 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Speech-to-Text Systems with PennSound
Apr 08, 2025A random sample of nearly 10 hours of speech from PennSound, the world's largest online collection of poetry readings and discussions, was used as a benchmark to evaluate several commercial and open-source speech-to-text systems. PennSound's wide variation in recording conditions and speech styles makes it a good representative for many other untranscribed audio collections. Reference transcripts were created by trained annotators, and system transcripts were produced from AWS, Azure, Google, IBM, NeMo, Rev.ai, Whisper, and Whisper.cpp. Based on word error rate, Rev.ai was the top performer, and Whisper was the top open source performer (as long as hallucinations were avoided). AWS had the best diarization error rates among three systems. However, WER and DER differences were slim, and various tradeoffs may motivate choosing different systems for different end users. We also examine the issue of hallucinations in Whisper. Users of Whisper should be cautioned to be aware of runtime options, and whether the speed vs accuracy trade off is acceptable.
Inferring Pitch from Coarse Spectral Features
Apr 10, 2022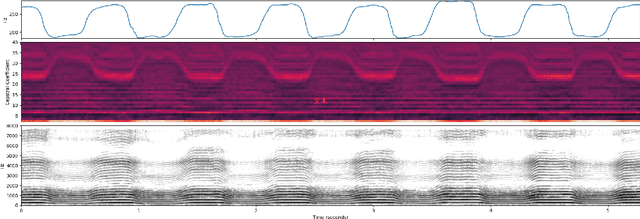
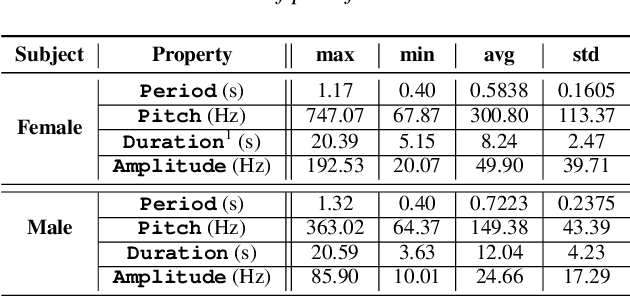
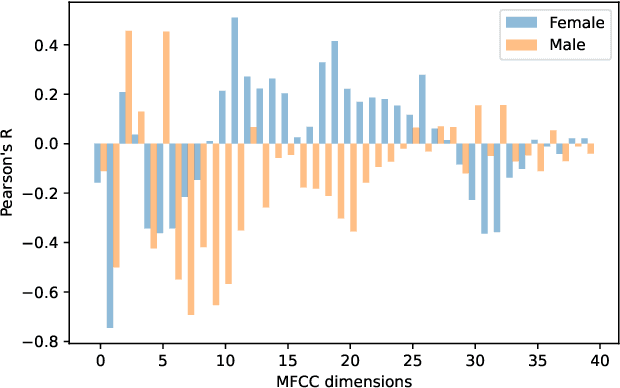
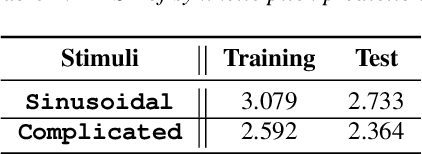
Fundamental frequency (F0) has long been treated as the physical definition of "pitch" in phonetic analysis. But there have been many demonstrations that F0 is at best an approximation to pitch, both in production and in perception: pitch is not F0, and F0 is not pitch. Changes in the pitch involve many articulatory and acoustic covariates; pitch perception often deviates from what F0 analysis predicts; and in fact, quasi-periodic signals from a single voice source are often incompletely characterized by an attempt to define a single time-varying F0. In this paper, we find strong support for the existence of covariates for pitch in aspects of relatively coarse spectra, in which an overtone series is not available. Thus linear regression can predict the pitch of simple vocalizations, produced by an articulatory synthesizer or by human, from single frames of such coarse spectra. Across speakers, and in more complex vocalizations, our experiments indicate that the covariates are not quite so simple, though apparently still available for more sophisticated modeling. On this basis, we propose that the field needs a better way of thinking about speech pitch, just as celestial mechanics requires us to go beyond Newton's point mass approximations to heavenly bodies.
