 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatus of the XTAG System
Nov 03, 1994XTAG is an ongoing project to develop a wide-coverage grammar for English, based on the Feature-based Lexicalized Tree Adjoining Grammar (FB-LTAG) formalism. The XTAG system integrates a morphological analyzer, an N-best part-of-speech tagger, an Early-style parser and an X-window interface, along with a wide-coverage grammar for English developed using the system. This system serves as a linguist's workbench for developing FB-LTAG specifications. This paper presents a description of and recent improvements to the various components of the XTAG system. It also presents the recent performance of the wide-coverage grammar on various corpora and compares it against the performance of other wide-coverage and domain-specific grammars.
* uuencoded compressed ps file. 4 pages
Constraining Lexical Selection Across Languages Using TAGs
Nov 03, 1994Lexical selection in Machine Translation consists of several related components. Two that have received a lot of attention are lexical mapping from an underlying concept or lexical item, and choosing the correct subcategorization frame based on argument structure. Because most MT applications are small or relatively domain specific, a third component of lexical selection is generally overlooked - distinguishing between lexical items that are closely related conceptually. While some MT systems have proposed using a 'world knowledge' module to decide which word is more appropriate based on various pragmatic or stylistic constraints, we are interested in seeing how much we can accomplish using a combination of syntax and lexical semantics. By using separate ontologies for each language implemented in FB-LTAGs, we are able to elegantly model the more specific and language dependent syntactic and semantic distinctions necessary to further filter the choice of the lexical item.
Determining Determiner Sequencing: A Syntactic Analysis for English
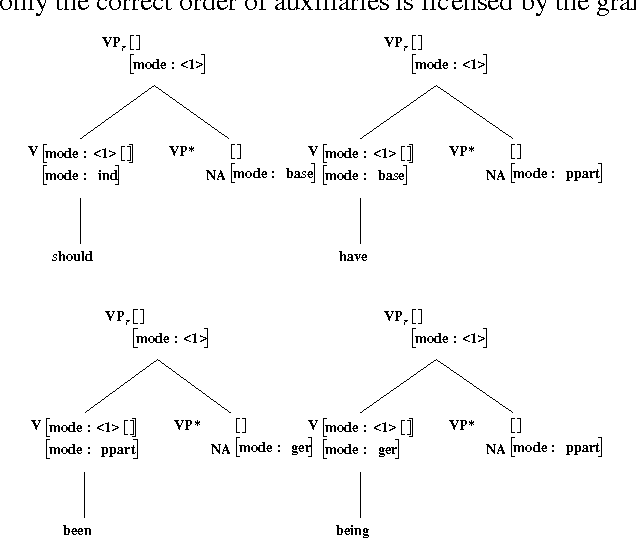
Nov 03, 1994Previous work on English determiners has primarily concentrated on their semantics or scoping properties rather than their complex ordering behavior. The little work that has been done on determiner ordering generally splits determiners into three subcategories. However, this small number of categories does not capture the finer distinctions necessary to correctly order determiners. This paper presents a syntactic account of determiner sequencing based on eight independently identified semantic features. Complex determiners, such as genitives, partitives, and determiner modifying adverbials, are also presented. This work has been implemented as part of XTAG, a wide-coverage grammar for English based in the Feature-Based, Lexicalized Tree Adjoining Grammar (FB-LTAG) formalism.
A Freely Available Wide Coverage Morphological Analyzer for English
Oct 24, 1994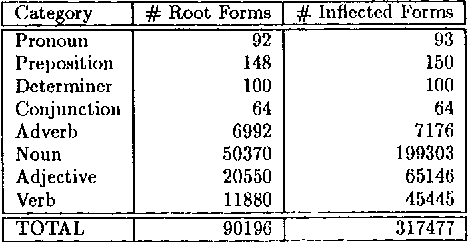


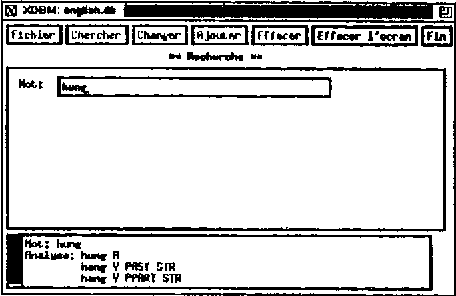
This paper presents a morphological lexicon for English that handles more than 317000 inflected forms derived from over 90000 stems. The lexicon is available in two formats. The first can be used by an implementation of a two-level processor for morphological analysis. The second, derived from the first one for efficiency reasons, consists of a disk-based database using a UNIX hash table facility. We also built an X Window tool to facilitate the maintenance and browsing of the lexicon. The package is ready to be integrated into an natural language application such as a parser through hooks written in Lisp and C.
