 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAFM: Retrieval-Augmented Flow Matching for Unpaired CBCT-to-CT Translation
Feb 28, 2026Cone-beam CT (CBCT) is routinely acquired in radiotherapy but suffers from severe artifacts and unreliable Hounsfield Unit (HU) values, limiting its direct use for dose calculation. Synthetic CT (sCT) generation from CBCT is therefore an important task, yet paired CBCT--CT data are often unavailable or unreliable due to temporal gaps, anatomical variation, and registration errors. In this work, we introduce rectified flow (RF) into unpaired CBCT-to-CT translation in medical imaging. Although RF is theoretically compatible with unpaired learning through distribution-level coupling and deterministic transport, its practical effectiveness under small medical datasets and limited batch sizes remains underexplored. Direct application with random or batch-local pseudo pairing can produce unstable supervision due to semantically mismatched endpoint samples. To address this challenge, we propose Retrieval-Augmented Flow Matching (RAFM), which adapts RF to the medical setting by constructing retrieval-guided pseudo pairs using a frozen DINOv3 encoder and a global CT memory bank. This strategy improves empirical coupling quality and stabilizes unpaired flow-based training. Experiments on SynthRAD2023 under a strict subject-level true-unpaired protocol show that RAFM outperforms existing methods across FID, MAE, SSIM, PSNR, and SegScore. The code is available at https://github.com/HiLab-git/RAFM.git.
OpenPath: Open-Set Active Learning for Pathology Image Classification via Pre-trained Vision-Language Models
Jun 18, 2025Pathology image classification plays a crucial role in accurate medical diagnosis and treatment planning. Training high-performance models for this task typically requires large-scale annotated datasets, which are both expensive and time-consuming to acquire. Active Learning (AL) offers a solution by iteratively selecting the most informative samples for annotation, thereby reducing the labeling effort. However, most AL methods are designed under the assumption of a closed-set scenario, where all the unannotated images belong to target classes. In real-world clinical environments, the unlabeled pool often contains a substantial amount of Out-Of-Distribution (OOD) data, leading to low efficiency of annotation in traditional AL methods. Furthermore, most existing AL methods start with random selection in the first query round, leading to a significant waste of labeling costs in open-set scenarios. To address these challenges, we propose OpenPath, a novel open-set active learning approach for pathological image classification leveraging a pre-trained Vision-Language Model (VLM). In the first query, we propose task-specific prompts that combine target and relevant non-target class prompts to effectively select In-Distribution (ID) and informative samples from the unlabeled pool. In subsequent queries, Diverse Informative ID Sampling (DIS) that includes Prototype-based ID candidate Selection (PIS) and Entropy-Guided Stochastic Sampling (EGSS) is proposed to ensure both purity and informativeness in a query, avoiding the selection of OOD samples. Experiments on two public pathology image datasets show that OpenPath significantly enhances the model's performance due to its high purity of selected samples, and outperforms several state-of-the-art open-set AL methods. The code is available at \href{https://github.com/HiLab-git/OpenPath}{https://github.com/HiLab-git/OpenPath}..
