 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Trigram-based and Feature-based Methods for Context-Sensitive Spelling Correction
Jun 03, 1996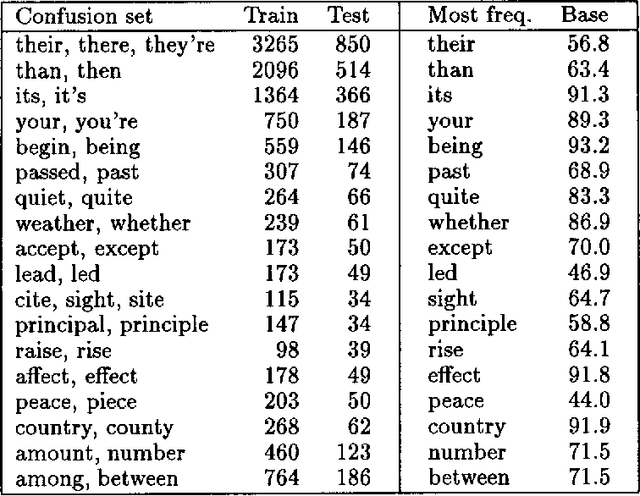
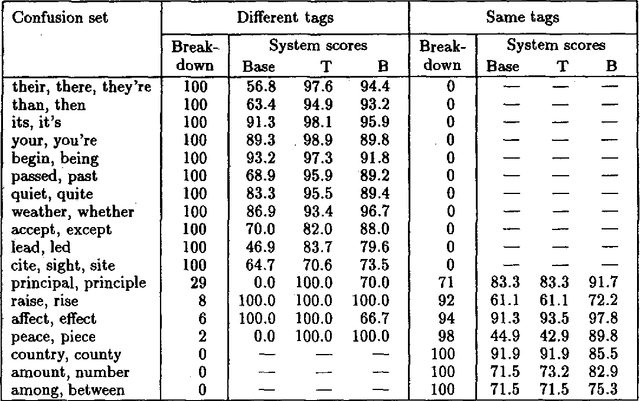
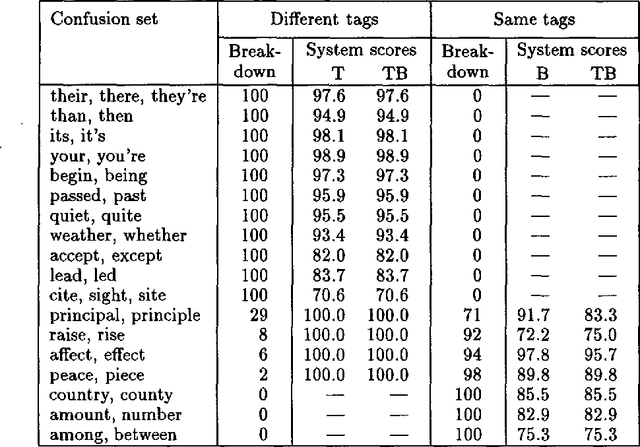
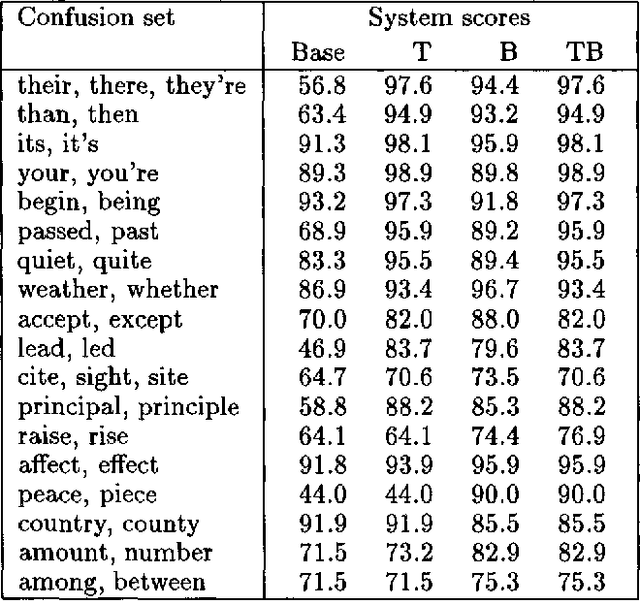
This paper addresses the problem of correcting spelling errors that result in valid, though unintended words (such as ``peace'' and ``piece'', or ``quiet'' and ``quite'') and also the problem of correcting particular word usage errors (such as ``amount'' and ``number'', or ``among'' and ``between''). Such corrections require contextual information and are not handled by conventional spelling programs such as Unix `spell'. First, we introduce a method called Trigrams that uses part-of-speech trigrams to encode the context. This method uses a small number of parameters compared to previous methods based on word trigrams. However, it is effectively unable to distinguish among words that have the same part of speech. For this case, an alternative feature-based method called Bayes performs better; but Bayes is less effective than Trigrams when the distinction among words depends on syntactic constraints. A hybrid method called Tribayes is then introduced that combines the best of the previous two methods. The improvement in performance of Tribayes over its components is verified experimentally. Tribayes is also compared with the grammar checker in Microsoft Word, and is found to have substantially higher performance.
