 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMicroplanning with Communicative Intentions: The SPUD System
Apr 30, 2001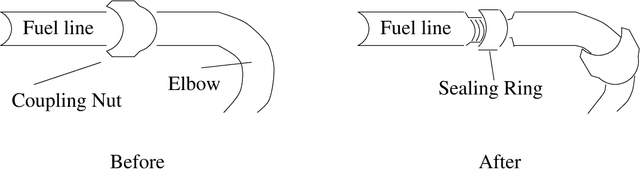

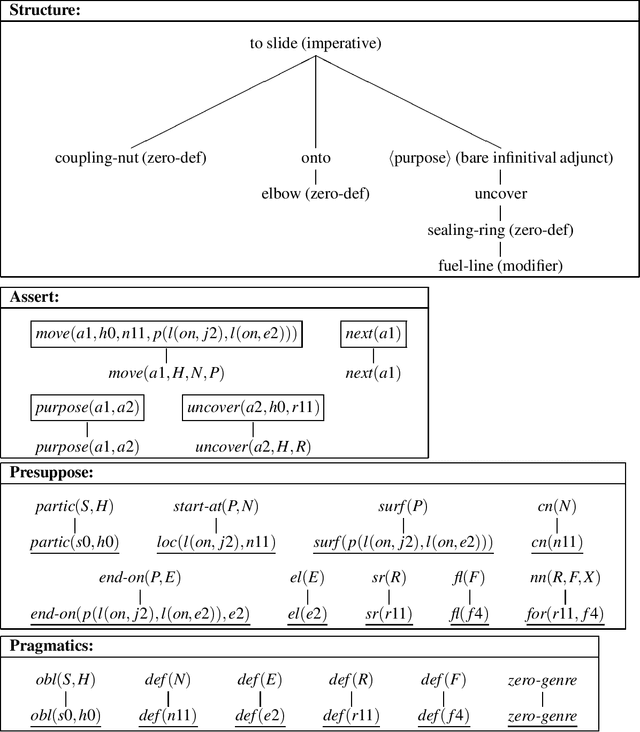
The process of microplanning encompasses a range of problems in Natural Language Generation (NLG), such as referring expression generation, lexical choice, and aggregation, problems in which a generator must bridge underlying domain-specific representations and general linguistic representations. In this paper, we describe a uniform approach to microplanning based on declarative representations of a generator's communicative intent. These representations describe the results of NLG: communicative intent associates the concrete linguistic structure planned by the generator with inferences that show how the meaning of that structure communicates needed information about some application domain in the current discourse context. Our approach, implemented in the SPUD (sentence planning using description) microplanner, uses the lexicalized tree-adjoining grammar formalism (LTAG) to connect structure to meaning and uses modal logic programming to connect meaning to context. At the same time, communicative intent representations provide a resource for the process of NLG. Using representations of communicative intent, a generator can augment the syntax, semantics and pragmatics of an incomplete sentence simultaneously, and can assess its progress on the various problems of microplanning incrementally. The declarative formulation of communicative intent translates into a well-defined methodology for designing grammatical and conceptual resources which the generator can use to achieve desired microplanning behavior in a specified domain.
Punctuation in Quoted Speech
Aug 16, 1996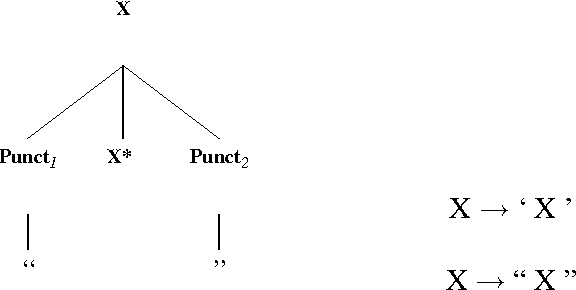
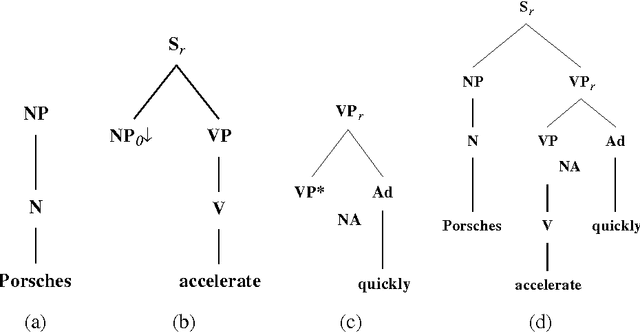
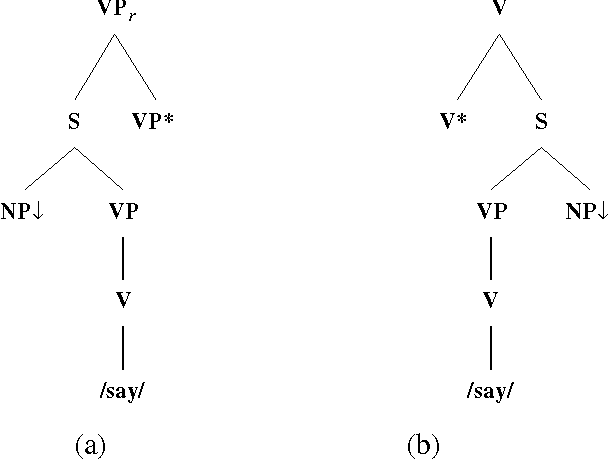
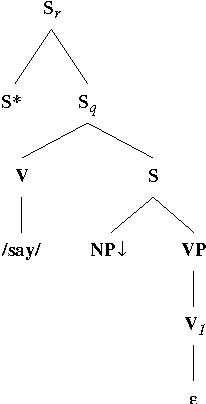
Quoted speech is often set off by punctuation marks, in particular quotation marks. Thus, it might seem that the quotation marks would be extremely useful in identifying these structures in texts. Unfortunately, the situation is not quite so clear. In this work, I will argue that quotation marks are not adequate for either identifying or constraining the syntax of quoted speech. More useful information comes from the presence of a quoting verb, which is either a verb of saying or a punctual verb, and the presence of other punctuation marks, usually commas. Using a lexicalized grammar, we can license most quoting clauses as text adjuncts. A distinction will be made not between direct and indirect quoted speech, but rather between adjunct and non-adjunct quoting clauses.
