 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Denoising Using Only Single Noisy Audio Samples
Paper and Code
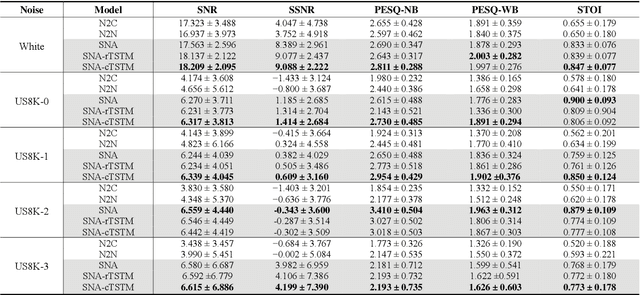
In this paper, we propose a novel Single Noisy Audio De-noising Framework (SNA-DF) for speech denoising using only single noisy audio samples, which overcomes the limi-tation of constructing either noisy-clean training pairs or multiple independent noisy audio samples. The proposed SNA-DF contains two modules: training audio pairs gener-ated module and audio denoising module. The first module adopts a random audio sub-sampler on single noisy audio samples for the generation of training audio pairs. The sub-sampled training audio pairs are then fed into the audio denoising module, which employs a deep complex U-Net incorporating a complex two-stage transformer (cTSTM) to extract both magnitude and phase information for taking full advantage of the complex features of single noisy au-dios. Experimental results show that the proposed SNA-DF not only eliminates the high dependence on clean targets of traditional audio denoising methods, but also outperforms the methods using multiple noisy audio samples.