 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Winnow-Based Approach to Context-Sensitive Spelling Correction
Paper and Code
Oct 31, 1998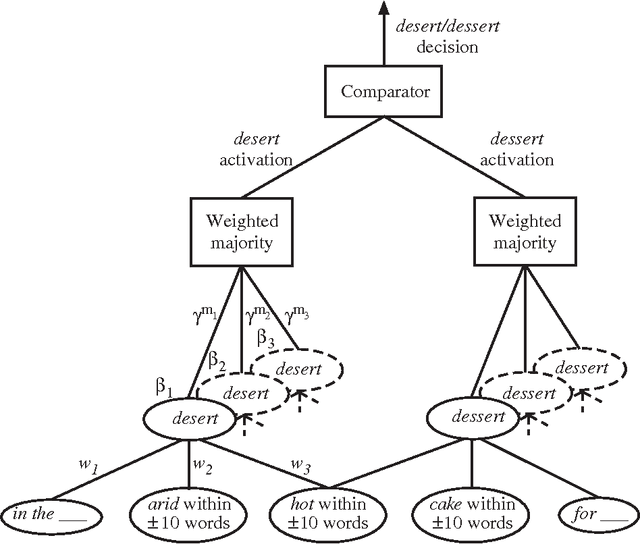
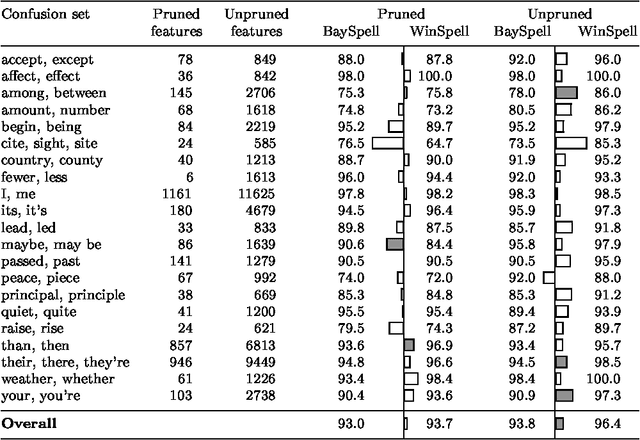
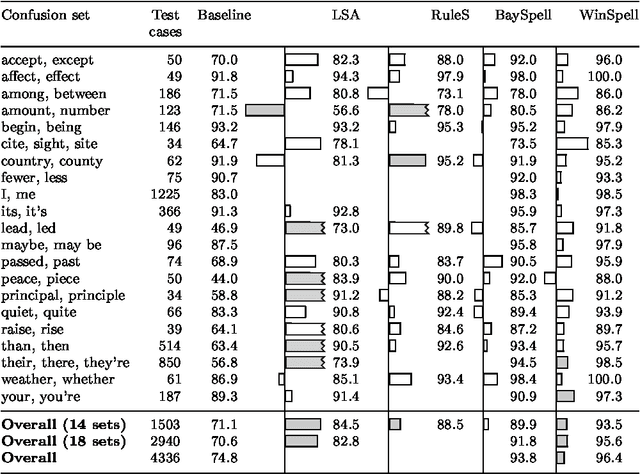
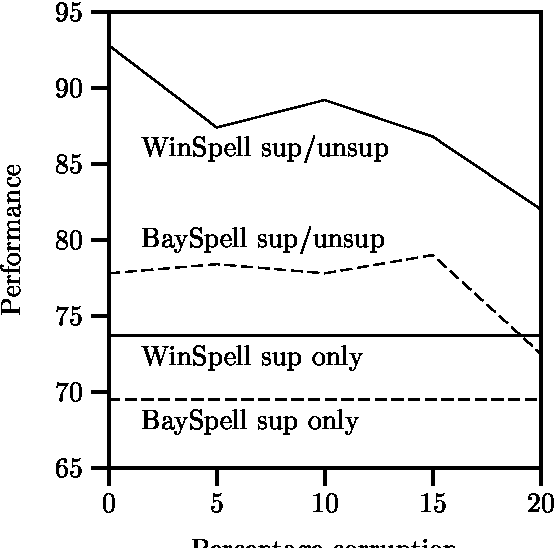
A large class of machine-learning problems in natural language require the characterization of linguistic context. Two characteristic properties of such problems are that their feature space is of very high dimensionality, and their target concepts refer to only a small subset of the features in the space. Under such conditions, multiplicative weight-update algorithms such as Winnow have been shown to have exceptionally good theoretical properties. We present an algorithm combining variants of Winnow and weighted-majority voting, and apply it to a problem in the aforementioned class: context-sensitive spelling correction. This is the task of fixing spelling errors that happen to result in valid words, such as substituting "to" for "too", "casual" for "causal", etc. We evaluate our algorithm, WinSpell, by comparing it against BaySpell, a statistics-based method representing the state of the art for this task. We find: (1) When run with a full (unpruned) set of features, WinSpell achieves accuracies significantly higher than BaySpell was able to achieve in either the pruned or unpruned condition; (2) When compared with other systems in the literature, WinSpell exhibits the highest performance; (3) The primary reason that WinSpell outperforms BaySpell is that WinSpell learns a better linear separator; (4) When run on a test set drawn from a different corpus than the training set was drawn from, WinSpell is better able than BaySpell to adapt, using a strategy we will present that combines supervised learning on the training set with unsupervised learning on the (noisy) test set.