 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLING: A framework for frame semantic parsing
Oct 19, 2017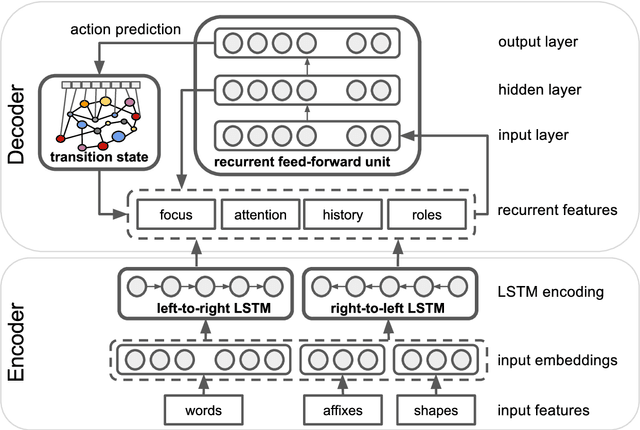


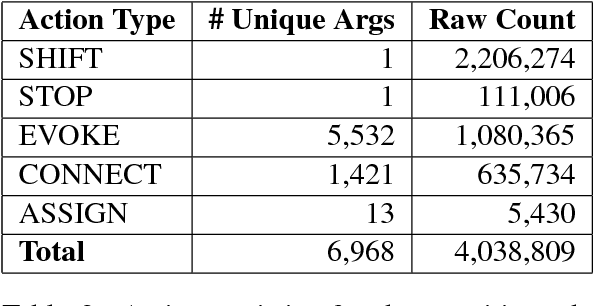
We describe SLING, a framework for parsing natural language into semantic frames. SLING supports general transition-based, neural-network parsing with bidirectional LSTM input encoding and a Transition Based Recurrent Unit (TBRU) for output decoding. The parsing model is trained end-to-end using only the text tokens as input. The transition system has been designed to output frame graphs directly without any intervening symbolic representation. The SLING framework includes an efficient and scalable frame store implementation as well as a neural network JIT compiler for fast inference during parsing. SLING is implemented in C++ and it is available for download on GitHub.
Similarity-Based Models of Word Cooccurrence Probabilities
Sep 27, 1998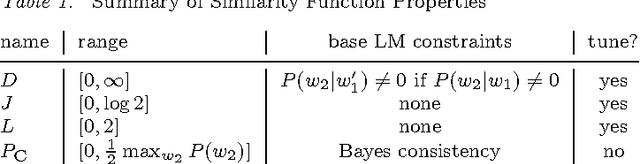
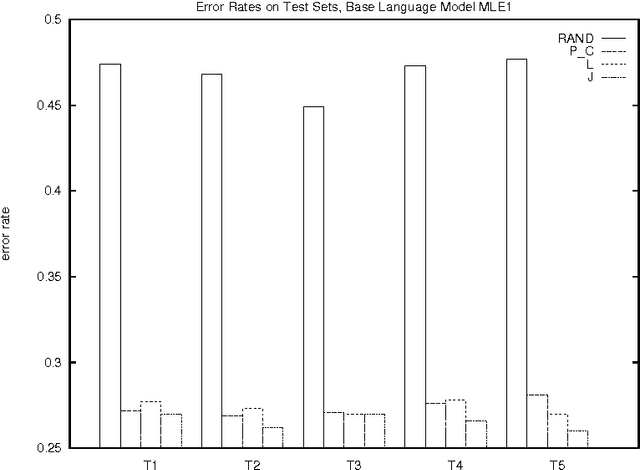

