 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLNSpeech: solving extended speech separation problem by the help of sign language
Paper and Code
Jul 21, 2020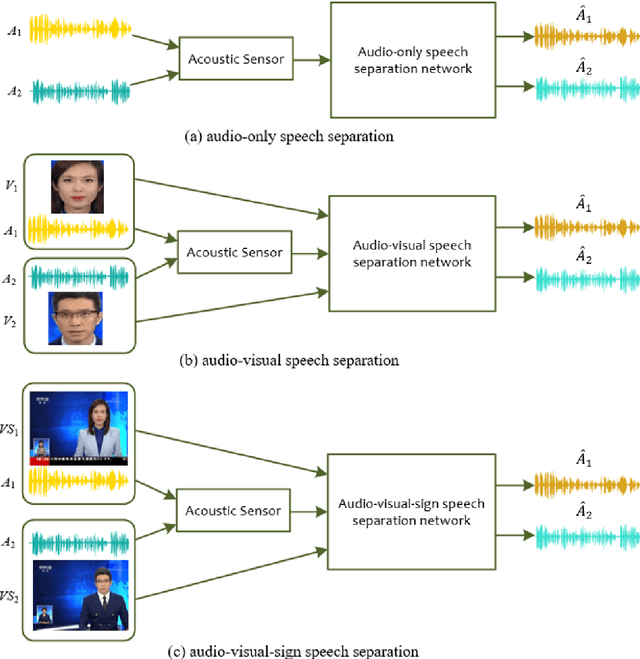


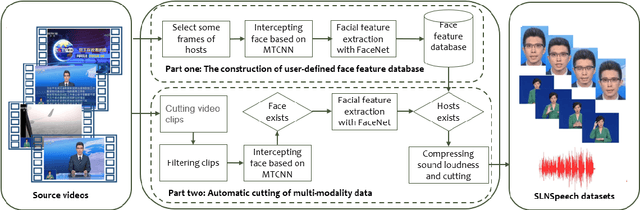
A speech separation task can be roughly divided into audio-only separation and audio-visual separation. In order to make speech separation technology applied in the real scenario of the disabled, this paper presents an extended speech separation problem which refers in particular to sign language assisted speech separation. However, most existing datasets for speech separation are audios and videos which contain audio and/or visual modalities. To address the extended speech separation problem, we introduce a large-scale dataset named Sign Language News Speech (SLNSpeech) dataset in which three modalities of audio, visual, and sign language are coexisted. Then, we design a general deep learning network for the self-supervised learning of three modalities, particularly, using sign language embeddings together with audio or audio-visual information for better solving the speech separation task. Specifically, we use 3D residual convolutional network to extract sign language features and use pretrained VGGNet model to exact visual features. After that, an improved U-Net with skip connections in feature extraction stage is applied for learning the embeddings among the mixed spectrogram transformed from source audios, the sign language features and visual features. Experiments results show that, besides visual modality, sign language modality can also be used alone to supervise speech separation task. Moreover, we also show the effectiveness of sign language assisted speech separation when the visual modality is disturbed. Source code will be released in http://cheertt.top/homepage/