 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimilarity-Based Models of Word Cooccurrence Probabilities
Paper and Code
Sep 27, 1998
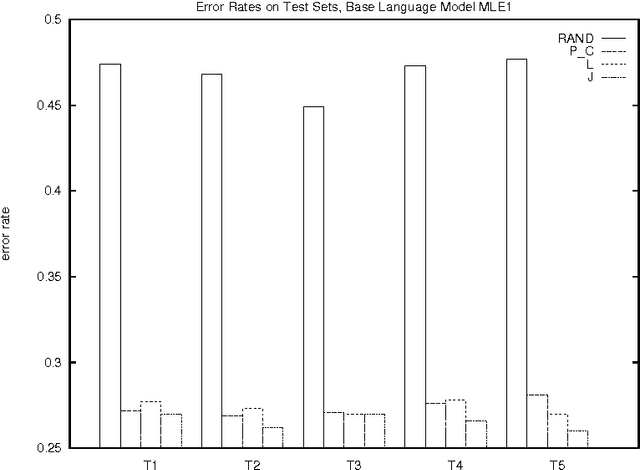

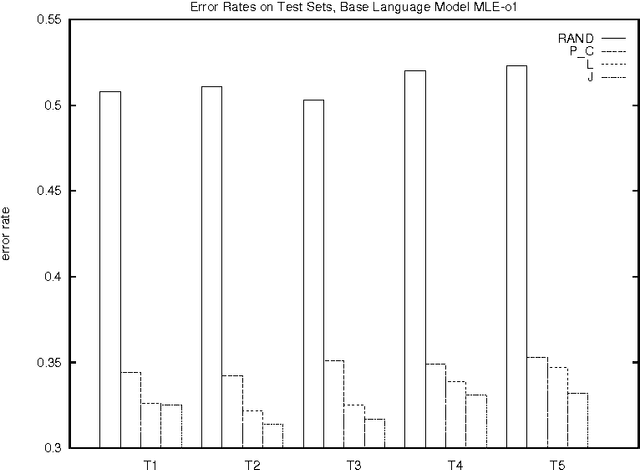
In many applications of natural language processing (NLP) it is necessary to determine the likelihood of a given word combination. For example, a speech recognizer may need to determine which of the two word combinations ``eat a peach'' and ``eat a beach'' is more likely. Statistical NLP methods determine the likelihood of a word combination from its frequency in a training corpus. However, the nature of language is such that many word combinations are infrequent and do not occur in any given corpus. In this work we propose a method for estimating the probability of such previously unseen word combinations using available information on ``most similar'' words. We describe probabilistic word association models based on distributional word similarity, and apply them to two tasks, language modeling and pseudo-word disambiguation. In the language modeling task, a similarity-based model is used to improve probability estimates for unseen bigrams in a back-off language model. The similarity-based method yields a 20% perplexity improvement in the prediction of unseen bigrams and statistically significant reductions in speech-recognition error. We also compare four similarity-based estimation methods against back-off and maximum-likelihood estimation methods on a pseudo-word sense disambiguation task in which we controlled for both unigram and bigram frequency to avoid giving too much weight to easy-to-disambiguate high-frequency configurations. The similarity-based methods perform up to 40% better on this particular task.