 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeuristics and Parse Ranking
Aug 28, 1995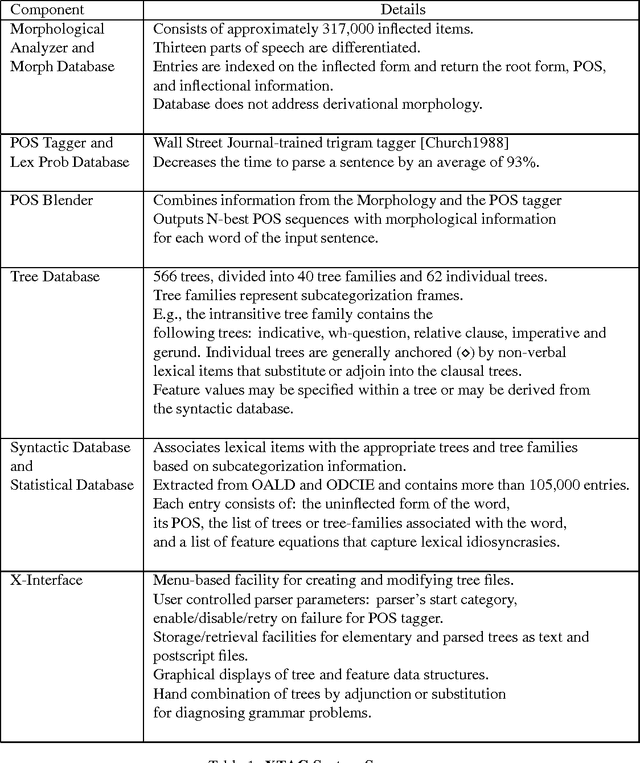
There are currently two philosophies for building grammars and parsers -- Statistically induced grammars and Wide-coverage grammars. One way to combine the strengths of both approaches is to have a wide-coverage grammar with a heuristic component which is domain independent but whose contribution is tuned to particular domains. In this paper, we discuss a three-stage approach to disambiguation in the context of a lexicalized grammar, using a variety of domain independent heuristic techniques. We present a training algorithm which uses hand-bracketed treebank parses to set the weights of these heuristics. We compare the performance of our grammar against the performance of the IBM statistical grammar, using both untrained and trained weights for the heuristics.
* uuencoded compressed ps file. A4 format. 10 pages
Some Novel Applications of Explanation-Based Learning to Parsing Lexicalized Tree-Adjoining Grammars
May 10, 1995



In this paper we present some novel applications of Explanation-Based Learning (EBL) technique to parsing Lexicalized Tree-Adjoining grammars. The novel aspects are (a) immediate generalization of parses in the training set, (b) generalization over recursive structures and (c) representation of generalized parses as Finite State Transducers. A highly impoverished parser called a ``stapler'' has also been introduced. We present experimental results using EBL for different corpora and architectures to show the effectiveness of our approach.
* uuencoded postscript file
Bootstrapping A Wide-Coverage CCG from FB-LTAG
Nov 03, 1994A number of researchers have noted the similarities between LTAGs and CCGs. Observing this resemblance, we felt that we could make use of the wide-coverage grammar developed in the XTAG project to build a wide-coverage CCG. To our knowledge there have been no attempts to construct a large-scale CCG parser with the lexicon to support it. In this paper, we describe such a system, built by adapting various XTAG components to CCG. We find that, despite the similarities between the formalisms, certain parts of the grammatical workload are distributed differently. In addition, the flexibility of CCG derivations allows the translated grammar to handle a number of ``non-constituent'' constructions which the XTAG grammar cannot.
