 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Class-aware Semantic Enhancement Network for Audio-Visual Video Parsing
Dec 17, 2024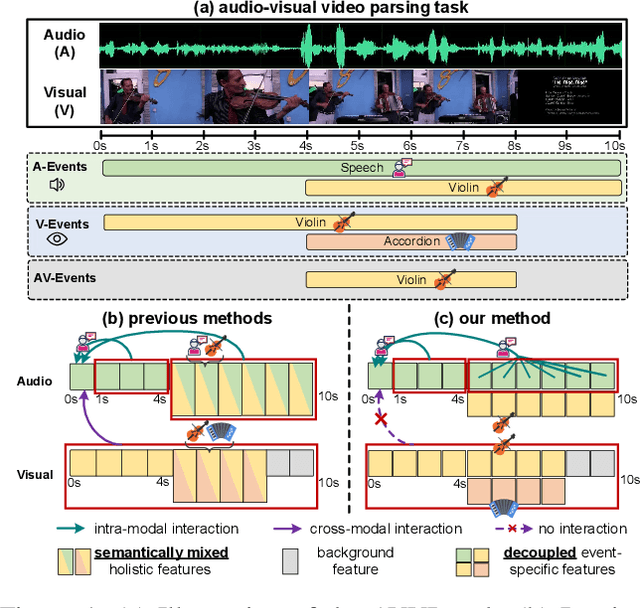
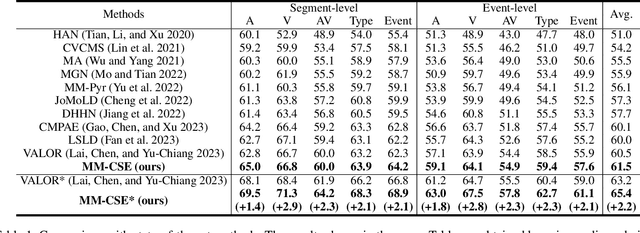
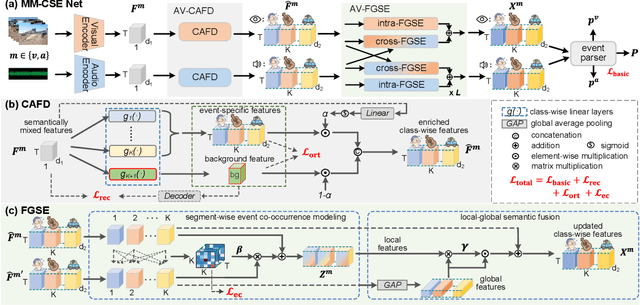
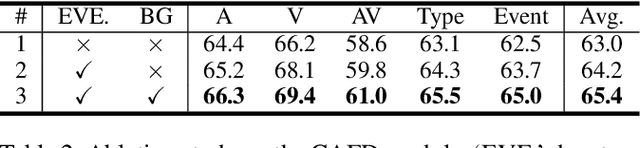
The Audio-Visual Video Parsing task aims to recognize and temporally localize all events occurring in either the audio or visual stream, or both. Capturing accurate event semantics for each audio/visual segment is vital. Prior works directly utilize the extracted holistic audio and visual features for intra- and cross-modal temporal interactions. However, each segment may contain multiple events, resulting in semantically mixed holistic features that can lead to semantic interference during intra- or cross-modal interactions: the event semantics of one segment may incorporate semantics of unrelated events from other segments. To address this issue, our method begins with a Class-Aware Feature Decoupling (CAFD) module, which explicitly decouples the semantically mixed features into distinct class-wise features, including multiple event-specific features and a dedicated background feature. The decoupled class-wise features enable our model to selectively aggregate useful semantics for each segment from clearly matched classes contained in other segments, preventing semantic interference from irrelevant classes. Specifically, we further design a Fine-Grained Semantic Enhancement module for encoding intra- and cross-modal relations. It comprises a Segment-wise Event Co-occurrence Modeling (SECM) block and a Local-Global Semantic Fusion (LGSF) block. The SECM exploits inter-class dependencies of concurrent events within the same timestamp with the aid of a new event co-occurrence loss. The LGSF further enhances the event semantics of each segment by incorporating relevant semantics from more informative global video features. Extensive experiments validate the effectiveness of the proposed modules and loss functions, resulting in a new state-of-the-art parsing performance.
Compressed Deepfake Video Detection Based on 3D Spatiotemporal Trajectories
Apr 28, 2024The misuse of deepfake technology by malicious actors poses a potential threat to nations, societies, and individuals. However, existing methods for detecting deepfakes primarily focus on uncompressed videos, such as noise characteristics, local textures, or frequency statistics. When applied to compressed videos, these methods experience a decrease in detection performance and are less suitable for real-world scenarios. In this paper, we propose a deepfake video detection method based on 3D spatiotemporal trajectories. Specifically, we utilize a robust 3D model to construct spatiotemporal motion features, integrating feature details from both 2D and 3D frames to mitigate the influence of large head rotation angles or insufficient lighting within frames. Furthermore, we separate facial expressions from head movements and design a sequential analysis method based on phase space motion trajectories to explore the feature differences between genuine and fake faces in deepfake videos. We conduct extensive experiments to validate the performance of our proposed method on several compressed deepfake benchmarks. The robustness of the well-designed features is verified by calculating the consistent distribution of facial landmarks before and after video compression.Our method yields satisfactory results and showcases its potential for practical applications.
Audio-Infused Automatic Image Colorization by Exploiting Audio Scene Semantics
Jan 24, 2024



Automatic image colorization is inherently an ill-posed problem with uncertainty, which requires an accurate semantic understanding of scenes to estimate reasonable colors for grayscale images. Although recent interaction-based methods have achieved impressive performance, it is still a very difficult task to infer realistic and accurate colors for automatic colorization. To reduce the difficulty of semantic understanding of grayscale scenes, this paper tries to utilize corresponding audio, which naturally contains extra semantic information about the same scene. Specifically, a novel audio-infused automatic image colorization (AIAIC) network is proposed, which consists of three stages. First, we take color image semantics as a bridge and pretrain a colorization network guided by color image semantics. Second, the natural co-occurrence of audio and video is utilized to learn the color semantic correlations between audio and visual scenes. Third, the implicit audio semantic representation is fed into the pretrained network to finally realize the audio-guided colorization. The whole process is trained in a self-supervised manner without human annotation. In addition, an audiovisual colorization dataset is established for training and testing. Experiments demonstrate that audio guidance can effectively improve the performance of automatic colorization, especially for some scenes that are difficult to understand only from visual modality.