 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Cloud Network Resilience via a Robust LLM-Empowered Multi-Agent Reinforcement Learning Framework
Jan 12, 2026While virtualization and resource pooling empower cloud networks with structural flexibility and elastic scalability, they inevitably expand the attack surface and challenge cyber resilience. Reinforcement Learning (RL)-based defense strategies have been developed to optimize resource deployment and isolation policies under adversarial conditions, aiming to enhance system resilience by maintaining and restoring network availability. However, existing approaches lack robustness as they require retraining to adapt to dynamic changes in network structure, node scale, attack strategies, and attack intensity. Furthermore, the lack of Human-in-the-Loop (HITL) support limits interpretability and flexibility. To address these limitations, we propose CyberOps-Bots, a hierarchical multi-agent reinforcement learning framework empowered by Large Language Models (LLMs). Inspired by MITRE ATT&CK's Tactics-Techniques model, CyberOps-Bots features a two-layer architecture: (1) An upper-level LLM agent with four modules--ReAct planning, IPDRR-based perception, long-short term memory, and action/tool integration--performs global awareness, human intent recognition, and tactical planning; (2) Lower-level RL agents, developed via heterogeneous separated pre-training, execute atomic defense actions within localized network regions. This synergy preserves LLM adaptability and interpretability while ensuring reliable RL execution. Experiments on real cloud datasets show that, compared to state-of-the-art algorithms, CyberOps-Bots maintains network availability 68.5% higher and achieves a 34.7% jumpstart performance gain when shifting the scenarios without retraining. To our knowledge, this is the first study to establish a robust LLM-RL framework with HITL support for cloud defense. We will release our framework to the community, facilitating the advancement of robust and autonomous defense in cloud networks.
A Content-Preserving Secure Linguistic Steganography
Nov 16, 2025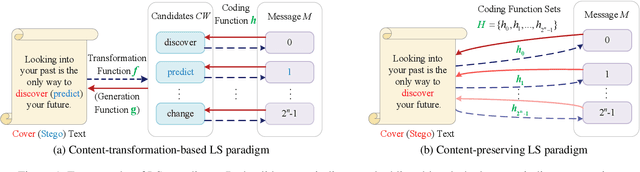
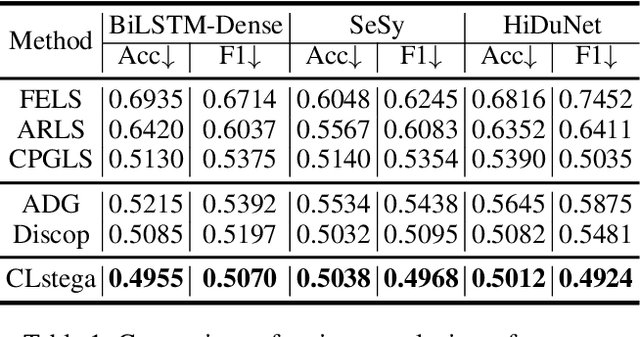
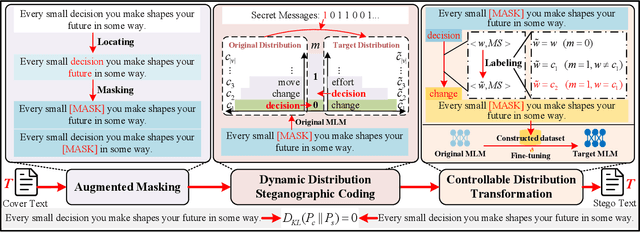
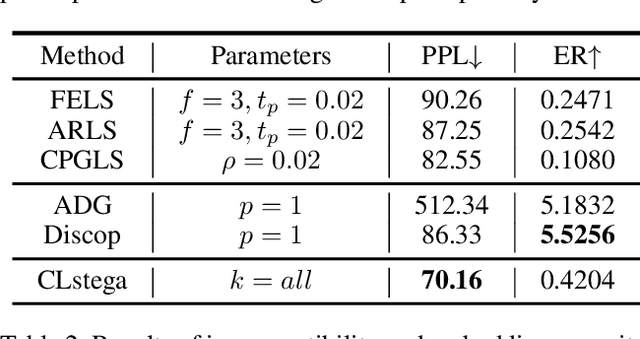
Existing linguistic steganography methods primarily rely on content transformations to conceal secret messages. However, they often cause subtle yet looking-innocent deviations between normal and stego texts, posing potential security risks in real-world applications. To address this challenge, we propose a content-preserving linguistic steganography paradigm for perfectly secure covert communication without modifying the cover text. Based on this paradigm, we introduce CLstega (\textit{C}ontent-preserving \textit{L}inguistic \textit{stega}nography), a novel method that embeds secret messages through controllable distribution transformation. CLstega first applies an augmented masking strategy to locate and mask embedding positions, where MLM(masked language model)-predicted probability distributions are easily adjustable for transformation. Subsequently, a dynamic distribution steganographic coding strategy is designed to encode secret messages by deriving target distributions from the original probability distributions. To achieve this transformation, CLstega elaborately selects target words for embedding positions as labels to construct a masked sentence dataset, which is used to fine-tune the original MLM, producing a target MLM capable of directly extracting secret messages from the cover text. This approach ensures perfect security of secret messages while fully preserving the integrity of the original cover text. Experimental results show that CLstega can achieve a 100\% extraction success rate, and outperforms existing methods in security, effectively balancing embedding capacity and security.
Are Watermarks Bugs for Deepfake Detectors? Rethinking Proactive Forensics
Apr 27, 2024



AI-generated content has accelerated the topic of media synthesis, particularly Deepfake, which can manipulate our portraits for positive or malicious purposes. Before releasing these threatening face images, one promising forensics solution is the injection of robust watermarks to track their own provenance. However, we argue that current watermarking models, originally devised for genuine images, may harm the deployed Deepfake detectors when directly applied to forged images, since the watermarks are prone to overlap with the forgery signals used for detection. To bridge this gap, we thus propose AdvMark, on behalf of proactive forensics, to exploit the adversarial vulnerability of passive detectors for good. Specifically, AdvMark serves as a plug-and-play procedure for fine-tuning any robust watermarking into adversarial watermarking, to enhance the forensic detectability of watermarked images; meanwhile, the watermarks can still be extracted for provenance tracking. Extensive experiments demonstrate the effectiveness of the proposed AdvMark, leveraging robust watermarking to fool Deepfake detectors, which can help improve the accuracy of downstream Deepfake detection without tuning the in-the-wild detectors. We believe this work will shed some light on the harmless proactive forensics against Deepfake.