A Freely Available Wide Coverage Morphological Analyzer for English
Oct 24, 1994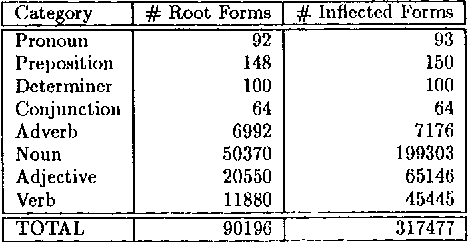


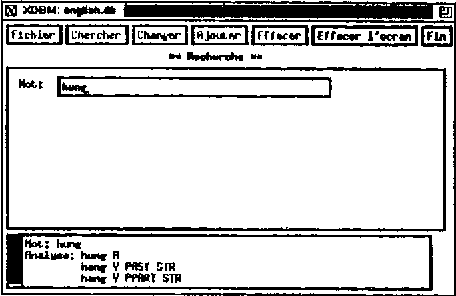
This paper presents a morphological lexicon for English that handles more than 317000 inflected forms derived from over 90000 stems. The lexicon is available in two formats. The first can be used by an implementation of a two-level processor for morphological analysis. The second, derived from the first one for efficiency reasons, consists of a disk-based database using a UNIX hash table facility. We also built an X Window tool to facilitate the maintenance and browsing of the lexicon. The package is ready to be integrated into an natural language application such as a parser through hooks written in Lisp and C.
* uuencoded compressed ps file. 5 pages. Contact info has been upated from Coling '92 version
Principles and Implementation of Deductive Parsing
Apr 26, 1994



We present a system for generating parsers based directly on the metaphor of parsing as deduction. Parsing algorithms can be represented directly as deduction systems, and a single deduction engine can interpret such deduction systems so as to implement the corresponding parser. The method generalizes easily to parsers for augmented phrase structure formalisms, such as definite-clause grammars and other logic grammar formalisms, and has been used for rapid prototyping of parsing algorithms for a variety of formalisms including variants of tree-adjoining grammars, categorial grammars, and lexicalized context-free grammars.