Heuristics and Parse Ranking
Aug 28, 1995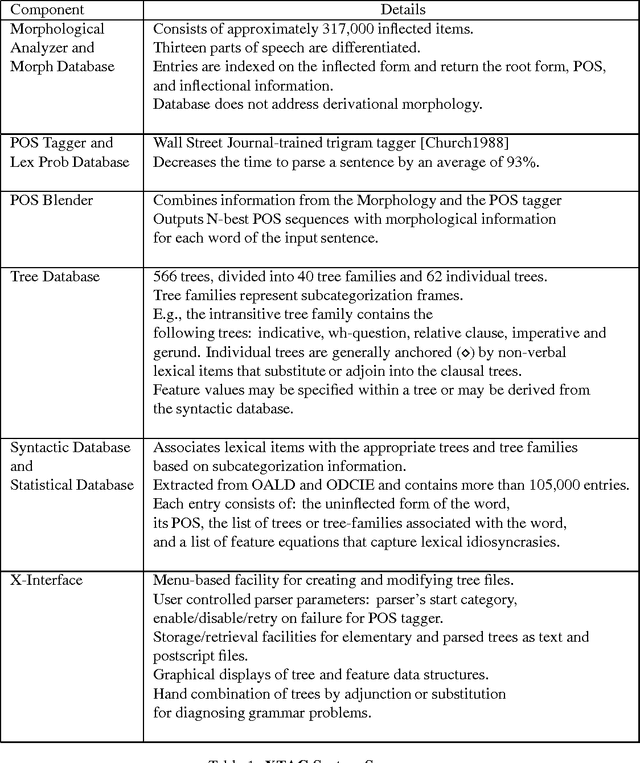
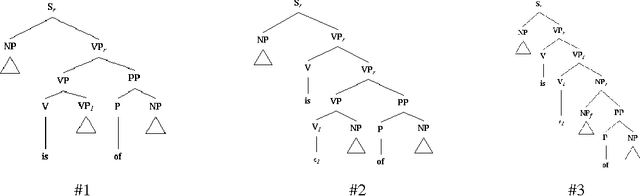
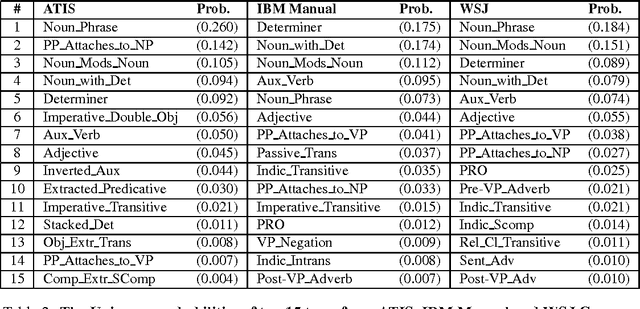
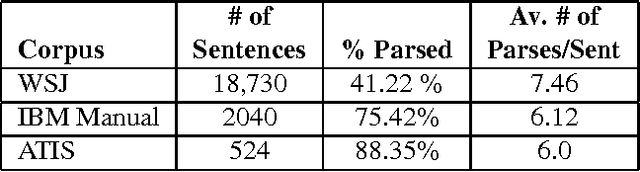
There are currently two philosophies for building grammars and parsers -- Statistically induced grammars and Wide-coverage grammars. One way to combine the strengths of both approaches is to have a wide-coverage grammar with a heuristic component which is domain independent but whose contribution is tuned to particular domains. In this paper, we discuss a three-stage approach to disambiguation in the context of a lexicalized grammar, using a variety of domain independent heuristic techniques. We present a training algorithm which uses hand-bracketed treebank parses to set the weights of these heuristics. We compare the performance of our grammar against the performance of the IBM statistical grammar, using both untrained and trained weights for the heuristics.
* uuencoded compressed ps file. A4 format. 10 pages
Bootstrapping A Wide-Coverage CCG from FB-LTAG
Nov 03, 1994A number of researchers have noted the similarities between LTAGs and CCGs. Observing this resemblance, we felt that we could make use of the wide-coverage grammar developed in the XTAG project to build a wide-coverage CCG. To our knowledge there have been no attempts to construct a large-scale CCG parser with the lexicon to support it. In this paper, we describe such a system, built by adapting various XTAG components to CCG. We find that, despite the similarities between the formalisms, certain parts of the grammatical workload are distributed differently. In addition, the flexibility of CCG derivations allows the translated grammar to handle a number of ``non-constituent'' constructions which the XTAG grammar cannot.