* uuencoded compressed ps file. 5 pages. Contact info has been upated from Coling '92 version
Korean to English Translation Using Synchronous TAGs
Oct 24, 1994
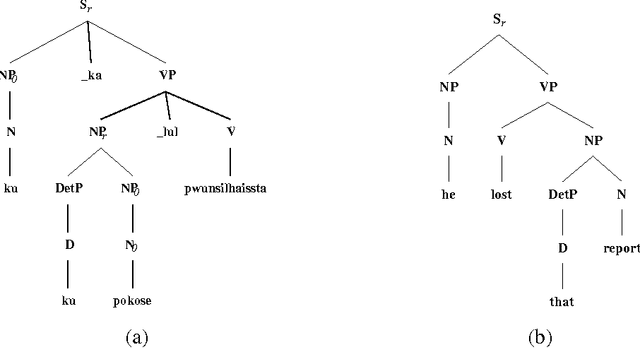
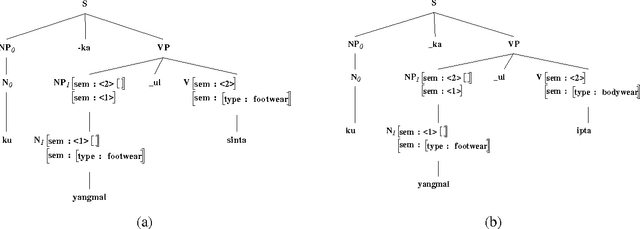
It is often argued that accurate machine translation requires reference to contextual knowledge for the correct treatment of linguistic phenomena such as dropped arguments and accurate lexical selection. One of the historical arguments in favor of the interlingua approach has been that, since it revolves around a deep semantic representation, it is better able to handle the types of linguistic phenomena that are seen as requiring a knowledge-based approach. In this paper we present an alternative approach, exemplified by a prototype system for machine translation of English and Korean which is implemented in Synchronous TAGs. This approach is essentially transfer based, and uses semantic feature unification for accurate lexical selection of polysemous verbs. The same semantic features, when combined with a discourse model which stores previously mentioned entities, can also be used for the recovery of topicalized arguments. In this paper we concentrate on the translation of Korean to English.
* ps file. 8 pages
Lexicalization and Grammar Development
Oct 21, 1994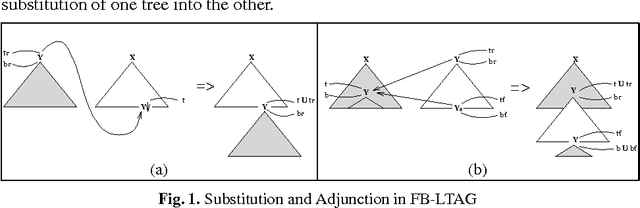

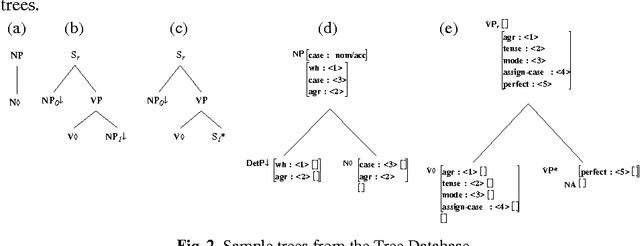
In this paper we present a fully lexicalized grammar formalism as a particularly attractive framework for the specification of natural language grammars. We discuss in detail Feature-based, Lexicalized Tree Adjoining Grammars (FB-LTAGs), a representative of the class of lexicalized grammars. We illustrate the advantages of lexicalized grammars in various contexts of natural language processing, ranging from wide-coverage grammar development to parsing and machine translation. We also present a method for compact and efficient representation of lexicalized trees.
* ps file. English w/ German abstract. 10 pages
A Freely Available Syntactic Lexicon for English
Oct 21, 1994


This paper presents a syntactic lexicon for English that was originally derived from the Oxford Advanced Learner's Dictionary and the Oxford Dictionary of Current Idiomatic English, and then modified and augmented by hand. There are more than 37,000 syntactic entries from all 8 parts of speech. An X-windows based tool is available for maintaining the lexicon and performing searches. C and Lisp hooks are also available so that the lexicon can be easily utilized by parsers and other programs.
