 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBig AI is accelerating the metacrisis: What can we do?
Dec 31, 2025The world is in the grip of ecological, meaning, and language crises which are converging into a metacrisis. Big AI is accelerating them all. Language engineers are playing a central role, persisting with a scalability story that is failing humanity, supplying critical talent to plutocrats and kleptocrats, and creating new technologies as if the whole endeavour was value-free. We urgently need to explore alternatives, applying our collective intelligence to design a life-affirming future for NLP that is centered on human flourishing on a living planet.
Spoken Term Detection Methods for Sparse Transcription in Very Low-resource Settings
Jun 11, 2021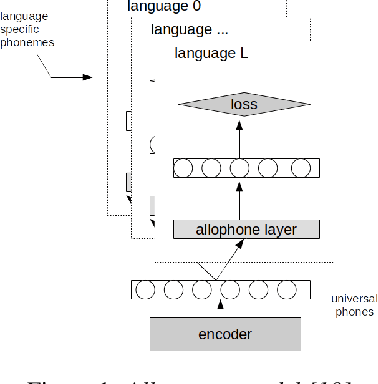
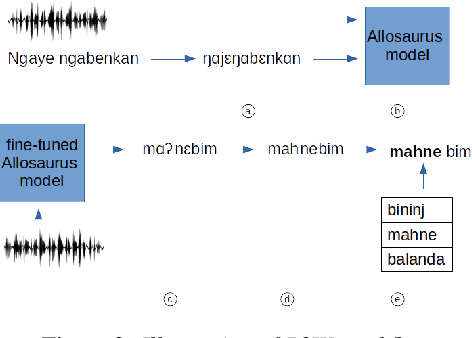
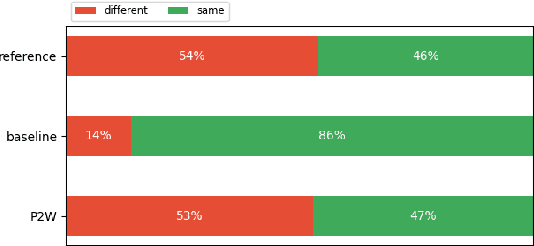
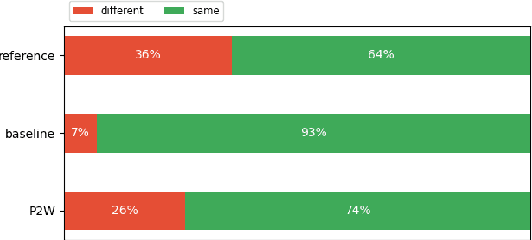
We investigate the efficiency of two very different spoken term detection approaches for transcription when the available data is insufficient to train a robust ASR system. This work is grounded in very low-resource language documentation scenario where only few minutes of recording have been transcribed for a given language so far.Experiments on two oral languages show that a pretrained universal phone recognizer, fine-tuned with only a few minutes of target language speech, can be used for spoken term detection with a better overall performance than a dynamic time warping approach. In addition, we show that representing phoneme recognition ambiguity in a graph structure can further boost the recall while maintaining high precision in the low resource spoken term detection task.
