 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Winnow-Based Approach to Context-Sensitive Spelling Correction
Oct 31, 1998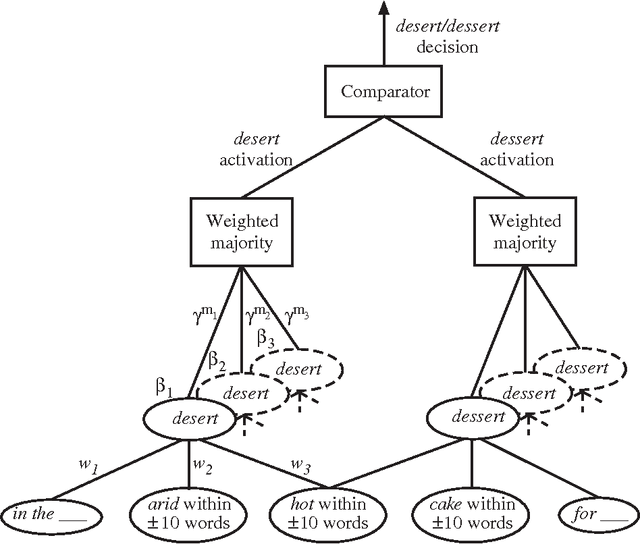
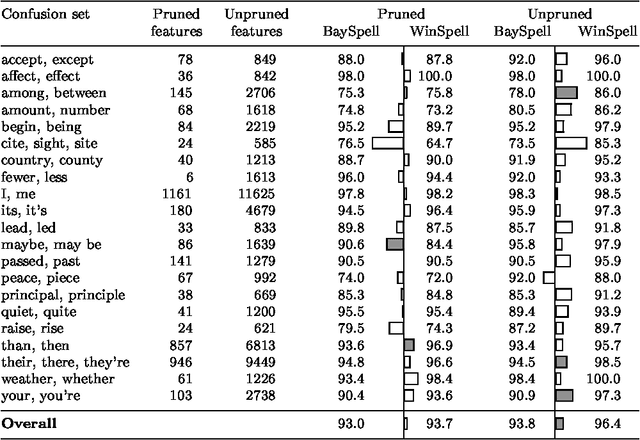
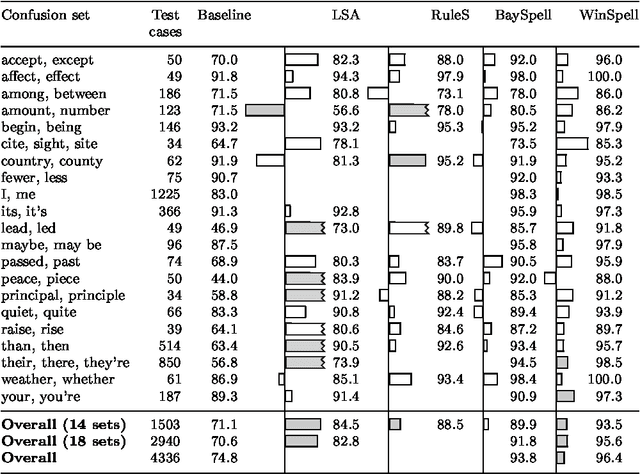
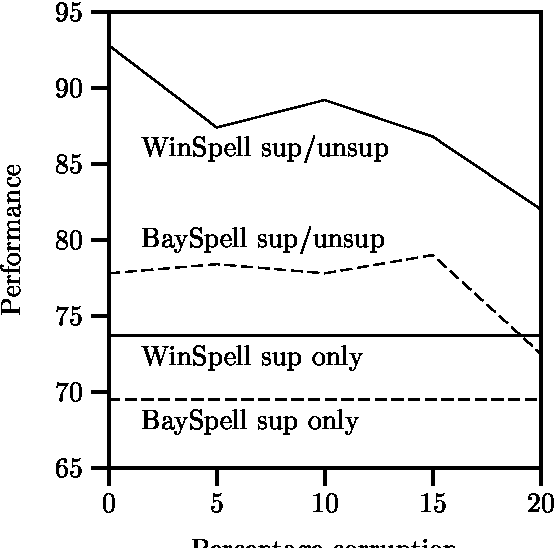
A large class of machine-learning problems in natural language require the characterization of linguistic context. Two characteristic properties of such problems are that their feature space is of very high dimensionality, and their target concepts refer to only a small subset of the features in the space. Under such conditions, multiplicative weight-update algorithms such as Winnow have been shown to have exceptionally good theoretical properties. We present an algorithm combining variants of Winnow and weighted-majority voting, and apply it to a problem in the aforementioned class: context-sensitive spelling correction. This is the task of fixing spelling errors that happen to result in valid words, such as substituting "to" for "too", "casual" for "causal", etc. We evaluate our algorithm, WinSpell, by comparing it against BaySpell, a statistics-based method representing the state of the art for this task. We find: (1) When run with a full (unpruned) set of features, WinSpell achieves accuracies significantly higher than BaySpell was able to achieve in either the pruned or unpruned condition; (2) When compared with other systems in the literature, WinSpell exhibits the highest performance; (3) The primary reason that WinSpell outperforms BaySpell is that WinSpell learns a better linear separator; (4) When run on a test set drawn from a different corpus than the training set was drawn from, WinSpell is better able than BaySpell to adapt, using a strategy we will present that combines supervised learning on the training set with unsupervised learning on the (noisy) test set.