An Alternative Conception of Tree-Adjoining Derivation
Apr 04, 1994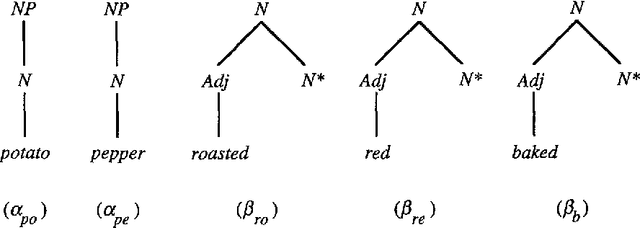
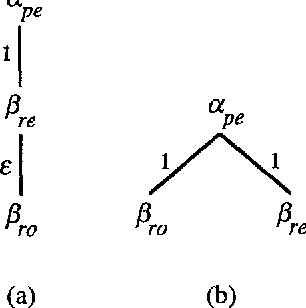
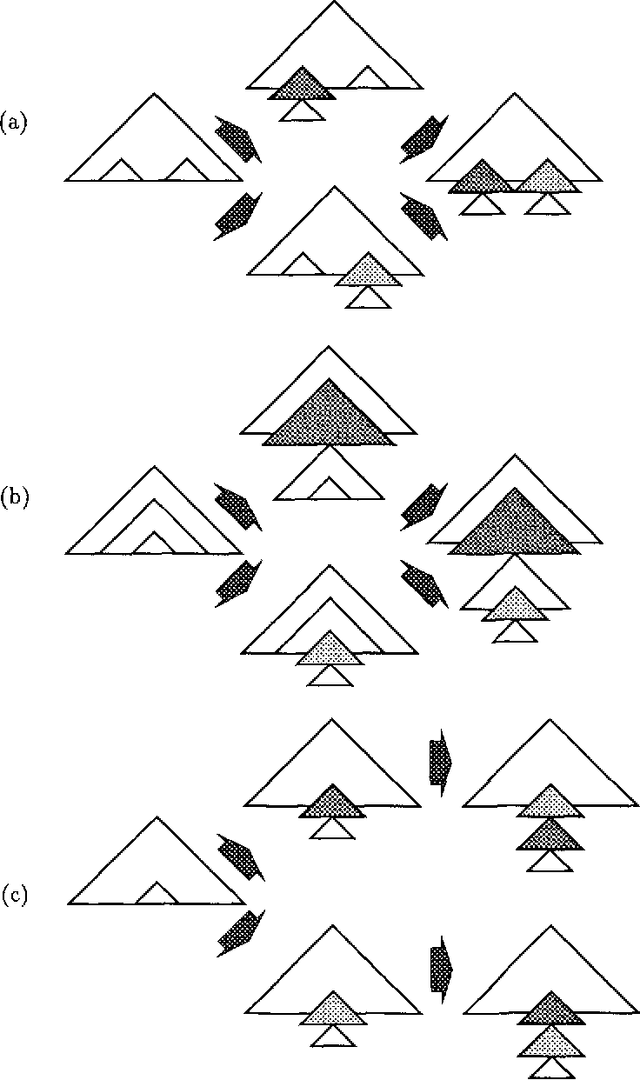
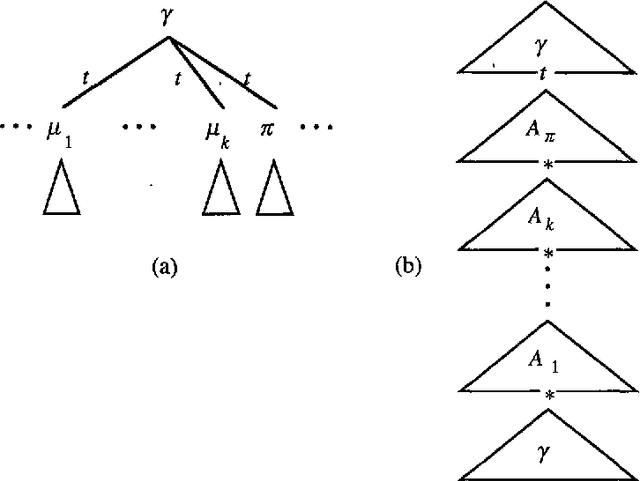
The precise formulation of derivation for tree-adjoining grammars has important ramifications for a wide variety of uses of the formalism, from syntactic analysis to semantic interpretation and statistical language modeling. We argue that the definition of tree-adjoining derivation must be reformulated in order to manifest the proper linguistic dependencies in derivations. The particular proposal is both precisely characterizable through a definition of TAG derivations as equivalence classes of ordered derivation trees, and computationally operational, by virtue of a compilation to linear indexed grammars together with an efficient algorithm for recognition and parsing according to the compiled grammar.
* 33 pages