VLM-CPL: Consensus Pseudo Labels from Vision-Language Models for Human Annotation-Free Pathological Image Classification
Mar 23, 2024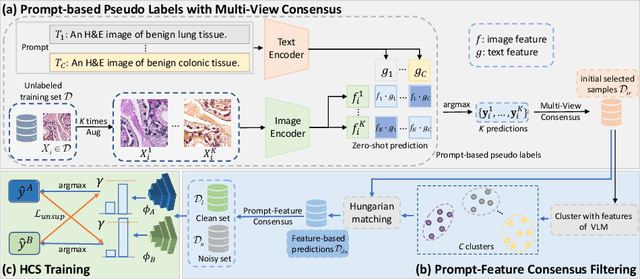
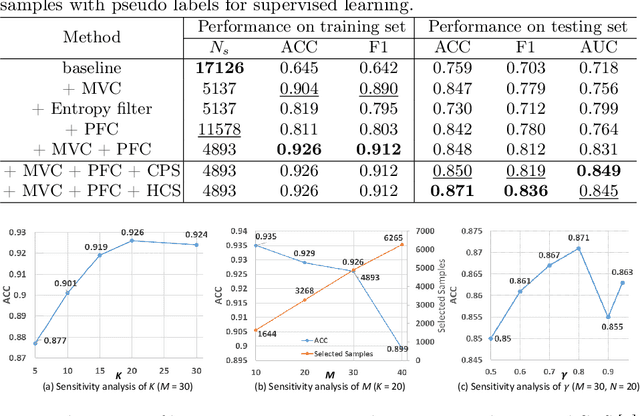
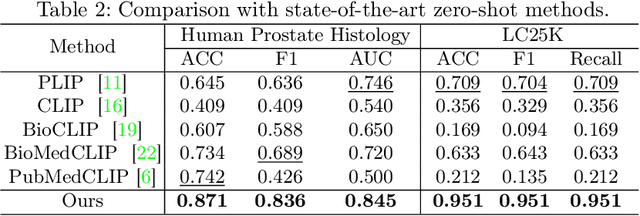
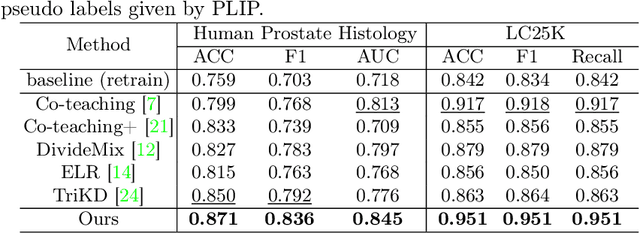
Despite that deep learning methods have achieved remarkable performance in pathology image classification, they heavily rely on labeled data, demanding extensive human annotation efforts. In this study, we present a novel human annotation-free method for pathology image classification by leveraging pre-trained Vision-Language Models (VLMs). Without human annotation, pseudo labels of the training set are obtained by utilizing the zero-shot inference capabilities of VLM, which may contain a lot of noise due to the domain shift between the pre-training data and the target dataset. To address this issue, we introduce VLM-CPL, a novel approach based on consensus pseudo labels that integrates two noisy label filtering techniques with a semi-supervised learning strategy. Specifically, we first obtain prompt-based pseudo labels with uncertainty estimation by zero-shot inference with the VLM using multiple augmented views of an input. Then, by leveraging the feature representation ability of VLM, we obtain feature-based pseudo labels via sample clustering in the feature space. Prompt-feature consensus is introduced to select reliable samples based on the consensus between the two types of pseudo labels. By rejecting low-quality pseudo labels, we further propose High-confidence Cross Supervision (HCS) to learn from samples with reliable pseudo labels and the remaining unlabeled samples. Experimental results showed that our method obtained an accuracy of 87.1% and 95.1% on the HPH and LC25K datasets, respectively, and it largely outperformed existing zero-shot classification and noisy label learning methods. The code is available at https://github.com/lanfz2000/VLM-CPL.
Semi-supervised Pathological Image Segmentation via Cross Distillation of Multiple Attentions
May 30, 2023Segmentation of pathological images is a crucial step for accurate cancer diagnosis. However, acquiring dense annotations of such images for training is labor-intensive and time-consuming. To address this issue, Semi-Supervised Learning (SSL) has the potential for reducing the annotation cost, but it is challenged by a large number of unlabeled training images. In this paper, we propose a novel SSL method based on Cross Distillation of Multiple Attentions (CDMA) to effectively leverage unlabeled images. Firstly, we propose a Multi-attention Tri-branch Network (MTNet) that consists of an encoder and a three-branch decoder, with each branch using a different attention mechanism that calibrates features in different aspects to generate diverse outputs. Secondly, we introduce Cross Decoder Knowledge Distillation (CDKD) between the three decoder branches, allowing them to learn from each other's soft labels to mitigate the negative impact of incorrect pseudo labels in training. Additionally, uncertainty minimization is applied to the average prediction of the three branches, which further regularizes predictions on unlabeled images and encourages inter-branch consistency. Our proposed CDMA was compared with eight state-of-the-art SSL methods on the public DigestPath dataset, and the experimental results showed that our method outperforms the other approaches under different annotation ratios. The code is available at \href{https://github.com/HiLab-git/CDMA}{https://github.com/HiLab-git/CDMA.}