Automatic recognition of suprasegmentals in speech
Aug 04, 2021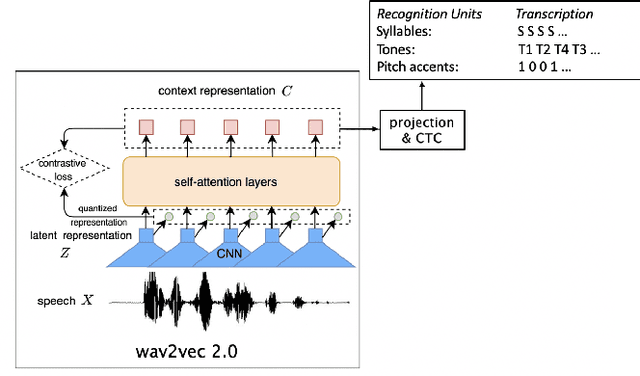
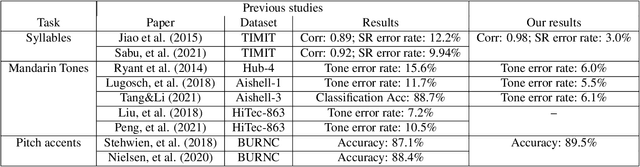
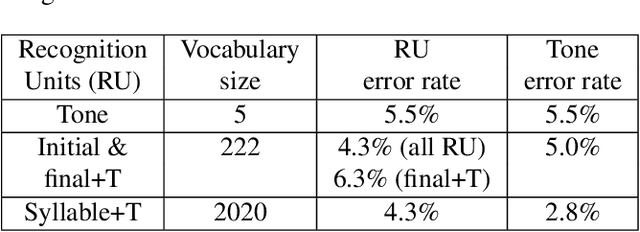
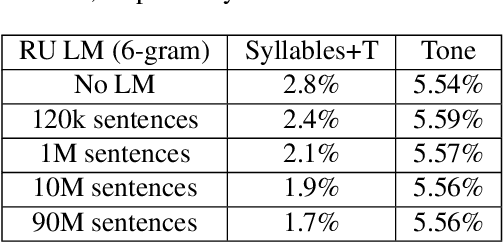
This study reports our efforts to improve automatic recognition of suprasegmentals by fine-tuning wav2vec 2.0 with CTC, a method that has been successful in automatic speech recognition. We demonstrate that the method can improve the state-of-the-art on automatic recognition of syllables, tones, and pitch accents. Utilizing segmental information, by employing tonal finals or tonal syllables as recognition units, can significantly improve Mandarin tone recognition. Language models are helpful when tonal syllables are used as recognition units, but not helpful when tones are recognition units. Finally, Mandarin tone recognition can benefit from English phoneme recognition by combining the two tasks in fine-tuning wav2vec 2.0.
Neural Representations for Modeling Variation in English Speech
Nov 25, 2020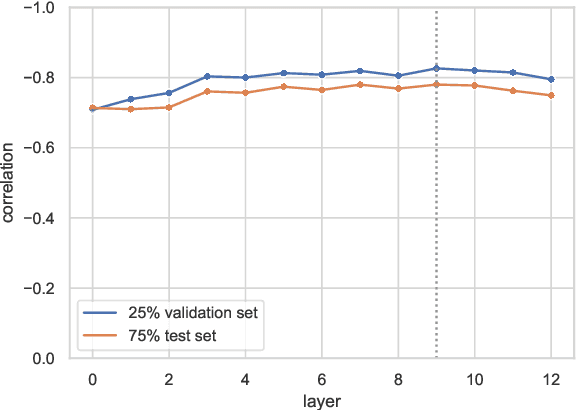
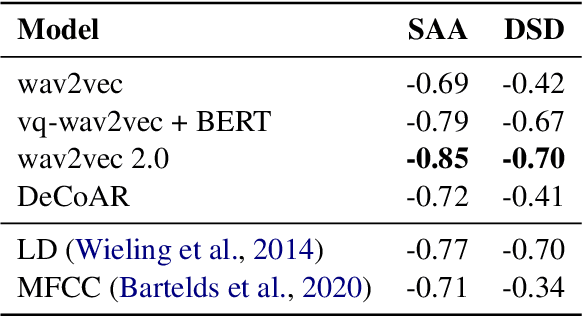
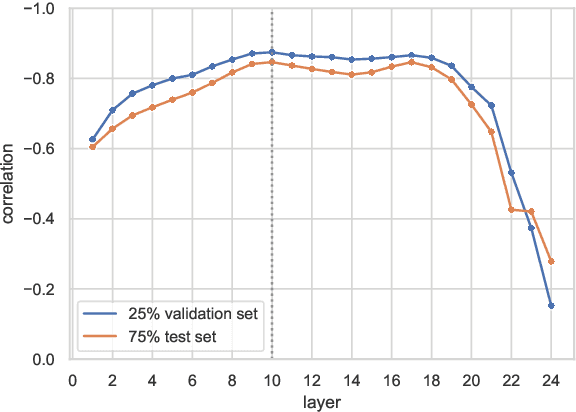
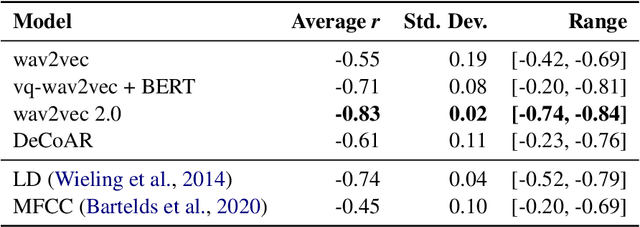
Variation in speech is often represented and investigated using phonetic transcriptions, but transcribing speech is time-consuming and error prone. To create reliable representations of speech independent from phonetic transcriptions, we investigate the extraction of acoustic embeddings from several self-supervised neural models. We use these representations to compute word-based pronunciation differences between non-native and native speakers of English, and evaluate these