* Latex file with .eps figure. 8 pages
XTAG system - A Wide Coverage Grammar for English
Oct 20, 1994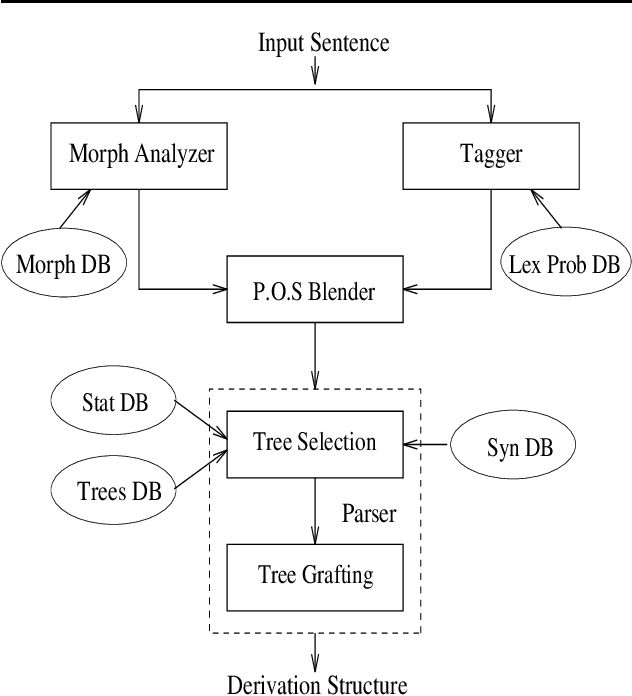

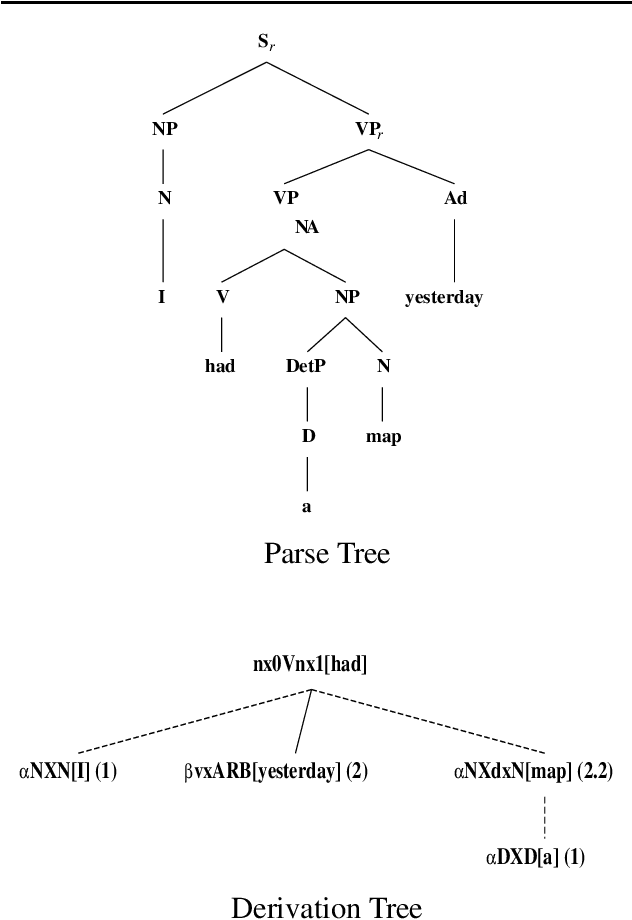
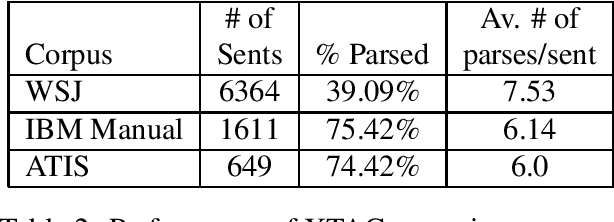
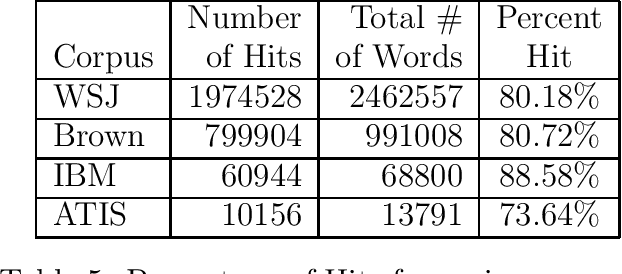
This paper presents the XTAG system, a grammar development tool based on the Tree Adjoining Grammar (TAG) formalism that includes a wide-coverage syntactic grammar for English. The various components of the system are discussed and preliminary evaluation results from the parsing of various corpora are given. Results from the comparison of XTAG against the IBM statistical parser and the Alvey Natural Language Tool parser are also given.
* ps file. 7 pages