 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Standard and Dialectal Frisian ASR: Multilingual Fine-tuning and Language Identification for Improved Low-resource Performance
Feb 07, 2025Automatic Speech Recognition (ASR) performance for low-resource languages is still far behind that of higher-resource languages such as English, due to a lack of sufficient labeled data. State-of-the-art methods deploy self-supervised transfer learning where a model pre-trained on large amounts of data is fine-tuned using little labeled data in a target low-resource language. In this paper, we present and examine a method for fine-tuning an SSL-based model in order to improve the performance for Frisian and its regional dialects (Clay Frisian, Wood Frisian, and South Frisian). We show that Frisian ASR performance can be improved by using multilingual (Frisian, Dutch, English and German) fine-tuning data and an auxiliary language identification task. In addition, our findings show that performance on dialectal speech suffers substantially, and, importantly, that this effect is moderated by the elicitation approach used to collect the dialectal data. Our findings also particularly suggest that relying solely on standard language data for ASR evaluation may underestimate real-world performance, particularly in languages with substantial dialectal variation.
DUMB: A Benchmark for Smart Evaluation of Dutch Models
May 22, 2023



We introduce the Dutch Model Benchmark: DUMB. The benchmark includes a diverse set of datasets for low-, medium- and high-resource tasks. The total set of eight tasks include three tasks that were previously not available in Dutch. Instead of relying on a mean score across tasks, we propose Relative Error Reduction (RER), which compares the DUMB performance of models to a strong baseline which can be referred to in the future even when assessing different sets of models. Through a comparison of 14 pre-trained models (mono- and multi-lingual, of varying sizes), we assess the internal consistency of the benchmark tasks, as well as the factors that likely enable high performance. Our results indicate that current Dutch monolingual models under-perform and suggest training larger Dutch models with other architectures and pre-training objectives. At present, the highest performance is achieved by DeBERTaV3 (large), XLM-R (large) and mDeBERTaV3 (base). In addition to highlighting best strategies for training larger Dutch models, DUMB will foster further research on Dutch. A public leaderboard is available at https://dumbench.nl.
Adapting Monolingual Models: Data can be Scarce when Language Similarity is High
May 22, 2021

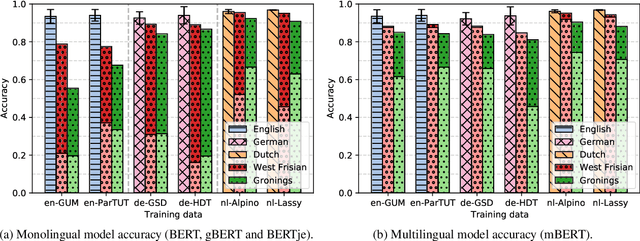
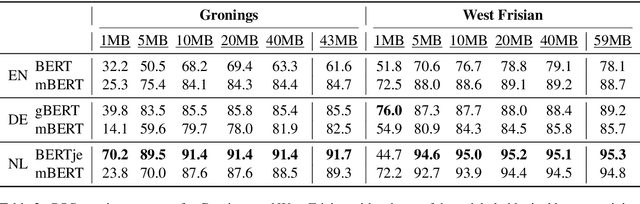
For many (minority) languages, the resources needed to train large models are not available. We investigate the performance of zero-shot transfer learning with as little data as possible, and the influence of language similarity in this process. We retrain the lexical layers of four BERT-based models using data from two low-resource target language varieties, while the Transformer layers are independently fine-tuned on a POS-tagging task in the model's source language. By combining the new lexical layers and fine-tuned Transformer layers, we achieve high task performance for both target languages. With high language similarity, 10MB of data appears sufficient to achieve substantial monolingual transfer performance. Monolingual BERT-based models generally achieve higher downstream task performance after retraining the lexical layer than multilingual BERT, even when the target language is included in the multilingual model.
As good as new. How to successfully recycle English GPT-2 to make models for other languages
Dec 10, 2020



