 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse Materials Design by Large Language Model-Assisted Generative Framework
Feb 25, 2025Deep generative models hold great promise for inverse materials design, yet their efficiency and accuracy remain constrained by data scarcity and model architecture. Here, we introduce AlloyGAN, a closed-loop framework that integrates Large Language Model (LLM)-assisted text mining with Conditional Generative Adversarial Networks (CGANs) to enhance data diversity and improve inverse design. Taking alloy discovery as a case study, AlloyGAN systematically refines material candidates through iterative screening and experimental validation. For metallic glasses, the framework predicts thermodynamic properties with discrepancies of less than 8% from experiments, demonstrating its robustness. By bridging generative AI with domain knowledge and validation workflows, AlloyGAN offers a scalable approach to accelerate the discovery of materials with tailored properties, paving the way for broader applications in materials science.
Evaluating Standard and Dialectal Frisian ASR: Multilingual Fine-tuning and Language Identification for Improved Low-resource Performance
Feb 07, 2025



Automatic Speech Recognition (ASR) performance for low-resource languages is still far behind that of higher-resource languages such as English, due to a lack of sufficient labeled data. State-of-the-art methods deploy self-supervised transfer learning where a model pre-trained on large amounts of data is fine-tuned using little labeled data in a target low-resource language. In this paper, we present and examine a method for fine-tuning an SSL-based model in order to improve the performance for Frisian and its regional dialects (Clay Frisian, Wood Frisian, and South Frisian). We show that Frisian ASR performance can be improved by using multilingual (Frisian, Dutch, English and German) fine-tuning data and an auxiliary language identification task. In addition, our findings show that performance on dialectal speech suffers substantially, and, importantly, that this effect is moderated by the elicitation approach used to collect the dialectal data. Our findings also particularly suggest that relying solely on standard language data for ASR evaluation may underestimate real-world performance, particularly in languages with substantial dialectal variation.
An Overview of zbMATH Open Digital Library
Oct 09, 2024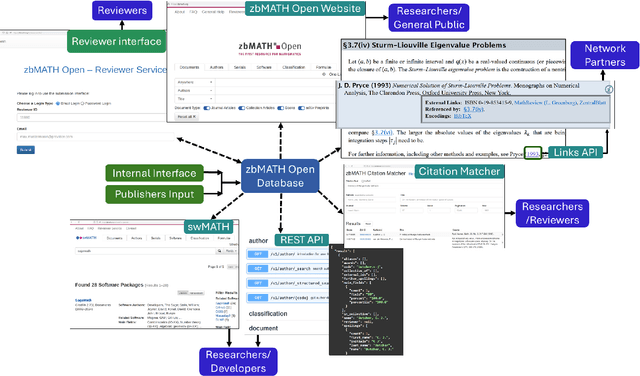
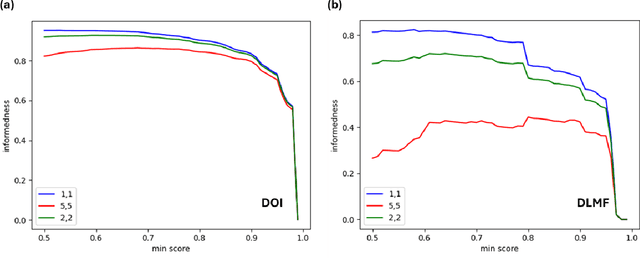
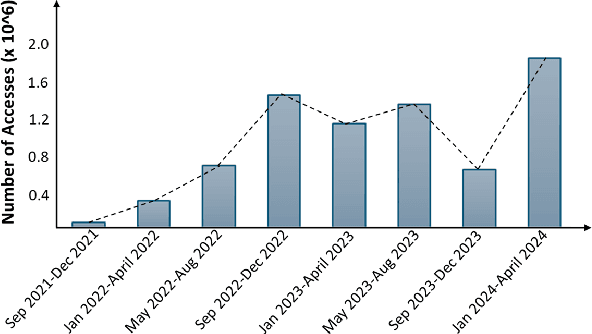
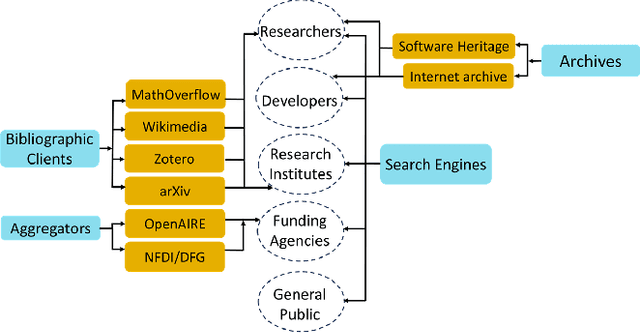
Mathematical research thrives on the effective dissemination and discovery of knowledge. zbMATH Open has emerged as a pivotal platform in this landscape, offering a comprehensive repository of mathematical literature. Beyond indexing and abstracting, it serves as a unified quality-assured infrastructure for finding, evaluating, and connecting mathematical information that advances mathematical research as well as interdisciplinary exploration. zbMATH Open enables scientific quality control by post-publication reviews and promotes connections between researchers, institutions, and research outputs. This paper represents the functionalities of the most significant features of this open-access service, highlighting its role in shaping the future of mathematical information retrieval.
Hybrid Classification-Regression Adaptive Loss for Dense Object Detection
Aug 30, 2024



For object detection detectors, enhancing model performance hinges on the ability to simultaneously consider inconsistencies across tasks and focus on difficult-to-train samples. Achieving this necessitates incorporating information from both the classification and regression tasks. However, prior work tends to either emphasize difficult-to-train samples within their respective tasks or simply compute classification scores with IoU, often leading to suboptimal model performance. In this paper, we propose a Hybrid Classification-Regression Adaptive Loss, termed as HCRAL. Specifically, we introduce the Residual of Classification and IoU (RCI) module for cross-task supervision, addressing task inconsistencies, and the Conditioning Factor (CF) to focus on difficult-to-train samples within each task. Furthermore, we introduce a new strategy named Expanded Adaptive Training Sample Selection (EATSS) to provide additional samples that exhibit classification and regression inconsistencies. To validate the effectiveness of the proposed method, we conduct extensive experiments on COCO test-dev. Experimental evaluations demonstrate the superiority of our approachs. Additionally, we designed experiments by separately combining the classification and regression loss with regular loss functions in popular one-stage models, demonstrating improved performance.