 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeuristics and Parse Ranking
Paper and Code
Aug 28, 1995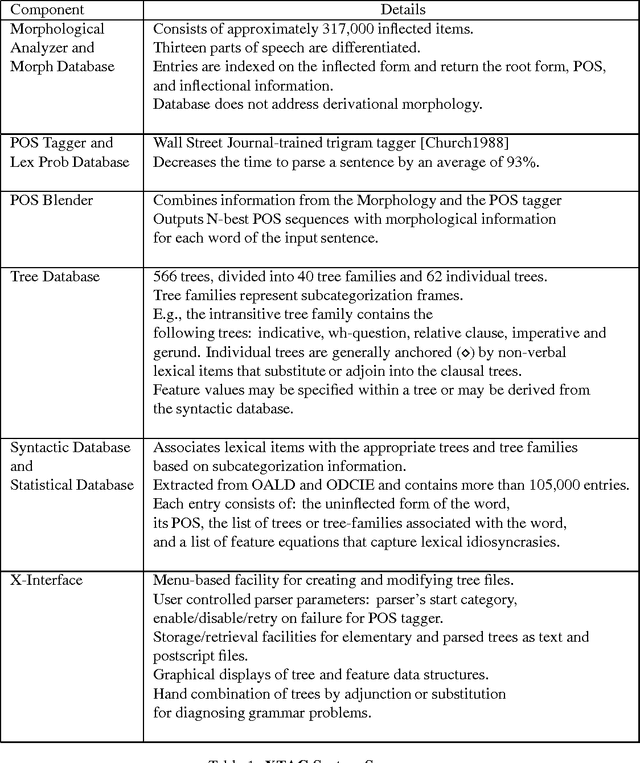
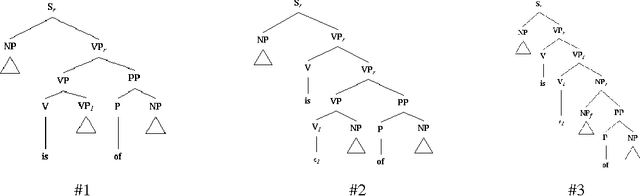
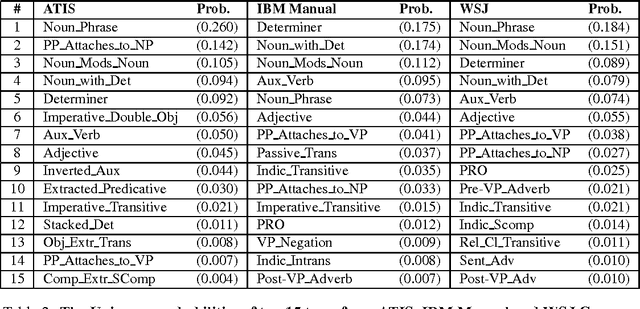
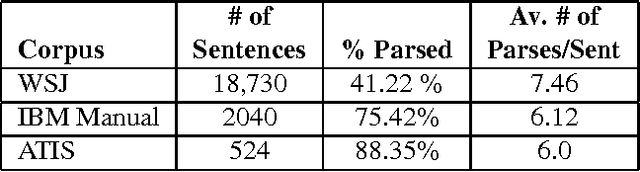
There are currently two philosophies for building grammars and parsers -- Statistically induced grammars and Wide-coverage grammars. One way to combine the strengths of both approaches is to have a wide-coverage grammar with a heuristic component which is domain independent but whose contribution is tuned to particular domains. In this paper, we discuss a three-stage approach to disambiguation in the context of a lexicalized grammar, using a variety of domain independent heuristic techniques. We present a training algorithm which uses hand-bracketed treebank parses to set the weights of these heuristics. We compare the performance of our grammar against the performance of the IBM statistical grammar, using both untrained and trained weights for the heuristics.