differences by comparing them with human native-likeness judgments. We show that Transformer-based speech representations lead to significant performance gains over the use of phonetic transcriptions, and find that feature-based use of Transformer models is most effective with one or more middle layers instead of the final layer. We also demonstrate that these neural speech representations not only capture segmental differences, but also intonational and durational differences that cannot be represented by a set of discrete symbols used in phonetic transcriptions.
The Second DIHARD Diarization Challenge: Dataset, task, and baselines
Jun 18, 2019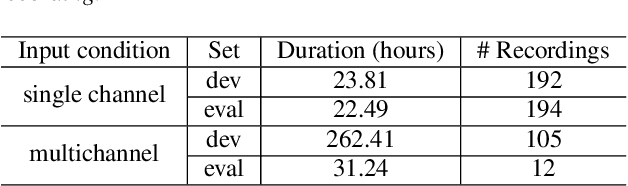
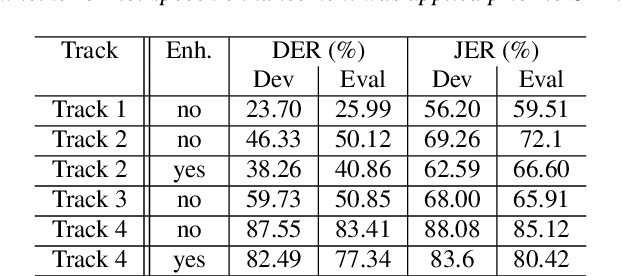
This paper introduces the second DIHARD challenge, the second in a series of speaker diarization challenges intended to improve the robustness of diarization systems to variation in recording equipment, noise conditions, and conversational domain. The challenge comprises four tracks evaluating diarization performance under two input conditions (single channel vs. multi-channel) and two segmentation conditions (diarization from a reference speech segmentation vs. diarization from scratch). In order to prevent participants from overtuning to a particular combination of recording conditions and conversational domain, recordings are drawn from a variety of sources ranging from read audiobooks to meeting speech, to child language acquisition recordings, to dinner parties, to web video. We describe the task and metrics, challenge design, datasets, and baseline systems for speech enhancement, speech activity detection, and diarization.
