 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnotation graphs as a framework for multidimensional linguistic data analysis
Paper and Code

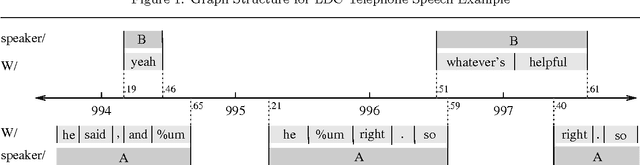


In recent work we have presented a formal framework for linguistic annotation based on labeled acyclic digraphs. These `annotation graphs' offer a simple yet powerful method for representing complex annotation structures incorporating hierarchy and overlap. Here, we motivate and illustrate our approach using discourse-level annotations of text and speech data drawn from the CALLHOME, COCONUT, MUC-7, DAMSL and TRAINS annotation schemes. With the help of domain specialists, we have constructed a hybrid multi-level annotation for a fragment of the Boston University Radio Speech Corpus which includes the following levels: segment, word, breath, ToBI, Tilt, Treebank, coreference and named entity. We show how annotation graphs can represent hybrid multi-level structures which derive from a diverse set of file formats. We also show how the approach facilitates substantive comparison of multiple annotations of a single signal based on different theoretical models. The discussion shows how annotation graphs open the door to wide-ranging integration of tools, formats and corpora.