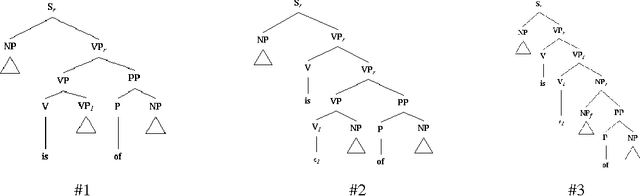
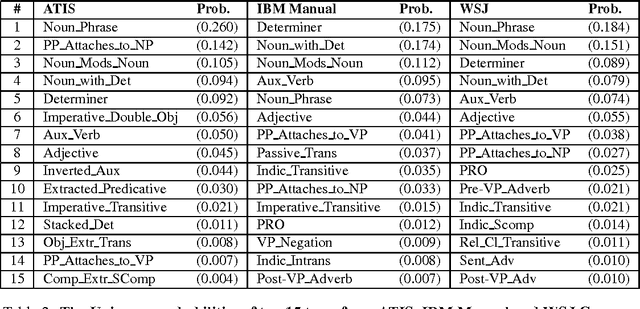
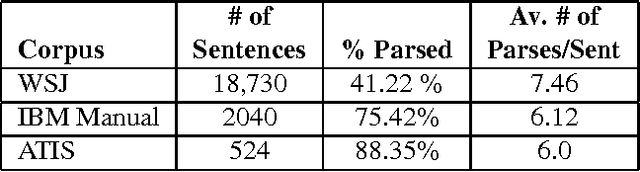
Status of the XTAG System
Nov 03, 1994XTAG is an ongoing project to develop a wide-coverage grammar for English, based on the Feature-based Lexicalized Tree Adjoining Grammar (FB-LTAG) formalism. The XTAG system integrates a morphological analyzer, an N-best part-of-speech tagger, an Early-style parser and an X-window interface, along with a wide-coverage grammar for English developed using the system. This system serves as a linguist's workbench for developing FB-LTAG specifications. This paper presents a description of and recent improvements to the various components of the XTAG system. It also presents the recent performance of the wide-coverage grammar on various corpora and compares it against the performance of other wide-coverage and domain-specific grammars.
* uuencoded compressed ps file. 4 pages
Feature-Based TAG in place of multi-component adjunction: Computational Implications
Oct 26, 1994Using feature-based Tree Adjoining Grammar (TAG), this paper presents linguistically motivated analyses of constructions claimed to require multi-component adjunction. These feature-based TAG analyses permit parsing of these constructions using an existing unification-based Earley-style TAG parser, thus obviating the need for a multi-component TAG parser without sacrificing linguistic coverage for English.
* ps file. 9 pages
Disambiguation of Super Parts of Speech (or Supertags): Almost Parsing
Oct 26, 1994
In a lexicalized grammar formalism such as Lexicalized Tree-Adjoining Grammar (LTAG), each lexical item is associated with at least one elementary structure (supertag) that localizes syntactic and semantic dependencies. Thus a parser for a lexicalized grammar must search a large set of supertags to choose the right ones to combine for the parse of the sentence. We present techniques for disambiguating supertags using local information such as lexical preference and local lexical dependencies. The similarity between LTAG and Dependency grammars is exploited in the dependency model of supertag disambiguation. The performance results for various models of supertag disambiguation such as unigram, trigram and dependency-based models are presented.
* ps file. 8 pages
Lexicalization and Grammar Development
Oct 21, 1994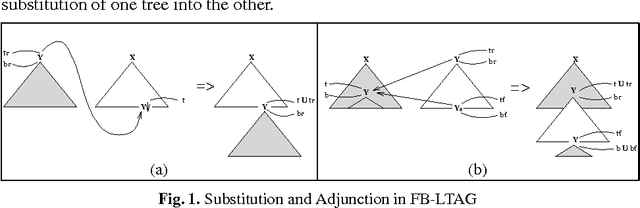

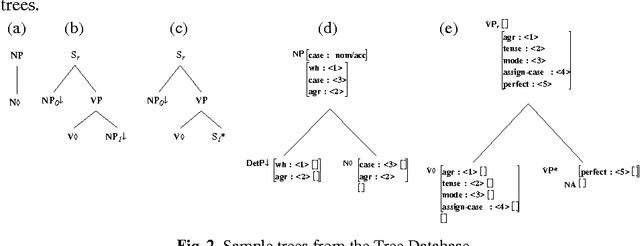
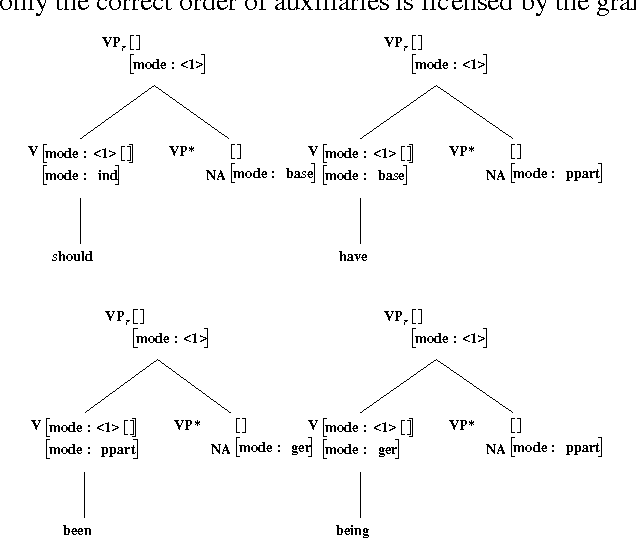
In this paper we present a fully lexicalized grammar formalism as a particularly attractive framework for the specification of natural language grammars. We discuss in detail Feature-based, Lexicalized Tree Adjoining Grammars (FB-LTAGs), a representative of the class of lexicalized grammars. We illustrate the advantages of lexicalized grammars in various contexts of natural language processing, ranging from wide-coverage grammar development to parsing and machine translation. We also present a method for compact and efficient representation of lexicalized trees.