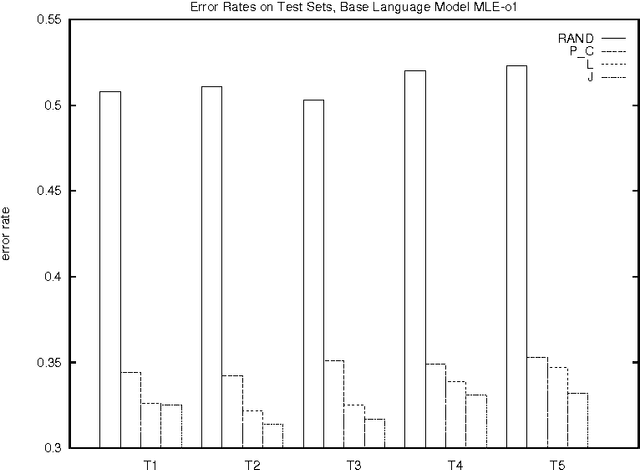
In many applications of natural language processing (NLP) it is necessary to determine the likelihood of a given word combination. For example, a speech recognizer may need to determine which of the two word combinations ``eat a peach'' and ``eat a beach'' is more likely. Statistical NLP methods determine the likelihood of a word combination from its frequency in a training corpus. However, the nature of language is such that many word combinations are infrequent and do not occur in any given corpus. In this work we propose a method for estimating the probability of such previously unseen word combinations using available information on ``most similar'' words. We describe probabilistic word association models based on distributional word similarity, and apply them to two tasks, language modeling and pseudo-word disambiguation. In the language modeling task, a similarity-based model is used to improve probability estimates for unseen bigrams in a back-off language model. The similarity-based method yields a 20% perplexity improvement in the prediction of unseen bigrams and statistically significant reductions in speech-recognition error. We also compare four similarity-based estimation methods against back-off and maximum-likelihood estimation methods on a pseudo-word sense disambiguation task in which we controlled for both unigram and bigram frequency to avoid giving too much weight to easy-to-disambiguate high-frequency configurations. The similarity-based methods perform up to 40% better on this particular task.
* 26 pages, 5 figures
Beyond Word N-Grams
Jul 13, 1996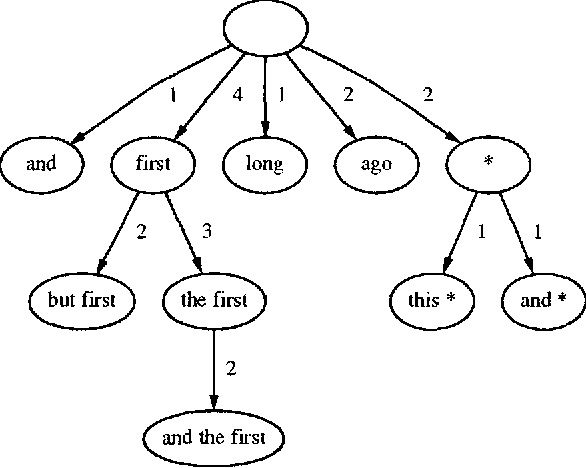
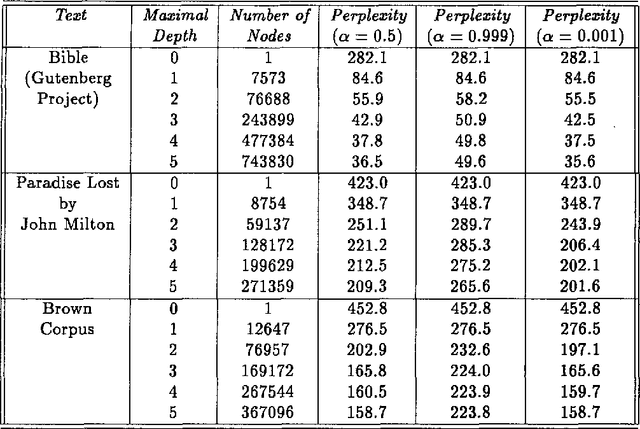
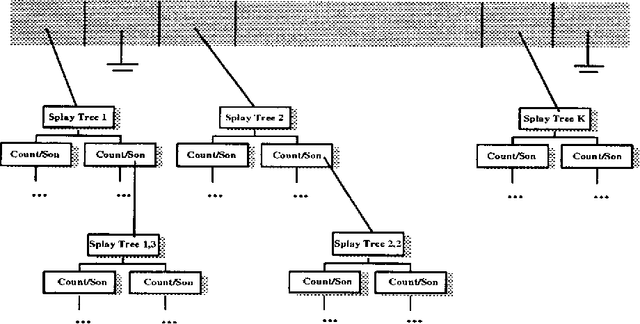
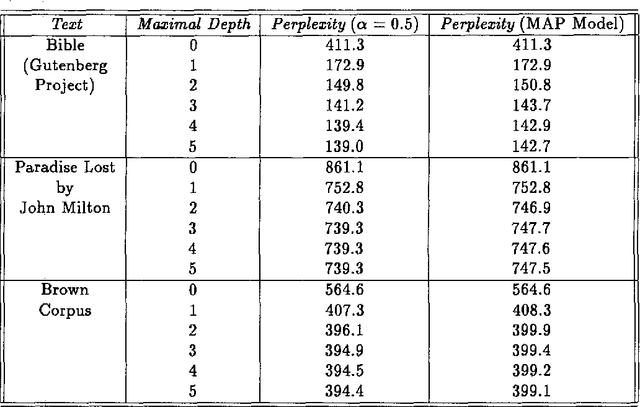
We describe, analyze, and evaluate experimentally a new probabilistic model for word-sequence prediction in natural language based on prediction suffix trees (PSTs). By using efficient data structures, we extend the notion of PST to unbounded vocabularies. We also show how to use a Bayesian approach based on recursive priors over all possible PSTs to efficiently maintain tree mixtures. These mixtures have provably and practically better performance than almost any single model. We evaluate the model on several corpora. The low perplexity achieved by relatively small PST mixture models suggests that they may be an advantageous alternative, both theoretically and practically, to the widely used n-gram models.
Finite-State Approximation of Phrase-Structure Grammars
Mar 08, 1996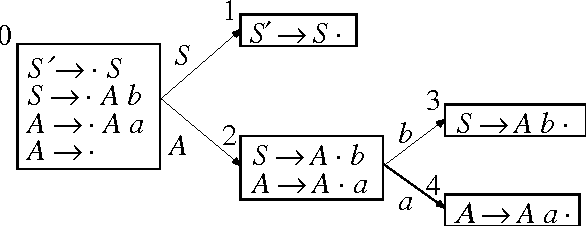
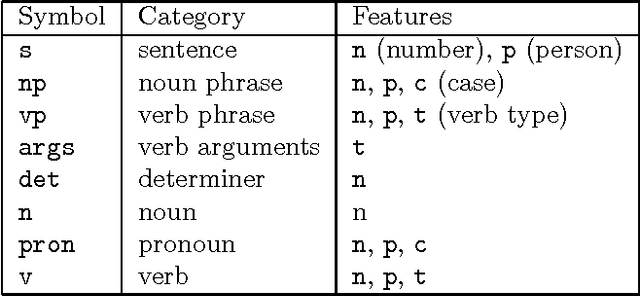
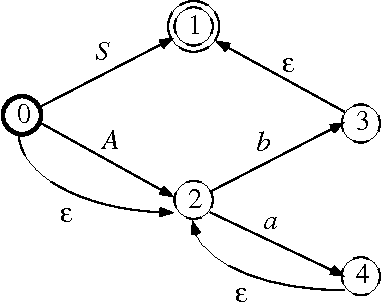

