 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExposing Deepfake Face Forgeries with Guided Residuals
Paper and Code
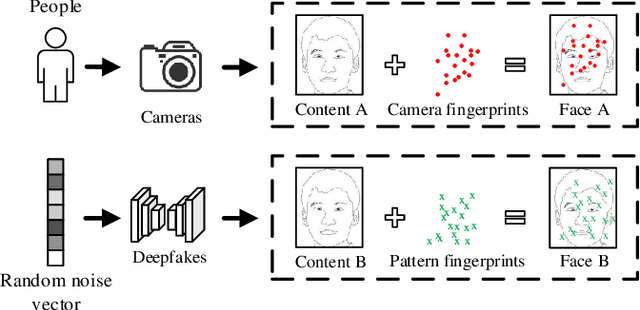
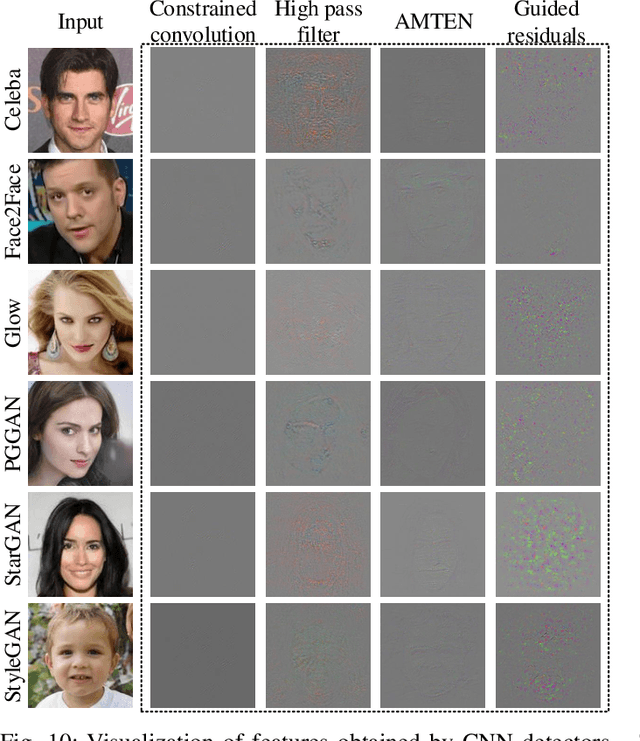

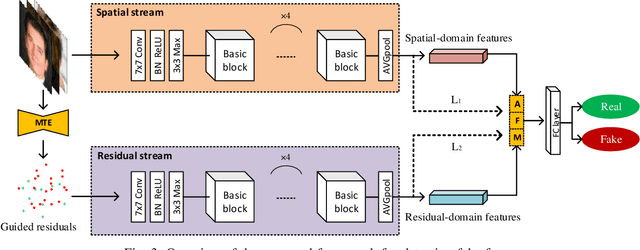
Residual-domain feature is very useful for Deepfake detection because it suppresses irrelevant content features and preserves key manipulation traces. However, inappropriate residual prediction will bring side effects on detection accuracy. In addition, residual-domain features are easily affected by image operations such as compression. Most existing works exploit either spatial-domain features or residual-domain features, while neglecting that two types of features are mutually correlated. In this paper, we propose a guided residuals network, namely GRnet, which fuses spatial-domain and residual-domain features in a mutually reinforcing way, to expose face images generated by Deepfake. Different from existing prediction based residual extraction methods, we propose a manipulation trace extractor (MTE) to directly remove the content features and preserve manipulation traces. MTE is a fine-grained method that can avoid the potential bias caused by inappropriate prediction. Moreover, an attention fusion mechanism (AFM) is designed to selectively emphasize feature channel maps and adaptively allocate the weights for two streams. The experimental results show that the proposed GRnet achieves better performances than the state-of-the-art works on four public fake face datasets including HFF, FaceForensics++, DFDC and Celeb-DF. Especially, GRnet achieves an average accuracy of 97.72% on the HFF dataset, which is at least 5.25% higher than the existing works.