* ps file. English w/ German abstract. 10 pages
XTAG system - A Wide Coverage Grammar for English
Oct 20, 1994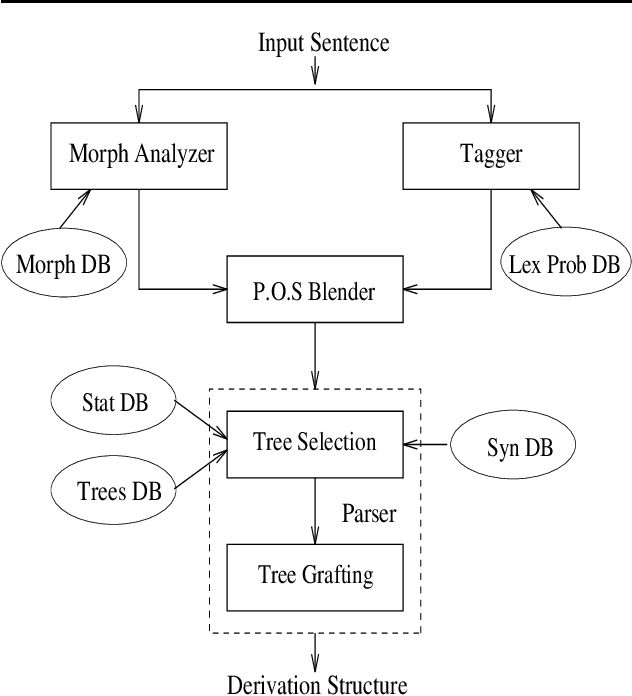

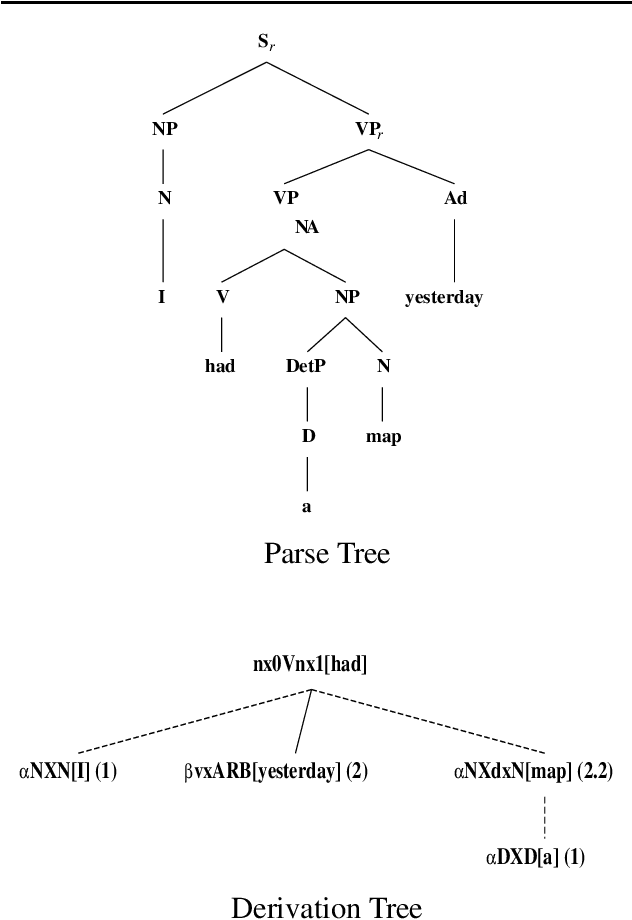
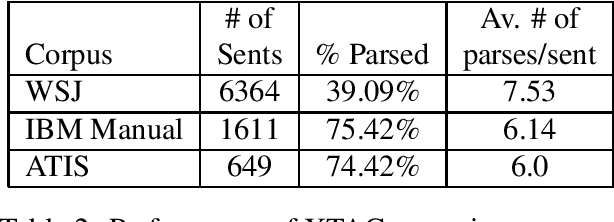
This paper presents the XTAG system, a grammar development tool based on the Tree Adjoining Grammar (TAG) formalism that includes a wide-coverage syntactic grammar for English. The various components of the system are discussed and preliminary evaluation results from the parsing of various corpora are given. Results from the comparison of XTAG against the IBM statistical parser and the Alvey Natural Language Tool parser are also given.
* ps file. 7 pages