A Formal Framework for Linguistic Annotation (revised version)
Oct 26, 2000


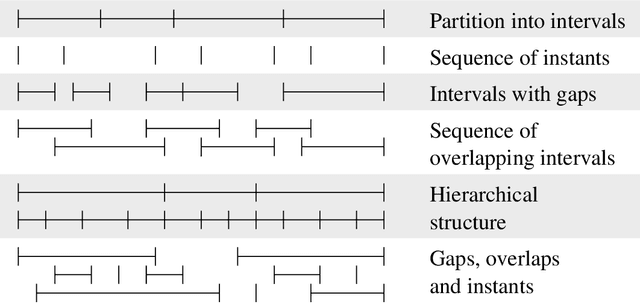
`Linguistic annotation' covers any descriptive or analytic notations applied to raw language data. The basic data may be in the form of time functions - audio, video and/or physiological recordings - or it may be textual. The added notations may include transcriptions of all sorts (from phonetic features to discourse structures), part-of-speech and sense tagging, syntactic analysis, `named entity' identification, co-reference annotation, and so on. While there are several ongoing efforts to provide formats and tools for such annotations and to publish annotated linguistic databases, the lack of widely accepted standards is becoming a critical problem. Proposed standards, to the extent they exist, have focused on file formats. This paper focuses instead on the logical structure of linguistic annotations. We survey a wide variety of existing annotation formats and demonstrate a common conceptual core, the annotation graph. This provides a formal framework for constructing, maintaining and searching linguistic annotations, while remaining consistent with many alternative data structures and file formats.
ATLAS: A flexible and extensible architecture for linguistic annotation
Jul 13, 2000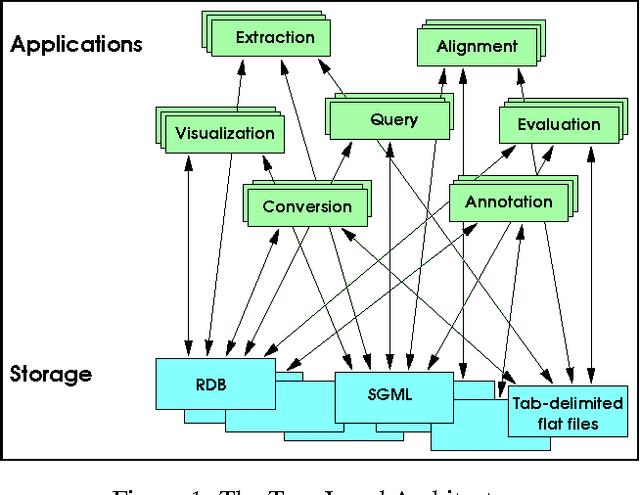
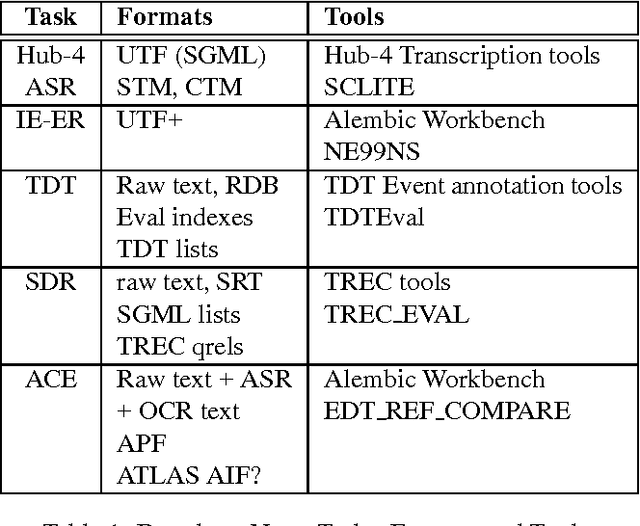
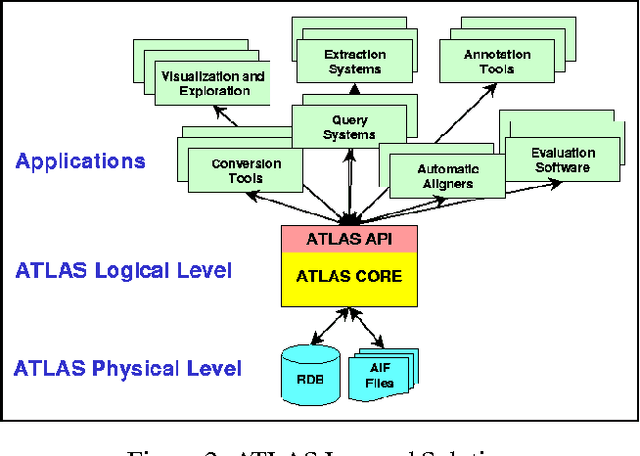
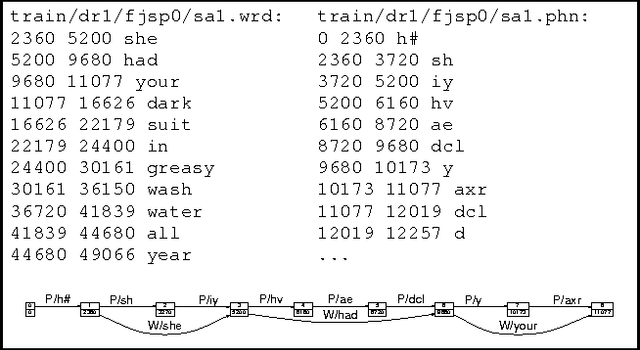
We describe a formal model for annotating linguistic artifacts, from which we derive an application programming interface (API) to a suite of tools for manipulating these annotations. The abstract logical model provides for a range of storage formats and promotes the reuse of tools that interact through this API. We focus first on ``Annotation Graphs,'' a graph model for annotations on linear signals (such as text and speech) indexed by intervals, for which efficient database storage and querying techniques are applicable. We note how a wide range of existing annotated corpora can be mapped to this annotation graph model. This model is then generalized to encompass a wider variety of linguistic ``signals,'' including both naturally occuring phenomena (as recorded in images, video, multi-modal interactions, etc.), as well as the derived resources that are increasingly important to the engineering of natural language processing systems (such as word lists, dictionaries, aligned bilingual corpora, etc.). We conclude with a review of the current efforts towards implementing key pieces of this architecture.