Enabling Interactive Transcription in an Indigenous Community
Nov 12, 2020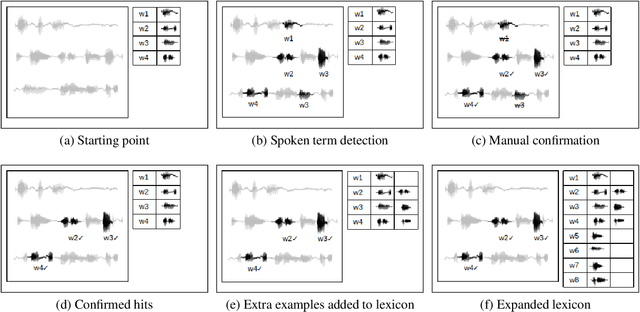
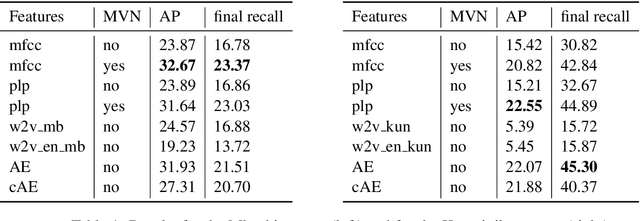
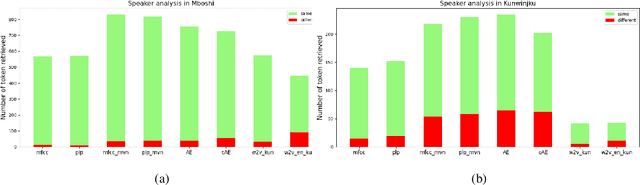
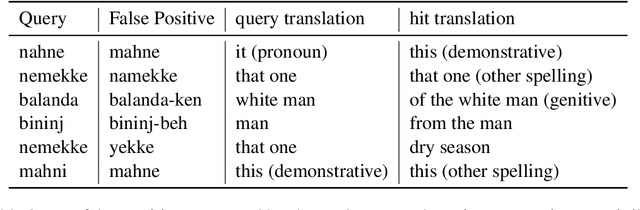
We propose a novel transcription workflow which combines spoken term detection and human-in-the-loop, together with a pilot experiment. This work is grounded in an almost zero-resource scenario where only a few terms have so far been identified, involving two endangered languages. We show that in the early stages of transcription, when the available data is insufficient to train a robust ASR system, it is possible to take advantage of the transcription of a small number of isolated words in order to bootstrap the transcription of a speech collection.
Bootstrapping Techniques for Polysynthetic Morphological Analysis
May 03, 2020
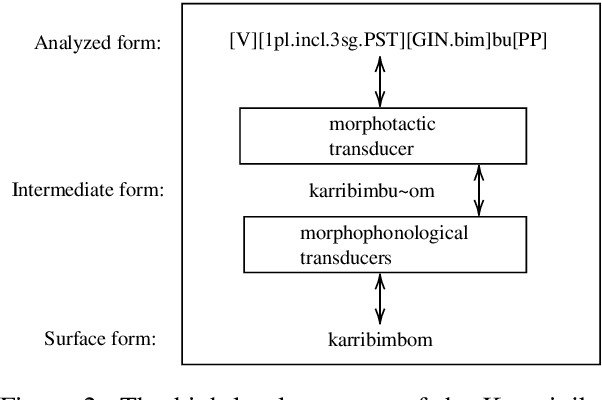

Polysynthetic languages have exceptionally large and sparse vocabularies, thanks to the number of morpheme slots and combinations in a word. This complexity, together with a general scarcity of written data, poses a challenge to the development of natural language technologies. To address this challenge, we offer linguistically-informed approaches for bootstrapping a neural morphological analyzer, and demonstrate its application to Kunwinjku, a polysynthetic Australian language. We generate data from a finite state transducer to train an encoder-decoder model. We improve the model by "hallucinating" missing linguistic structure into the training data, and by resampling from a Zipf distribution to simulate a more natural distribution of morphemes. The best model accounts for all instances of reduplication in the test set and achieves an accuracy of 94.7% overall, a 10 percentage point improvement over the FST baseline. This process demonstrates the feasibility of bootstrapping a neural morph analyzer from minimal resources.
