 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Second DIHARD Diarization Challenge: Dataset, task, and baselines
Jun 18, 2019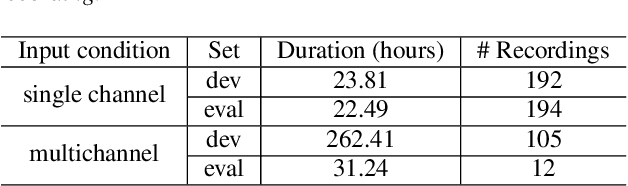
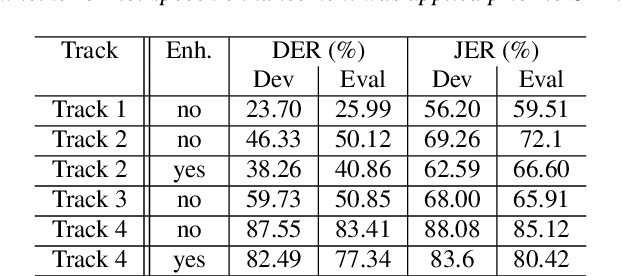
This paper introduces the second DIHARD challenge, the second in a series of speaker diarization challenges intended to improve the robustness of diarization systems to variation in recording equipment, noise conditions, and conversational domain. The challenge comprises four tracks evaluating diarization performance under two input conditions (single channel vs. multi-channel) and two segmentation conditions (diarization from a reference speech segmentation vs. diarization from scratch). In order to prevent participants from overtuning to a particular combination of recording conditions and conversational domain, recordings are drawn from a variety of sources ranging from read audiobooks to meeting speech, to child language acquisition recordings, to dinner parties, to web video. We describe the task and metrics, challenge design, datasets, and baseline systems for speech enhancement, speech activity detection, and diarization.
Annotation Graphs and Servers and Multi-Modal Resources: Infrastructure for Interdisciplinary Education, Research and Development
Apr 10, 2002

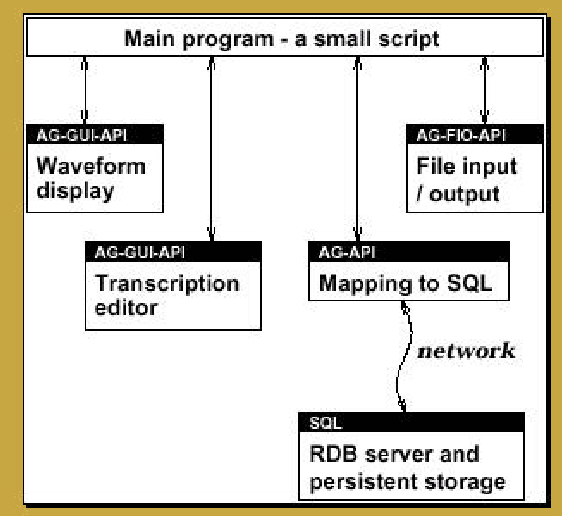
Annotation graphs and annotation servers offer infrastructure to support the analysis of human language resources in the form of time-series data such as text, audio and video. This paper outlines areas of common need among empirical linguists and computational linguists. After reviewing examples of data and tools used or under development for each of several areas, it proposes a common framework for future tool development, data annotation and resource sharing based upon annotation graphs and servers.
* 8 pages, 6 figures