Applying Winnow to Context-Sensitive Spelling Correction
Jul 19, 1996Multiplicative weight-updating algorithms such as Winnow have been studied extensively in the COLT literature, but only recently have people started to use them in applications. In this paper, we apply a Winnow-based algorithm to a task in natural language: context-sensitive spelling correction. This is the task of fixing spelling errors that happen to result in valid words, such as substituting {\it to\/} for {\it too}, {\it casual\/} for {\it causal}, and so on. Previous approaches to this problem have been statistics-based; we compare Winnow to one of the more successful such approaches, which uses Bayesian classifiers. We find that: (1)~When the standard (heavily-pruned) set of features is used to describe problem instances, Winnow performs comparably to the Bayesian method; (2)~When the full (unpruned) set of features is used, Winnow is able to exploit the new features and convincingly outperform Bayes; and (3)~When a test set is encountered that is dissimilar to the training set, Winnow is better than Bayes at adapting to the unfamiliar test set, using a strategy we will present for combining learning on the training set with unsupervised learning on the (noisy) test set.
Combining Trigram-based and Feature-based Methods for Context-Sensitive Spelling Correction
Jun 03, 1996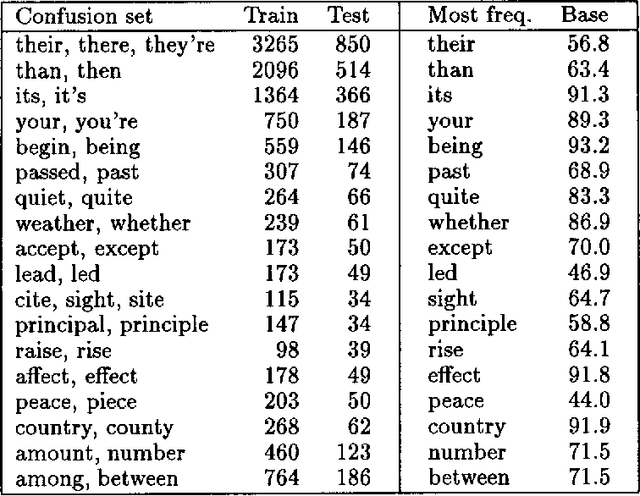
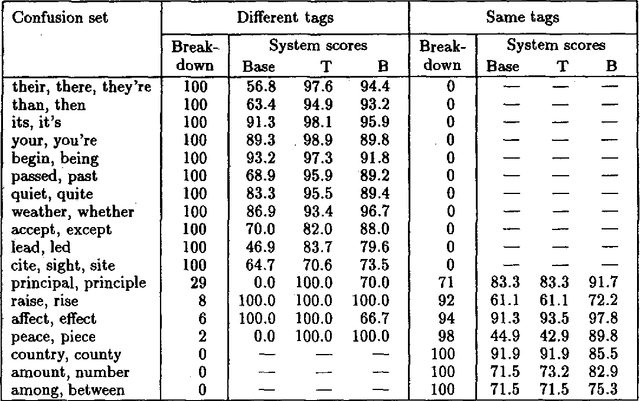
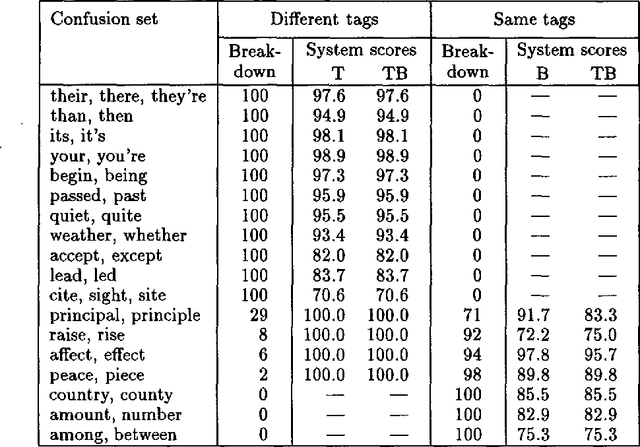
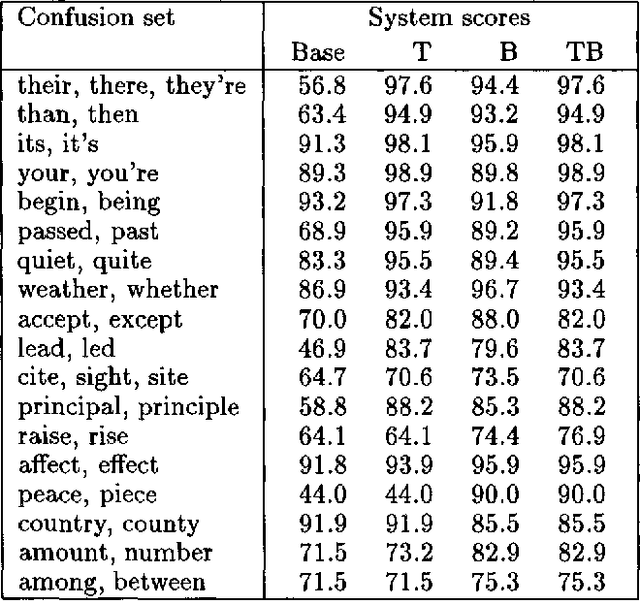
This paper addresses the problem of correcting spelling errors that result in valid, though unintended words (such as ``peace'' and ``piece'', or ``quiet'' and ``quite'') and also the problem of correcting particular word usage errors (such as ``amount'' and ``number'', or ``among'' and ``between''). Such corrections require contextual information and are not handled by conventional spelling programs such as Unix `spell'. First, we introduce a method called Trigrams that uses part-of-speech trigrams to encode the context. This method uses a small number of parameters compared to previous methods based on word trigrams. However, it is effectively unable to distinguish among words that have the same part of speech. For this case, an alternative feature-based method called Bayes performs better; but Bayes is less effective than Trigrams when the distinction among words depends on syntactic constraints. A hybrid method called Tribayes is then introduced that combines the best of the previous two methods. The improvement in performance of Tribayes over its components is verified experimentally. Tribayes is also compared with the grammar checker in Microsoft Word, and is found to have substantially higher performance.