Learning Crosslingual Word Embeddings without Bilingual Corpora
Jun 30, 2016

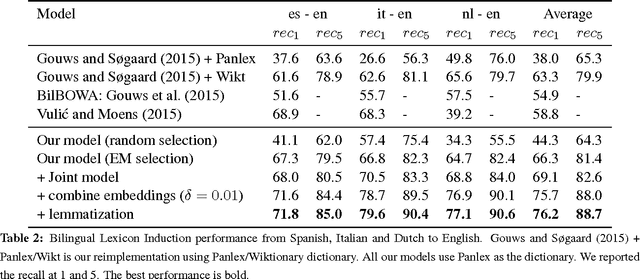
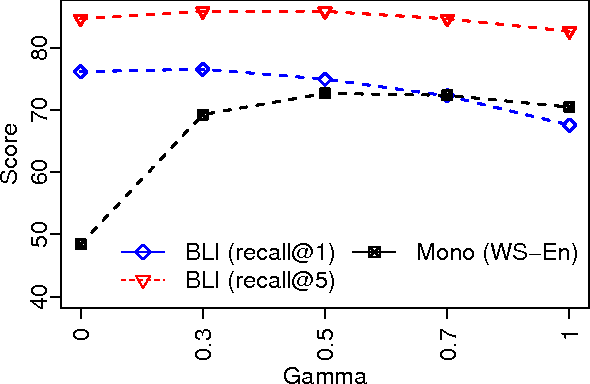
Crosslingual word embeddings represent lexical items from different languages in the same vector space, enabling transfer of NLP tools. However, previous attempts had expensive resource requirements, difficulty incorporating monolingual data or were unable to handle polysemy. We address these drawbacks in our method which takes advantage of a high coverage dictionary in an EM style training algorithm over monolingual corpora in two languages. Our model achieves state-of-the-art performance on bilingual lexicon induction task exceeding models using large bilingual corpora, and competitive results on the monolingual word similarity and cross-lingual document classification task.
Extending Dublin Core Metadata to Support the Description and Discovery of Language Resources
Aug 14, 2003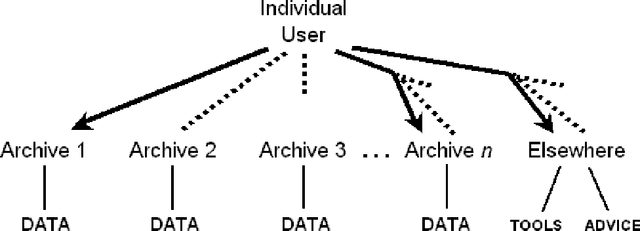
As language data and associated technologies proliferate and as the language resources community expands, it is becoming increasingly difficult to locate and reuse existing resources. Are there any lexical resources for such-and-such a language? What tool works with transcripts in this particular format? What is a good format to use for linguistic data of this type? Questions like these dominate many mailing lists, since web search engines are an unreliable way to find language resources. This paper reports on a new digital infrastructure for discovering language resources being developed by the Open Language Archives Community (OLAC). At the core of OLAC is its metadata format, which is designed to facilitate description and discovery of all kinds of language resources, including data, tools, or advice. The paper describes OLAC metadata, its relationship to Dublin Core metadata, and its dissemination using the metadata harvesting protocol of the Open Archives Initiative.
* 12 pages, 1 figure
A Grid Based Architecture for High-Performance NLP
Aug 05, 2003We describe the design and early implementation of an extensible, component-based software architecture for natural language engineering applications which interfaces with high performance distributed computing services. The architecture leverages existing linguistic resource description and discovery mechanisms based on metadata descriptions, combining these in a compatible fashion with other software definition abstractions. Within this architecture, application design is highly flexible, allowing disparate components to be combined to suit the overall application functionality, and formally described independently of processing concerns. An application specification language provides abstraction from the programming environment and allows ease of interface with high performance computational grids via a broker.