Large generative language models have been very successful for English, but other languages lag behind due to data and computational limitations. We propose a method that may overcome these problems by adapting existing pre-trained language models to new languages. Specifically, we describe the adaptation of English GPT-2 to Italian and Dutch by retraining lexical embeddings without tuning the Transformer layers. As a result, we obtain lexical embeddings for Italian and Dutch that are aligned with the original English lexical embeddings and induce a bilingual lexicon from this alignment. Additionally, we show how to scale up complexity by transforming relearned lexical embeddings of GPT-2 small to the GPT-2 medium embedding space. This method minimises the amount of training and prevents losing information during adaptation that was learned by GPT-2. English GPT-2 models with relearned lexical embeddings can generate realistic sentences in Italian and Dutch, but on average these sentences are still identifiable as artificial by humans. Based on perplexity scores and human judgements, we find that generated sentences become more realistic with some additional full model finetuning, especially for Dutch. For Italian, we see that they are evaluated on par with sentences generated by a GPT-2 model fully trained from scratch. Our work can be conceived as a blueprint for training GPT-2s for other languages, and we provide a 'recipe' to do so.
Neural Representations for Modeling Variation in English Speech
Nov 25, 2020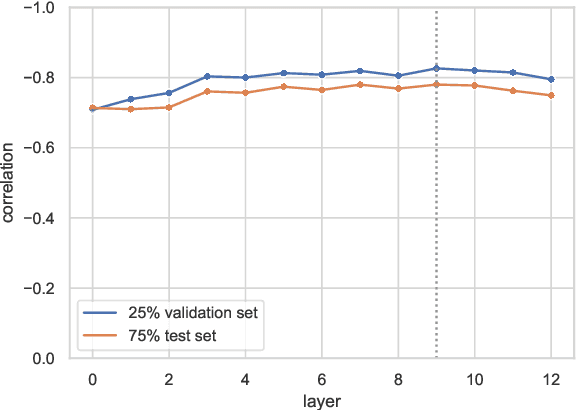
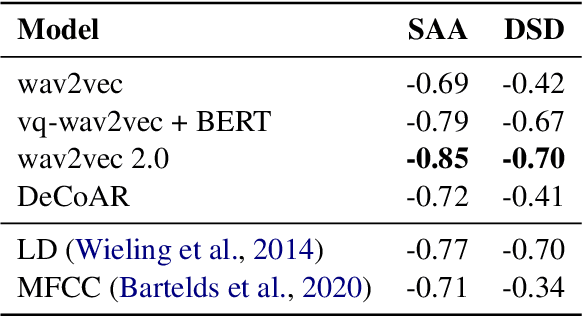
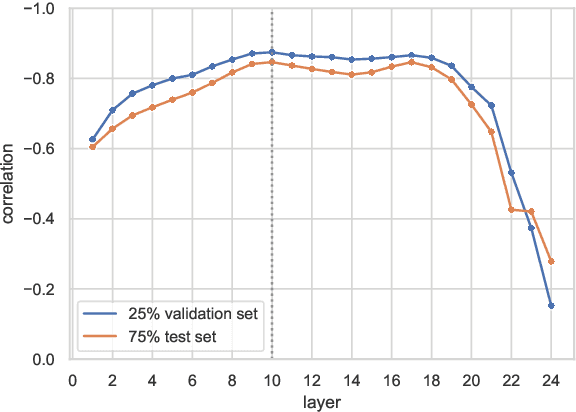
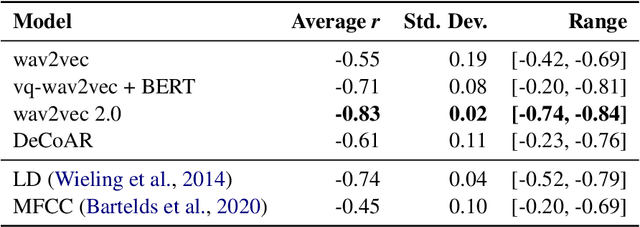
Variation in speech is often represented and investigated using phonetic transcriptions, but transcribing speech is time-consuming and error prone. To create reliable representations of speech independent from phonetic transcriptions, we investigate the extraction of acoustic embeddings from several self-supervised neural models. We use these representations to compute word-based pronunciation differences between non-native and native speakers of English, and evaluate these differences by comparing them with human native-likeness judgments. We show that Transformer-based speech representations lead to significant performance gains over the use of phonetic transcriptions, and find that feature-based use of Transformer models is most effective with one or more middle layers instead of the final layer. We also demonstrate that these neural speech representations not only capture segmental differences, but also intonational and durational differences that cannot be represented by a set of discrete symbols used in phonetic transcriptions.
What's so special about BERT's layers? A closer look at the NLP pipeline in monolingual and multilingual models
Apr 14, 2020
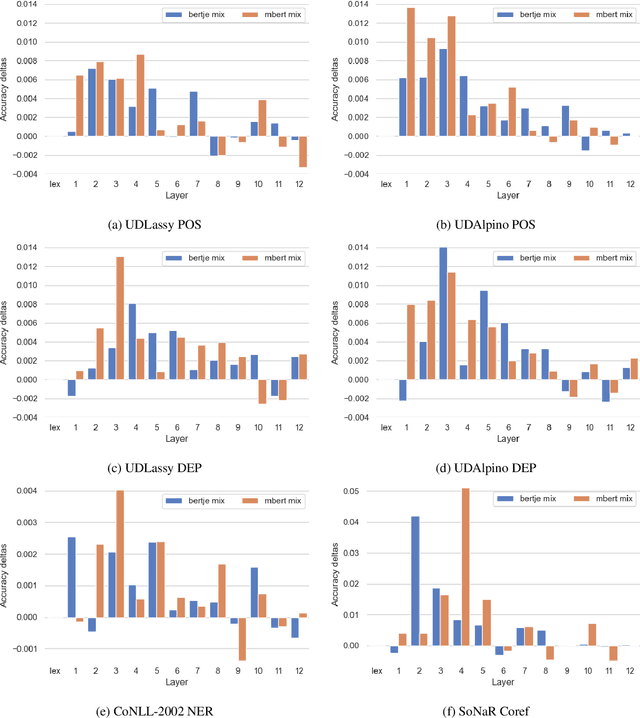

