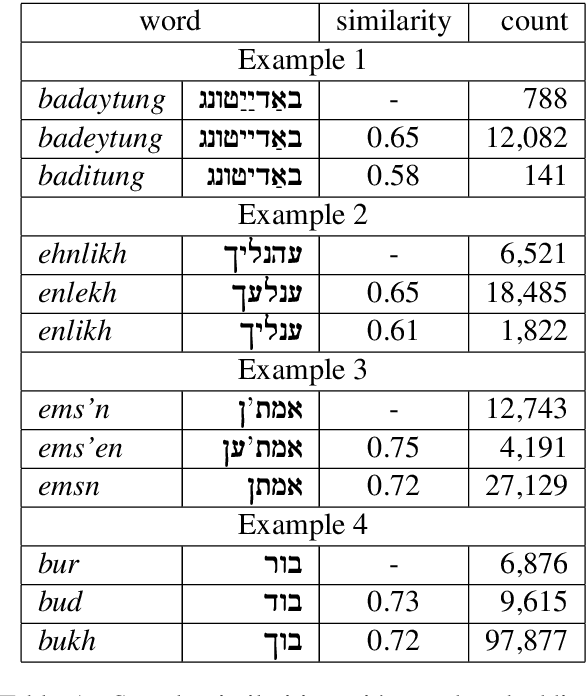
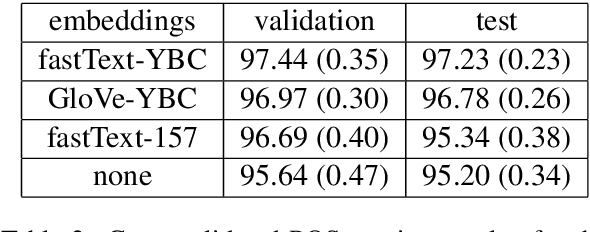
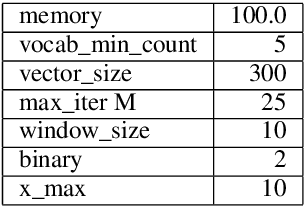
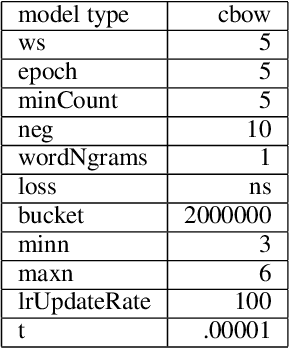
We describe the construction and evaluation of a part-of-speech tagger for Yiddish (the first one, to the best of our knowledge). This is the first step in a larger project of automatically assigning part-of-speech tags and syntactic structure to Yiddish text for purposes of linguistic research. We combine two resources for the current work - an 80K word subset of the Penn Parsed Corpus of Historical Yiddish (PPCHY) (Santorini, 2021) and 650 million words of OCR'd Yiddish text from the Yiddish Book Center (YBC). We compute word embeddings on the YBC corpus, and these embeddings are used with a tagger model trained and evaluated on the PPCHY. Yiddish orthography in the YBC corpus has many spelling inconsistencies, and we present some evidence that even simple non-contextualized embeddings are able to capture the relationships among spelling variants without the need to first "standardize" the corpus. We evaluate the tagger performance on a 10-fold cross-validation split, with and without the embeddings, showing that the embeddings improve tagger performance. However, a great deal of work remains to be done, and we conclude by discussing some next steps, including the need for additional annotated training and test data.
Penn-Helsinki Parsed Corpus of Early Modern English: First Parsing Results and Analysis
Dec 15, 2021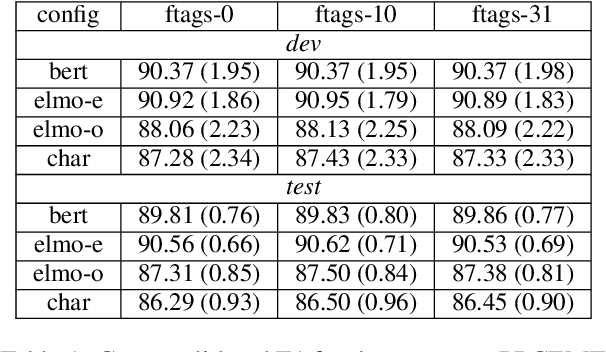
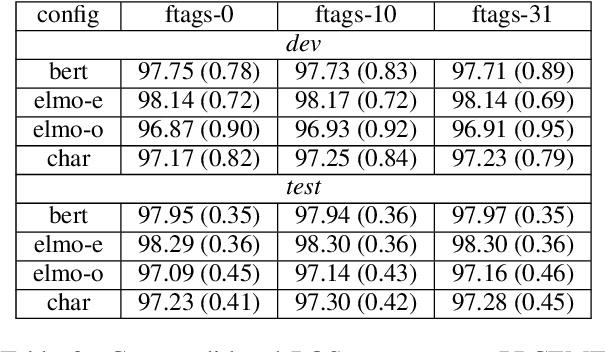
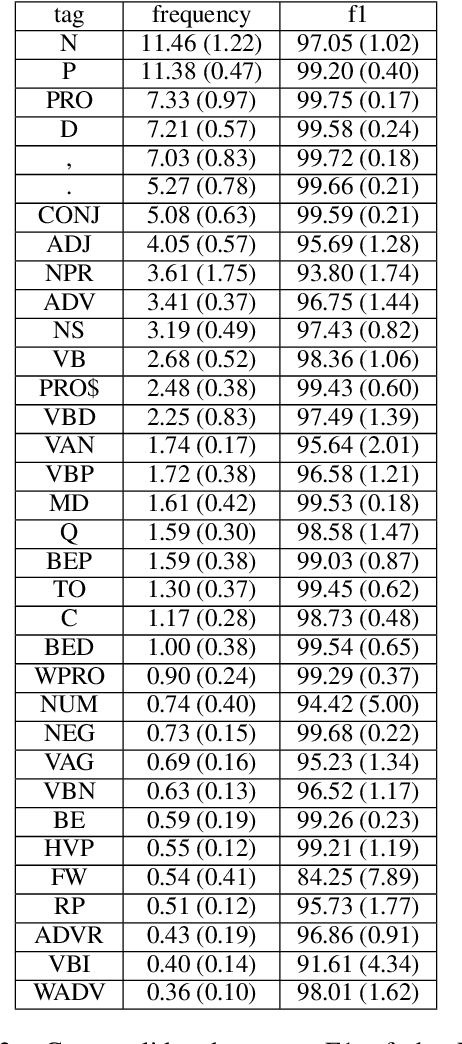
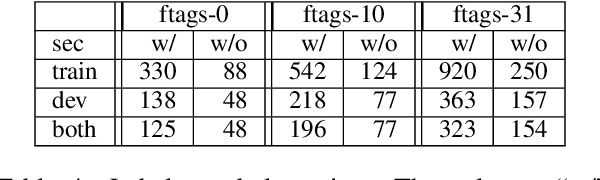
We present the first parsing results on the Penn-Helsinki Parsed Corpus of Early Modern English (PPCEME), a 1.9 million word treebank that is an important resource for research in syntactic change. We describe key features of PPCEME that make it challenging for parsing, including a larger and more varied set of function tags than in the Penn Treebank. We present results for this corpus using a modified version of the Berkeley Neural Parser and the approach to function tag recovery of Gabbard et al (2006). Despite its simplicity, this approach works surprisingly well, suggesting it is possible to recover the original structure with sufficient accuracy to support linguistic applications (e.g., searching for syntactic structures of interest). However, for a subset of function tags (e.g., the tag indicating direct speech), additional work is needed, and we discuss some further limits of this approach. The resulting parser will be used to parse Early English Books Online, a 1.1 billion word corpus whose utility for the study of syntactic change will be greatly increased with the addition of accurate parse trees.