* 8 pages, 9 figures
Annotation graphs as a framework for multidimensional linguistic data analysis
Jul 05, 1999
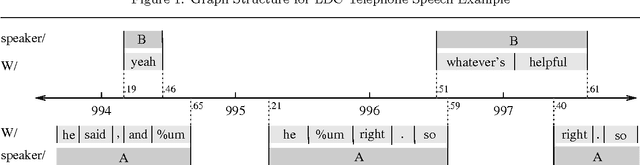


In recent work we have presented a formal framework for linguistic annotation based on labeled acyclic digraphs. These `annotation graphs' offer a simple yet powerful method for representing complex annotation structures incorporating hierarchy and overlap. Here, we motivate and illustrate our approach using discourse-level annotations of text and speech data drawn from the CALLHOME, COCONUT, MUC-7, DAMSL and TRAINS annotation schemes. With the help of domain specialists, we have constructed a hybrid multi-level annotation for a fragment of the Boston University Radio Speech Corpus which includes the following levels: segment, word, breath, ToBI, Tilt, Treebank, coreference and named entity. We show how annotation graphs can represent hybrid multi-level structures which derive from a diverse set of file formats. We also show how the approach facilitates substantive comparison of multiple annotations of a single signal based on different theoretical models. The discussion shows how annotation graphs open the door to wide-ranging integration of tools, formats and corpora.
A Formal Framework for Linguistic Annotation
Mar 02, 1999`Linguistic annotation' covers any descriptive or analytic notations applied to raw language data. The basic data may be in the form of time functions -- audio, video and/or physiological recordings -- or it may be textual. The added notations may include transcriptions of all sorts (from phonetic features to discourse structures), part-of-speech and sense tagging, syntactic analysis, `named entity' identification, co-reference annotation, and so on. While there are several ongoing efforts to provide formats and tools for such annotations and to publish annotated linguistic databases, the lack of widely accepted standards is becoming a critical problem. Proposed standards, to the extent they exist, have focussed on file formats. This paper focuses instead on the logical structure of linguistic annotations. We survey a wide variety of existing annotation formats and demonstrate a common conceptual core, the annotation graph. This provides a formal framework for constructing, maintaining and searching linguistic annotations, while remaining consistent with many alternative data structures and file formats.