 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKorean to English Translation Using Synchronous TAGs
Paper and Code
Oct 24, 1994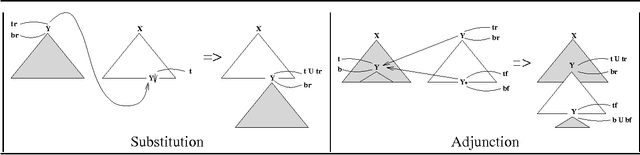
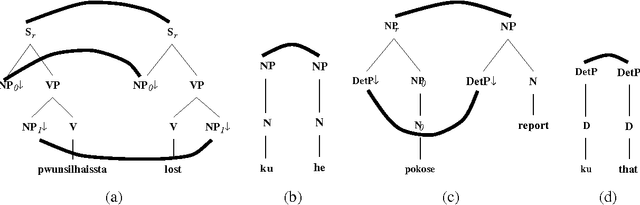
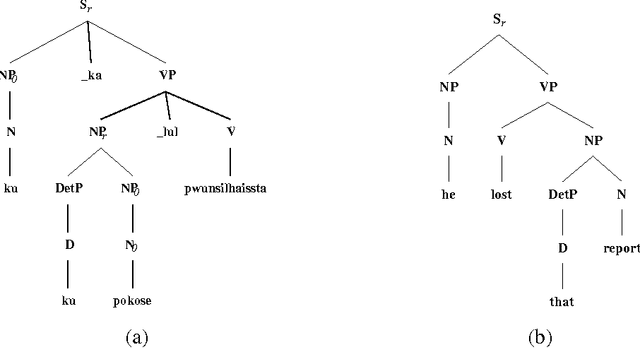
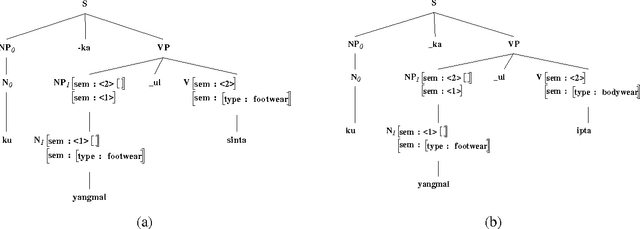
It is often argued that accurate machine translation requires reference to contextual knowledge for the correct treatment of linguistic phenomena such as dropped arguments and accurate lexical selection. One of the historical arguments in favor of the interlingua approach has been that, since it revolves around a deep semantic representation, it is better able to handle the types of linguistic phenomena that are seen as requiring a knowledge-based approach. In this paper we present an alternative approach, exemplified by a prototype system for machine translation of English and Korean which is implemented in Synchronous TAGs. This approach is essentially transfer based, and uses semantic feature unification for accurate lexical selection of polysemous verbs. The same semantic features, when combined with a discourse model which stores previously mentioned entities, can also be used for the recovery of topicalized arguments. In this paper we concentrate on the translation of Korean to English.