 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Part-of-Speech Tagger for Yiddish: First Steps in Tagging the Yiddish Book Center Corpus
Apr 03, 2022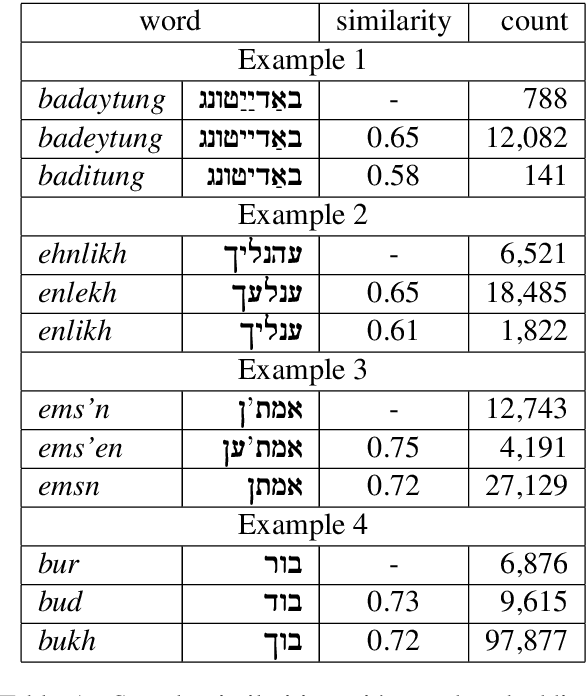
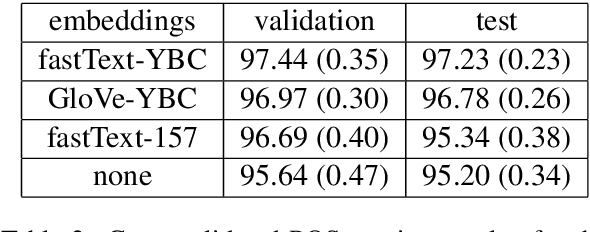
We describe the construction and evaluation of a part-of-speech tagger for Yiddish (the first one, to the best of our knowledge). This is the first step in a larger project of automatically assigning part-of-speech tags and syntactic structure to Yiddish text for purposes of linguistic research. We combine two resources for the current work - an 80K word subset of the Penn Parsed Corpus of Historical Yiddish (PPCHY) (Santorini, 2021) and 650 million words of OCR'd Yiddish text from the Yiddish Book Center (YBC). We compute word embeddings on the YBC corpus, and these embeddings are used with a tagger model trained and evaluated on the PPCHY. Yiddish orthography in the YBC corpus has many spelling inconsistencies, and we present some evidence that even simple non-contextualized embeddings are able to capture the relationships among spelling variants without the need to first "standardize" the corpus. We evaluate the tagger performance on a 10-fold cross-validation split, with and without the embeddings, showing that the embeddings improve tagger performance. However, a great deal of work remains to be done, and we conclude by discussing some next steps, including the need for additional annotated training and test data.