Experiments with transfer learning on pre-trained language models such as BERT have shown that the layers of these models resemble the classical NLP pipeline, with progressively more complex tasks being concentrated in later layers of the network. We investigate to what extent these results also hold for a language other than English. For this we probe a Dutch BERT-based model and the multilingual BERT model for Dutch NLP tasks. In addition, by considering the task of part-of-speech tagging in more detail, we show that also within a given task, information is spread over different parts of the network and the pipeline might not be as neat as it seems. Each layer has different specialisations and it is therefore useful to combine information from different layers for best results, instead of selecting a single layer based on the best overall performance.
BERTje: A Dutch BERT Model
Dec 19, 2019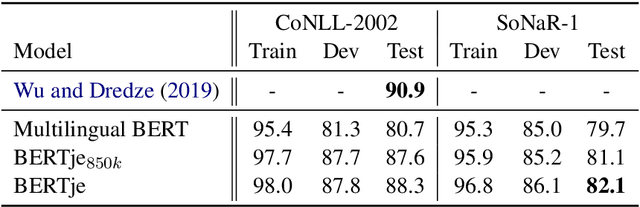
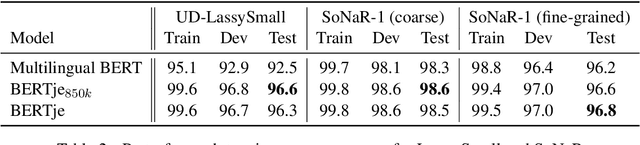


The transformer-based pre-trained language model BERT has helped to improve state-of-the-art performance on many natural language processing (NLP) tasks. Using the same architecture and parameters, we developed and evaluated a monolingual Dutch BERT model called BERTje. Compared to the multilingual BERT model, which includes Dutch but is only based on Wikipedia text, BERTje is based on a large and diverse dataset of 2.4 billion tokens. BERTje consistently outperforms the equally-sized multilingual BERT model on downstream NLP tasks (part-of-speech tagging, named-entity recognition, semantic role labeling, and sentiment analysis). Our pre-trained Dutch BERT model is made available at https://github.com/wietsedv/bertje.