Phrase-structure grammars are effective models for important syntactic and semantic aspects of natural languages, but can be computationally too demanding for use as language models in real-time speech recognition. Therefore, finite-state models are used instead, even though they lack expressive power. To reconcile those two alternatives, we designed an algorithm to compute finite-state approximations of context-free grammars and context-free-equivalent augmented phrase-structure grammars. The approximation is exact for certain context-free grammars generating regular languages, including all left-linear and right-linear context-free grammars. The algorithm has been used to build finite-state language models for limited-domain speech recognition tasks.
Speech Recognition by Composition of Weighted Finite Automata
Mar 07, 1996

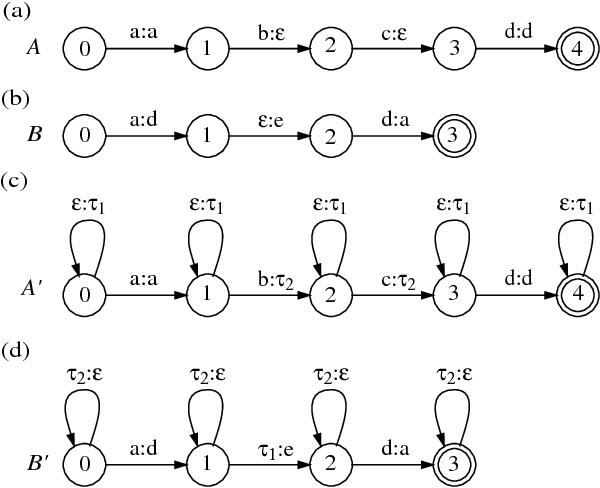
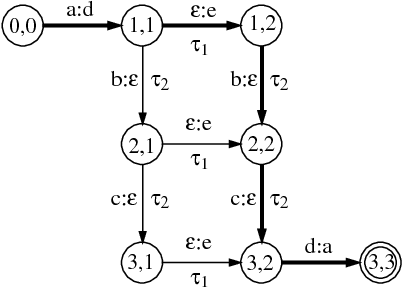
We present a general framework based on weighted finite automata and weighted finite-state transducers for describing and implementing speech recognizers. The framework allows us to represent uniformly the information sources and data structures used in recognition, including context-dependent units, pronunciation dictionaries, language models and lattices. Furthermore, general but efficient algorithms can used for combining information sources in actual recognizers and for optimizing their application. In particular, a single composition algorithm is used both to combine in advance information sources such as language models and dictionaries, and to combine acoustic observations and information sources dynamically during recognition.
Ellipsis and Higher-Order Unification
Mar 08, 1995We present a new method for characterizing the interpretive possibilities generated by elliptical constructions in natural language. Unlike previous analyses, which postulate ambiguity of interpretation or derivation in the full clause source of the ellipsis, our analysis requires no such hidden ambiguity. Further, the analysis follows relatively directly from an abstract statement of the ellipsis interpretation problem. It predicts correctly a wide range of interactions between ellipsis and other semantic phenomena such as quantifier scope and bound anaphora. Finally, although the analysis itself is stated nonprocedurally, it admits of a direct computational method for generating interpretations.
* 54 pages
Principles and Implementation of Deductive Parsing
Apr 26, 1994



We present a system for generating parsers based directly on the metaphor of parsing as deduction. Parsing algorithms can be represented directly as deduction systems, and a single deduction engine can interpret such deduction systems so as to implement the corresponding parser. The method generalizes easily to parsers for augmented phrase structure formalisms, such as definite-clause grammars and other logic grammar formalisms, and has been used for rapid prototyping of parsing algorithms for a variety of formalisms including variants of tree-adjoining grammars, categorial grammars, and lexicalized context-free grammars.