Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Recognition by Composition of Weighted Finite Automata
Paper and Code
Mar 07, 1996

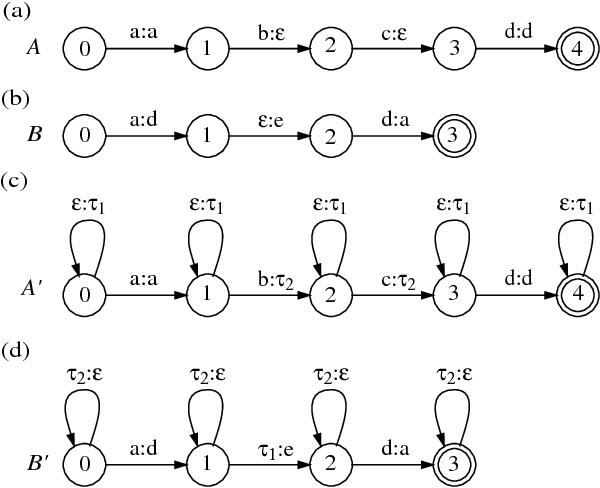
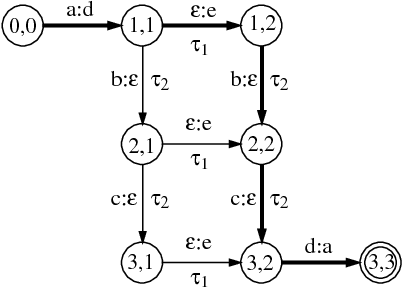
We present a general framework based on weighted finite automata and weighted finite-state transducers for describing and implementing speech recognizers. The framework allows us to represent uniformly the information sources and data structures used in recognition, including context-dependent units, pronunciation dictionaries, language models and lattices. Furthermore, general but efficient algorithms can used for combining information sources in actual recognizers and for optimizing their application. In particular, a single composition algorithm is used both to combine in advance information sources such as language models and dictionaries, and to combine acoustic observations and information sources dynamically during recognition.
* 24 pages, uses psfig.sty
View paper on