The Open Language Archives Community: An infrastructure for distributed archiving of language resources
Jun 10, 2003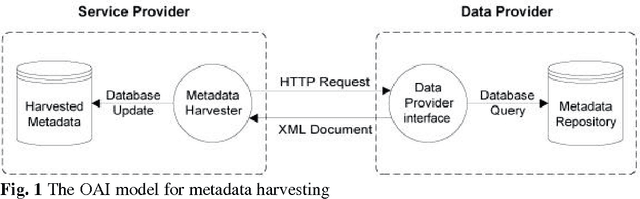
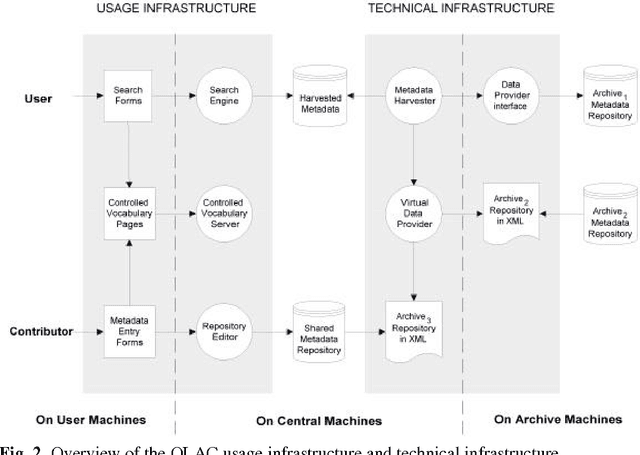
New ways of documenting and describing language via electronic media coupled with new ways of distributing the results via the World-Wide Web offer a degree of access to language resources that is unparalleled in history. At the same time, the proliferation of approaches to using these new technologies is causing serious problems relating to resource discovery and resource creation. This article describes the infrastructure that the Open Language Archives Community (OLAC) has built in order to address these problems. Its technical and usage infrastructures address problems of resource discovery by constructing a single virtual library of distributed resources. Its governance infrastructure addresses problems of resource creation by providing a mechanism through which the language-resource community can express its consensus on recommended best practices.
Grid-Enabling Natural Language Engineering By Stealth
Apr 22, 2003We describe a proposal for an extensible, component-based software architecture for natural language engineering applications. Our model leverages existing linguistic resource description and discovery mechanisms based on extended Dublin Core metadata. In addition, the application design is flexible, allowing disparate components to be combined to suit the overall application functionality. An application specification language provides abstraction from the programming environment and allows ease of interface with computational grids via a broker.
Building an Open Language Archives Community on the OAI Foundation
Feb 14, 2003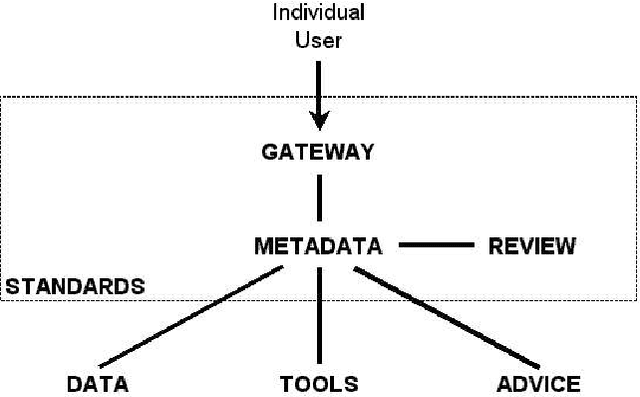
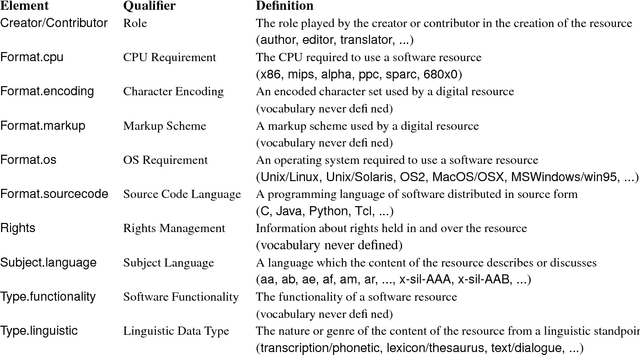

The Open Language Archives Community (OLAC) is an international partnership of institutions and individuals who are creating a worldwide virtual library of language resources. The Dublin Core (DC) Element Set and the OAI Protocol have provided a solid foundation for the OLAC framework. However, we need more precision in community-specific aspects of resource description than is offered by DC. Furthermore, many of the institutions and individuals who might participate in OLAC do not have the technical resources to support the OAI protocol. This paper presents our solutions to these two problems. To address the first, we have developed an extensible application profile for language resource metadata. To address the second, we have implemented Vida (the virtual data provider) and Viser (the virtual service provider), which permit community members to provide data and services without having to implement the OAI protocol. These solutions are generic and could be adopted by other specialized subcommunities.
* 12 pages