Penn-Helsinki Parsed Corpus of Early Modern English: First Parsing Results and Analysis
Dec 15, 2021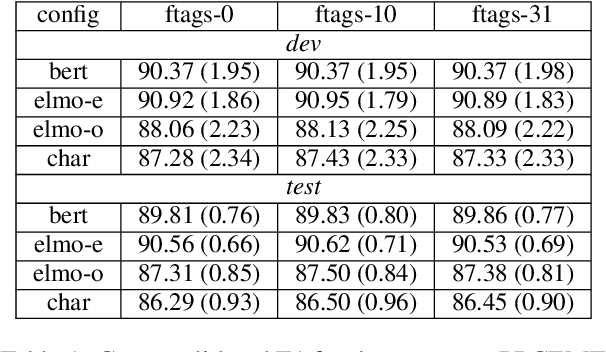
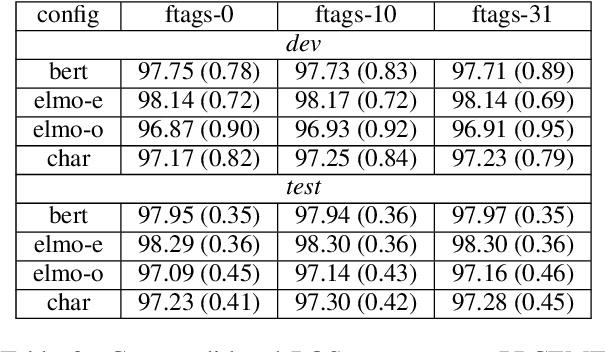
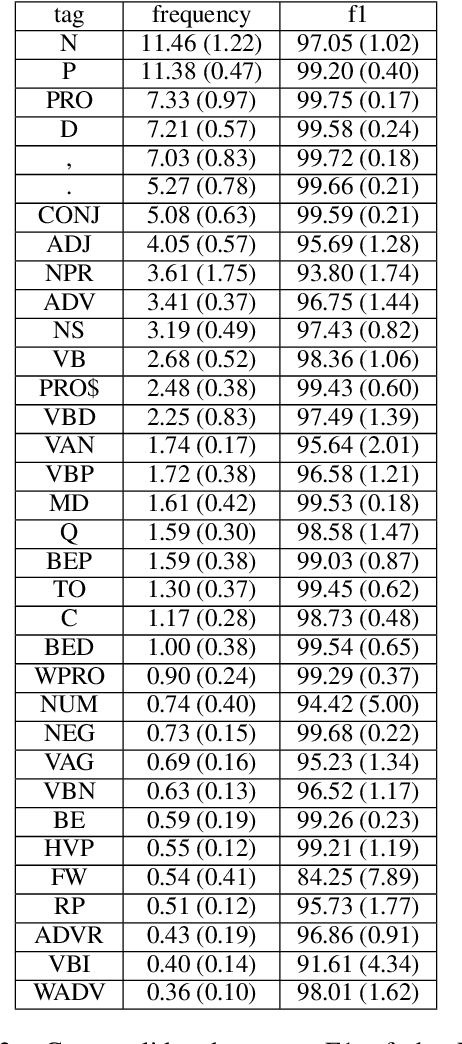
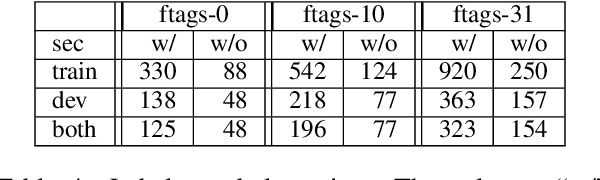
We present the first parsing results on the Penn-Helsinki Parsed Corpus of Early Modern English (PPCEME), a 1.9 million word treebank that is an important resource for research in syntactic change. We describe key features of PPCEME that make it challenging for parsing, including a larger and more varied set of function tags than in the Penn Treebank. We present results for this corpus using a modified version of the Berkeley Neural Parser and the approach to function tag recovery of Gabbard et al (2006). Despite its simplicity, this approach works surprisingly well, suggesting it is possible to recover the original structure with sufficient accuracy to support linguistic applications (e.g., searching for syntactic structures of interest). However, for a subset of function tags (e.g., the tag indicating direct speech), additional work is needed, and we discuss some further limits of this approach. The resulting parser will be used to parse Early English Books Online, a 1.1 billion word corpus whose utility for the study of syntactic change will be greatly increased with the addition of accurate parse trees.
Adnominal adjectives, code-switching and lexicalized TAG
Nov 05, 1994In codeswitching contexts, the language of a syntactic head determines the distribution of its complements. Mahootian 1993 derives this generalization by representing heads as the anchors of elementary trees in a lexicalized TAG. However, not all codeswitching sequences are amenable to a head-complement analysis. For instance, adnominal adjectives can occupy positions not available to them in their own language, and the TAG derivation of such sequences must use unanchored auxiliary trees. palabras heavy-duty `heavy-duty words' (Spanish-English; Poplack 1980:584) taste lousy sana `very lousy taste' (English-Swahili; Myers-Scotton 1993:29, (10)) Given the null hypothesis that codeswitching and monolingual sequences are derived in an identical manner, sequences like those above provide evidence that pure lexicalized TAGs are inadequate for the description of natural language.