A Bayesian hybrid method for context-sensitive spelling correction
Jun 03, 1996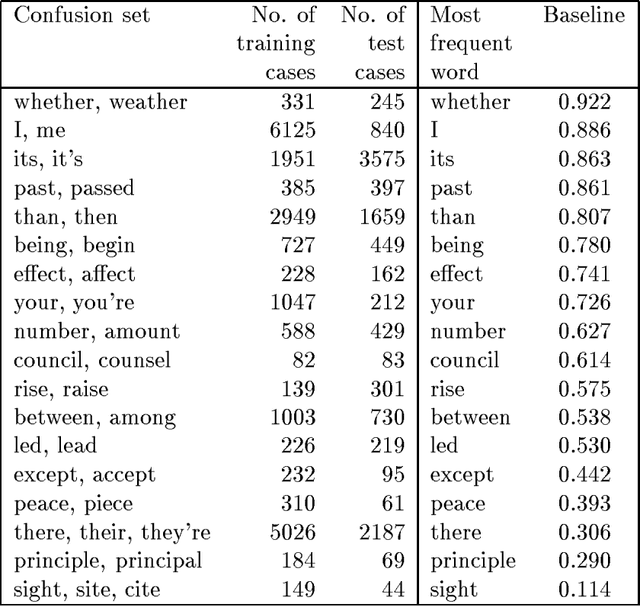

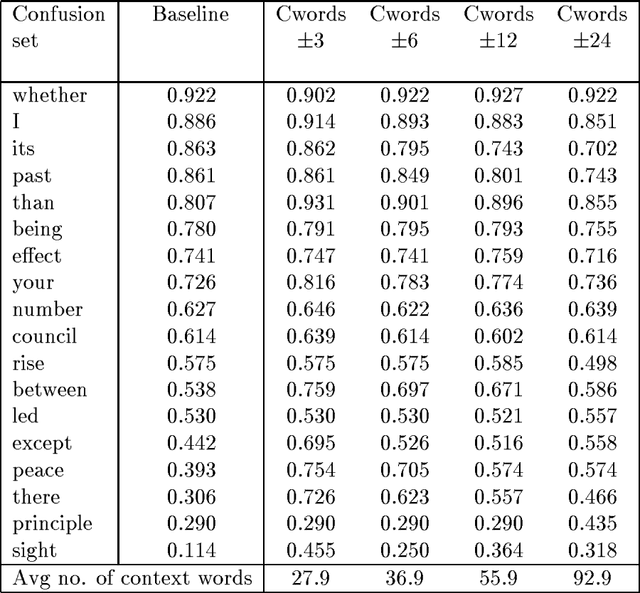

Two classes of methods have been shown to be useful for resolving lexical ambiguity. The first relies on the presence of particular words within some distance of the ambiguous target word; the second uses the pattern of words and part-of-speech tags around the target word. These methods have complementary coverage: the former captures the lexical ``atmosphere'' (discourse topic, tense, etc.), while the latter captures local syntax. Yarowsky has exploited this complementarity by combining the two methods using decision lists. The idea is to pool the evidence provided by the component methods, and to then solve a target problem by applying the single strongest piece of evidence, whatever type it happens to be. This paper takes Yarowsky's work as a starting point, applying decision lists to the problem of context-sensitive spelling correction. Decision lists are found, by and large, to outperform either component method. However, it is found that further improvements can be obtained by taking into account not just the single strongest piece of evidence, but ALL the available evidence. A new hybrid method, based on Bayesian classifiers, is presented for doing this, and its performance improvements are demonstrated.