Parsing Early Modern English for Linguistic Search
Feb 24, 2020

We investigate the question of whether advances in NLP over the last few years make it possible to vastly increase the size of data usable for research in historical syntax. This brings together many of the usual tools in NLP - word embeddings, tagging, and parsing - in the service of linguistic queries over automatically annotated corpora. We train a part-of-speech (POS) tagger and parser on a corpus of historical English, using ELMo embeddings trained over a billion words of similar text. The evaluation is based on the standard metrics, as well as on the accuracy of the query searches using the parsed data.
Heuristics and Parse Ranking
Aug 28, 1995
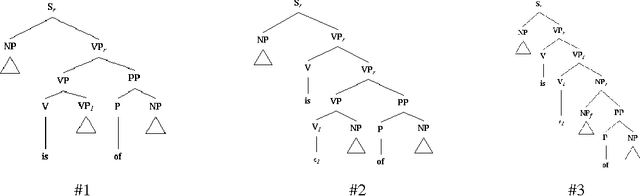
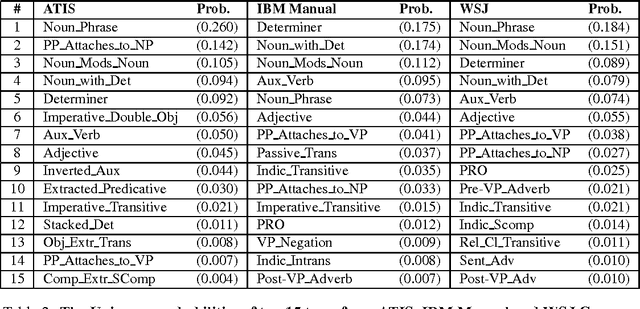
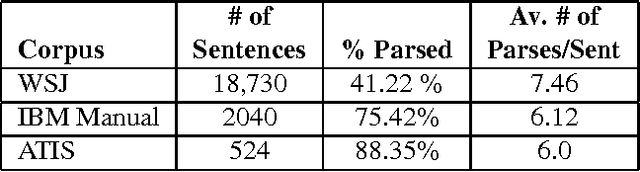
There are currently two philosophies for building grammars and parsers -- Statistically induced grammars and Wide-coverage grammars. One way to combine the strengths of both approaches is to have a wide-coverage grammar with a heuristic component which is domain independent but whose contribution is tuned to particular domains. In this paper, we discuss a three-stage approach to disambiguation in the context of a lexicalized grammar, using a variety of domain independent heuristic techniques. We present a training algorithm which uses hand-bracketed treebank parses to set the weights of these heuristics. We compare the performance of our grammar against the performance of the IBM statistical grammar, using both untrained and trained weights for the heuristics.
* uuencoded compressed ps file. A4 format. 10 pages
Using Higher-Order Logic Programming for Semantic Interpretation of Coordinate Constructs
Jun 06, 1995


Many theories of semantic interpretation use lambda-term manipulation to compositionally compute the meaning of a sentence. These theories are usually implemented in a language such as Prolog that can simulate lambda-term operations with first-order unification. However, for some interesting cases, such as a Combinatory Categorial Grammar account of coordination constructs, this can only be done by obscuring the underlying linguistic theory with the ``tricks'' needed for implementation. This paper shows how the use of abstract syntax permitted by higher-order logic programming allows an elegant implementation of the semantics of Combinatory Categorial Grammar, including its handling of coordination constructs.